
首页 > 代码库 > HTTP协议
HTTP协议
时间:2016-11-8 17:27
1、安装HttpWatch
HttpWatch是专门为IE浏览器提供的,用来查看HTTP请求和响应内容的工具,而FireFox中需要安装FireBug软件,如果使用的是Chrome,则自带该工具。
HttpWatch和FireBug这些工具对浏览器而言不是必须的,但是对开发者而言是很有必要的。
2、HTTP协议概述
HTTP(Hypertext Transport Protocol),即超文本传输协议,这个协议详细规定了浏览器和万维网服务器之间互相通信的规则。
HTTP就是一个通信规则,通信规则规定了客户端发送给服务器的内容格式,也规定了服务器发送给客户端的内容格式,其实我们要学习的就是这两个格式,客户端发送给服务器的格式叫请求协议,服务器发送给客户端的格式叫响应协议。
==========================================================
username=2222&password=3333
Content-Length:请求体的长度
当使用表单提交数据的时候,如果method为post,则请求行会改为post,如果表单内有数据,则会同时发送请求体:
username=2222&password=3333
也就是说,表单内种的所有内容,最终会使用一行字符串发送给服务器。
Content-Type: application/x-www-form-urlencoded,表示表单中的数据会自动使用URL来进行编码,如果编码格式不正确,并且在提交表单的时候包含了不匹配的字符(例如不支持中文的编码但是提交了中文字符),会出现以下情况:
username=%CE%CA%CE%CA&password=aaa
也就是乱码。
在服务器相应客户端时,如果响应的是文本:text/html,则后面必须加上文本编码:charset=ISO-8859-1
每个字节的范围是-128~127
URL编码处理方式:
1)先通过字符编码变成字节
2)首先让字节数+128
3)将字节转换为16进制
4)给每个字符添加%前缀
防止丢失字节。
超链接中如果出现中文,则不会进行URL编码。
——URL编码
URL编码平时是用不到的,因为IE会自动将输入到地址栏的非数字字母转换为url编码。曾有人提出数据库名字里带上“#”以防止被下载,因为IE遇到#就会忽略后面的字母。破解方法很简单——用url编码%23替换掉#。
方法仅仅只适用于设置post提交的requestboda的编码而不是设置get方法提交的queryString的编码。该方法告诉应用服务器应该采用什么编码解析post传过来的内容。
返回的结果是由Servlet服务器解码(decode)过的。
返回的字符串没有被Servlet服务器decoded过。
——Referer请求头
Referer请求头是比较有用的一个请求头,他可以用来做统计工作,也可以用来做防盗链。
统计工作:
我公司网站在百度上做了广告,但不知道在百度上做广告对我们网站的访问量是否有影响,那么可以对每个请求中的Referer进行分析,如果Referer链接百度居多,那么说明用户都是通过百度找到我们公司网站的。
防盗链:
我公司网站有一个下载链接,而其他网站盗链了这个地址,例如在我公司网站内download.html页面中有一个下载链接,点击即可下载JDK,但是有某人在微博中盗链了这个资源,它也有一个链接指向我们公司网站的下载地址,也就是说登录他的微博点击链接就可以下载我公司网站的资源,这导致我们网站的广告没有被访问,但是下载的却是我公司网站的资源,这时可以使用Referer进行防盗链操作,在资源被下载之前,我们对Referer进行判断,如果请求来自本网站,那么允许下载,否则先跳转到广告页,再下载。
4、响应协议
响应行(协议/版本 状态码 状态码的解析)
状态码以2开头全都代表响应成功。
以3开头代表全部需要转接。
以4开头全都代表客户端出错。
404代表客户端错误,表示访问了一个不存在的页面。
以5开头全都代表服务器的错误。
500代表服务器错误,也就是说代码出Exception了。
响应头(Key/Value格式)
空行
响应正文(响应体)
响应正文就是由服务器发送给浏览器的内容,浏览器会根据相应内容来显示。
Server:服务器名称。
Content-Type:相应内容的MIME类型。
Context-Type: text/html;charset=utf-8
表示该文件是文本类型,并且是格式为HTML的文本类型,编码格式是utf-8。(文本格式必须有编码)
Content-Length:该文本有多少字节。
Date:响应时间,可能会有八个小时的时区差。
其他响应头:
告诉浏览器不要缓存的响应头:
Exprires:-1(过期时间,-1代表马上过期)
Cache-Control:no-cache
Pragma:no-cache
(Cache-Control和Pragma兼容HTTP1.0和HTTP1.1两个版本)
自动刷新响应头,浏览器会在三秒之后请求http://www.baidu.com
Refresh:3;url=http://www.baidu.com
HTML中指定响应头:
在HTML页面中可以使用<meta http-equlv="" content="">来指定响应头,例如在index.html页面中给出<meta http-equlv="Refresh" content="3;url=http://www.baidu.com">,表示浏览器将会在显示index.html页面3秒之后自动跳转到http://www.baidu.com
其中<meta>标签可以指定响应头,http-equiv代表名(键),content代表值(值)。
<meta http-equiv="cache-control" content="no-cache" >
等价于:
cache-control:no-cache
响应码:
200:请求成功,浏览器会把响应体内容(通常是HTML)显示在浏览器中。
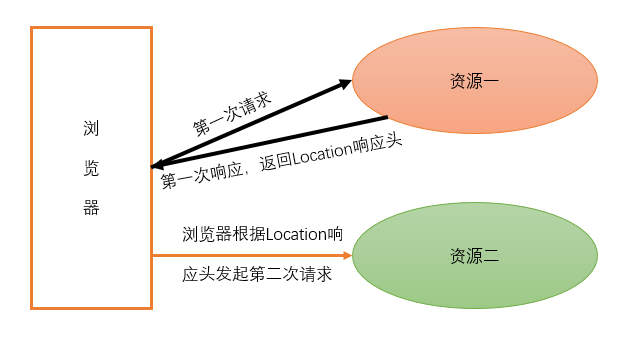
302:重定向,当响应码为302时,表示服务器要求浏览器重新再发送一个请求,服务器会发送一个响应头Location,它
指定了新请求的URL地址,此时浏览器接收响应体之后,会再次请求Location所指定的路径。
404:请求的资源没有找到,说明客户端请求了不存在的资源,通常是资源路径不对。
405:服务器不支持该请求。
500:请求资源找到了,但服务器内部出现了错误,通常是代码抛异常了。
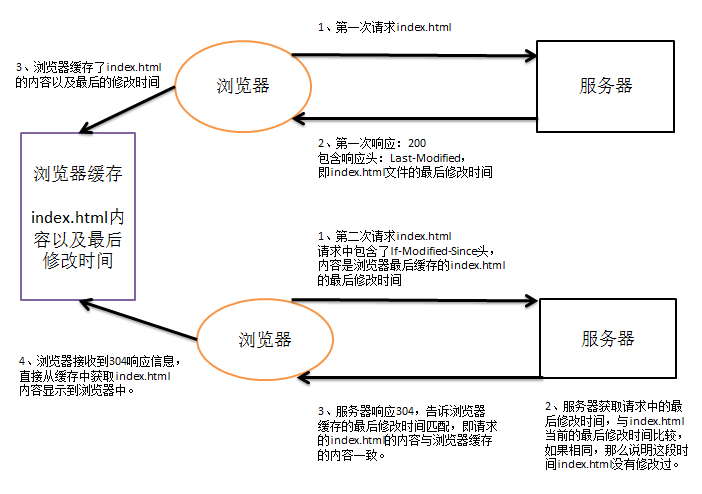
304:当用户第一次请求index.html时,服务器会添加一个名为Last-Modified的响应头,这个头说明了index.html的最后修改时间,浏览器会吧index.html的内容以及最后响应时间缓存下来,当用户第二次请求index.html时,在请求中会包含一个名为If-Modified-Since的请求头,它的值就是第一次请求时服务器通过Last-Modified响应头发送给浏览器的值,即index.html最后的修改时间,If-Modified-Since请求头就是在告诉服务器,我这里浏览器缓存的index.html最后修改时间是这个,你看看现在的index.html最后修改时间是不是这个,如果是,那么就不需要在响应新的index.html内容了,我会把缓存的内容直接显示出来。而服务器端会获取If-Modified-Since的值,与index.html的当前最后修改时间做对比,如果相同,服务器会发送响应码304,表示index.html与浏览器上次缓存的相同,无需再次发送相应内容,浏览器可以显示自己的缓存页面;如果对比不同,那么说明index.html已经做了修改,服务器会响应200。通常情况下只有静态页面才会有304,动态页面一般不做缓存。
Last-Modified:最后的修改时间。
If-Modified-Since:把上次请求的index.html的最后修改时间返还给服务器。
当Last-Modified与If-Modified-Since一致时,服务器会响应304,而不会响应正文。
重定向:
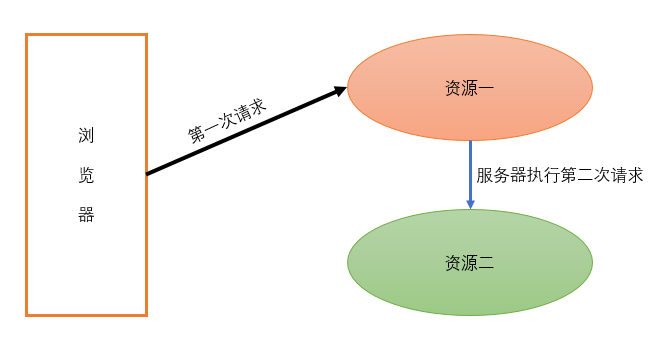
请求转发:
HTTP协议