
首页 > 代码库 > CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
2
2.1
2.2
2.3
2.4
2.5
2.6
2.7
2.8
2.9
2.9.1
2.9.2
2.9.2.1
2.9.2.2
2.9.3
2.9.3.1
2.9.3.2
2.9.3.3
2.9.3.4
2.9.3.5
3
4
5
5.1
5.2
5.3
6
7
7.1
7.2
8
8.1
8.2
8.3
8.4
8.5
8.6
8.7
8.8
8.9
8.10
8.11
8.12
8.13
8.14
8.15
8.16
8.16.1
8.17
8.18
8.19
8.19.1
8.19.2
8.20
8.20.1
8.20.2
8.20.2.1
8.20.2.2
8.20.2.3
8.20.2.4
8.20.3
8.20.4
8.21
8.22
8.22.1
8.22.2
8.22.3
8.22.4
9
10
10.1
10.2
11
12
12.1
12.2
13
14
15
16
本文档主要记录了
1 VM网络配置
将子网IP
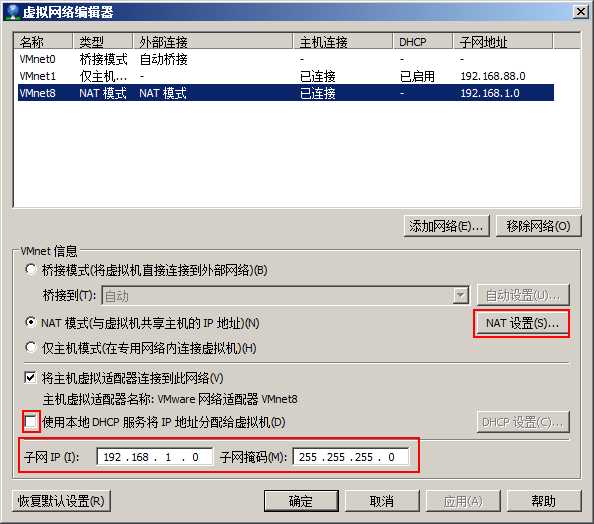
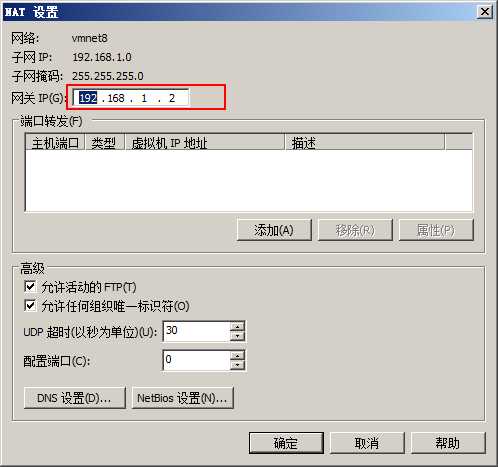
将网关设置为192.168.1.2
并禁止DHCP
当经过上面配置后,虚拟网卡
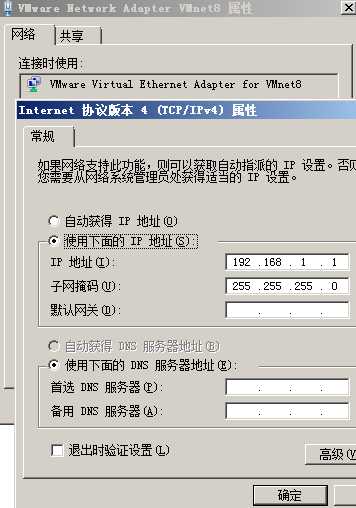
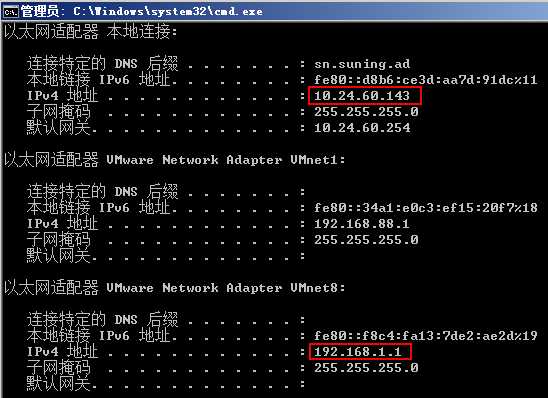
(虚拟机与物理机不在一个网段是没有关系的)
2 CentOS配置2.1 下载地址
http://mirrors.neusoft.edu.cn/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-1511.iso
下载不带桌面的最小安装版本
2.2 激活网卡
激活网卡,并设置相关
![]()

网关与DNS
2.3 SecureCRT
当网卡激活后,就可以使用

这里连接上后简单的进行下面设置:


2.4 修改主机名
/etc/sysconfig/network
![]()
/etc/hostname

/etc/hosts

192.168.1.11 node1
192.168.1.12 node2
192.168.1.13 node3
192.168.1.14 node4
2.5 yum代理上网
由于公司内部是代理上网,所以


yum代理的设置:

再次运行yum

2.6 安装ifconfig

2.7 wget安装与代理

安装好wget
[root@node1 ~]# vi /etc/wgetrc

http_proxy = http://10.19.110.55:8080
https_proxy = http://10.19.110.55:8080
ftp_proxy = http://10.19.110.55:8080
2.8 安装VMwareTools
为了虚拟机与主机时间同步,所以需要安装

[root@node1 opt]# yum -y install perl
[root@node1 ~]# mount /dev/cdrom /mnt
[root@node1 ~]# tar -zxvf/mnt/VMwareTools-9.6.1-1378637.tar.gz -C /root
[root@node1 ~]# umount /dev/cdrom
[root@node1 ~]# /root/vmware-tools-distrib/vmware-install.pl
[root@node1 ~]# rm -rf /root/vmware-tools-distrib
注:下面文件共享与鼠标拖放功能不要安装,否则安装过程会出问题:

[root@node1 ~]# chkconfig --list | grepvmware
vmware-tools 0:
vmware-tools-thinprint 0:
[root@node1 ~]# chkconfigvmware-tools-thinprint off
[root@node1 ~]# find / -name*vmware-tools-thinprint* | xargs rm -rf
2.9 其他
2.9.1 问题
刚启动时会出以下错误提示:

修改虚拟机配置文件
vcpu.hotadd = "FALSE"
mem.hotadd = "FALSE"
2.9.2 设置
2.9.2.1去掉开机等待时间
[root@node1 ~]# vim /etc/default/grub
GRUB_TIMEOUT=0 #
[root@node1 ~]# grub2-mkconfig -o/boot/grub2/grub.cfg
2.9.2.2VM调整

(注:小内存禁用)
修改node1.vmx
mainMem.useNamedFile = "FALSE"
为了全屏显示,方便命令行输入,做以下调整:

并去掉状态栏显示:

2.9.3 命令
2.9.3.1关机与重启
[root@node1 ~]# reboot
[root@node1 ~]# shutdown -h now
2.9.3.2服务停止与禁用
#查看开机自启动服务
[root@node1 ~]# systemctl list-unit-files| grep enabled | sort
auditd.service enabled
crond.service enabled
dbus-org.freedesktop.NetworkManager.serviceenabled
dbus-org.freedesktop.nm-dispatcher.service enabled
default.target enabled
dm-event.socket enabled
getty@.service enabled
irqbalance.service enabled
lvm2-lvmetad.socket enabled
lvm2-lvmpolld.socket enabled
lvm2-monitor.service enabled
microcode.service enabled
multi-user.target enabled
NetworkManager-dispatcher.service enabled
NetworkManager.service enabled
postfix.service enabled
remote-fs.target enabled
rsyslog.service enabled
sshd.service enabled
systemd-readahead-collect.service enabled
systemd-readahead-drop.service enabled
systemd-readahead-replay.service enabled
tuned.service enabled
[root@node1 ~]# systemctl | greprunning | sort
crond.service loaded active running Command Scheduler
dbus.service loaded active running D-Bus System Message Bus
dbus.socket loaded active running D-Bus System Message Bus Socket
getty@tty1.service loaded active running Getty on tty1
irqbalance.service loaded active running irqbalance daemon
lvm2-lvmetad.service loaded active running LVM2 metadata daemon
lvm2-lvmetad.socket loaded active running LVM2 metadata daemon socket
NetworkManager.service loaded active running Network Manager
polkit.service loaded active running Authorization Manager
postfix.service loaded active running Postfix Mail Transport Agent
rsyslog.service loaded active running System Logging Service
session-1.scope loaded active running Session 1 of user root
session-2.scope loaded activerunning Session 2 of user root
session-3.scope loaded active running Session 3 of user root
sshd.service loaded active running OpenSSH server daemon
systemd-journald.service loaded active running Journal Service
systemd-journald.socket loaded active running Journal Socket
systemd-logind.service loaded active running Login Service
systemd-udevd-control.socket loaded active running udev Control Socket
systemd-udevd-kernel.socket loaded active running udev Kernel Socket
systemd-udevd.service loaded active running udev Kernel Device Manager
tuned.service loaded active running Dynamic System Tuning Daemon
vmware-tools.service loaded active running SYSV: Manages the services needed to runVMware software
wpa_supplicant.service loaded active running WPA Supplicant daemon
#查看一个服务的状态
systemctl status auditd.service
#开机时启用一个服务
systemctl enable auditd.service
#开机时关闭一个服务
systemctl disable auditd.service
systemctl disablepostfix.service
systemctl disablersyslog.service
systemctl disablewpa_supplicant.service
#查看服务是否开机启动
systemctl is-enabled auditd.service
2.9.3.3查大文件目录
find . -type f -size +10M -print0 |xargs -0 du -h | sort -nr
将前最大的前20
du -hm --max-depth=5 / | sort -nr | head-20
find /etc -name ‘*srm*‘
2.9.3.4查看磁盘使用情况
[root@node1 dev]# df -h
文件系统 容量
/dev/mapper/centos-root 50G 1.5G 49G 3% /
devtmpfs 721M 0 721M 0% /dev
tmpfs 731M 0 731M 0% /dev/shm
tmpfs 731M 8.5M 723M 2% /run
tmpfs 731M 0 731M 0% /sys/fs/cgroup
/dev/mapper/centos-home 47G 33M 47G 1% /home
/dev/sda1 497M 106M 391M 22% /boot
tmpfs 147M 0 147M 0% /run/user/0
2.9.3.5查看内存使用情况
[root@node1 dev]# top

3 安装JDK
JDK所有旧版本在官网中的下载地址
在线下载jdk-8u72-linux-x64.tar.gz
wget -O
[root@node1~]# tar -zxvf /root/jdk-8u92-linux-x64.tar.gz -C /root
[root@node1 ~]# vi /etc/profile
在/etc/profile
export JAVA_HOME=/root/jdk1.8.0_92
export PATH=.:$PATH:$JAVA_HOME/bin
exportCLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[root@node1 ~]# source /etc/profile
[root@node1 ~]# java -version
java version "1.8.0_92"
Java(TM) SE Runtime Environment (build1.8.0_92-b14)
Java HotSpot(TM) 64-Bit Server VM (build25.92-b14, mixed mode)
使用env
[root@node1 ~]# env | grep CLASSPATH
CLASSPATH=.:/root/jdk1.8.0_92/jre/lib/rt.jar:/root/jdk1.8.0_92/lib/dt.jar:/root/jdk1.8.0_92/lib/tools.jar
4 复制虚拟机
前面只安装一台node1
| node1 | 192.168.1.11 |
| node2 | 192.168.1.12 |
| node3 | 192.168.1.13 |
| node4 | 192.168.1.14 |
修改相应虚拟机显示名:

开机时选择复制:



修改主机名:
[root@node1 ~]# vi /etc/sysconfig/network

[root@node1 ~]# vi /etc/hostname

5 SSH 免密码登录
RSA加密算法是一种典型的
RSA算法可以用于数据加密(
5.1 一般的ssh原理(需要密码)
客户端向服务器端发出连接请求
服务器端向客户端发出自己的公钥
客户端使用服务器端的公钥加密通讯登录密码然后发给服务器端
如果通讯过程被截获,由于窃听者即使获知公钥和经过公钥加密的内容,但不拥有私钥依然无法解密(
服务器端接收到密文后,用私钥解密,获知通讯密码
5.2 免密码原理
先在客户端创建一对密匙,并把公用密匙放在需要访问的服务器上
客户端向服务器发出请求,请求用你的密匙进行安全验证
服务器收到请求之后, 先在该服务器上你的主目录下寻找你的公用密匙,然后把它和你发送过来的公用密匙进行比较。如果两个密匙一致,服务器就用公用密匙加密“质询”(challenge
客户端收到“质询”之后就可以用自己的私人密匙解密再把它发送给服务器
服务器比较发来的“质询”和原先的是否一致,如果一致则进行授权,完成建立会话的操作
5.3 SSH免密码
先删除以前生成的:
rm -rf /root/.ssh
生成密钥:
[root@node1 ~]# ssh-keygen -t rsa
[root@node2 ~]# ssh-keygen -t rsa
[root@node3 ~]# ssh-keygen -t rsa
[root@node4 ~]# ssh-keygen -t rsa
命令“ssh-keygen-t rsa”表示使用 rsa
查看生成的密钥:

其中id_rsa.pub
服务器之间公钥拷贝:
ssh-copy-id
表示将本机的公钥拷贝到
[root@node1 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node1
[root@node1 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node2
[root@node1 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node3
[root@node1 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node4
[root@node2 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node1
[root@node2 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node2
[root@node2 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node3
[root@node2 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node4
[root@node3 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node1
[root@node3 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node2
[root@node3 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node3
[root@node3 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node4
[root@node4 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node1
[root@node4 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node2
[root@node4 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node3
[root@node4 ~]# ssh-copy-id -i/root/.ssh/id_rsa.pub node4
注:如果发现三台虚拟机上生成的公钥都是一个时,请先删除
6 HA+Federation服务器规划
|
|
| node1 | node2 | node3 | node4 |
| NameNode | Hadoop | Y(属于cluster1 | Y集群1) | Y(属于cluster2 | Y集群2) |
| DateNode |
| Y | Y | Y | |
| NodeManager |
| Y | Y | Y | |
| JournalNodes | Y | Y | Y |
| |
| zkfc(DFSZKFailoverController) | Y(有namenode的地方 | Y就有zkfc) | Y | Y | |
| ResourceManager | Y | Y |
|
| |
| ZooKeeper(QuorumPeerMain) | Zookeeper | Y | Y | Y |
|
| MySQL | HIVE |
|
|
| Y |
| metastore(RunJar) |
|
| Y |
| |
| HIVE(RunJar) | Y |
|
|
| |
| Scala | Spark | Y | Y | Y | Y |
| Spark-master | Y |
|
|
| |
| Spark-worker |
| Y | Y | Y |
不同的NameNode

NS-n单元:


7 zookeeper
[root@node1 ~]# wget -O /root/zookeeper-3.4.9.tar.gzhttps://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.tar.gz
[root@node1 ~]# tar -zxvf /root/zookeeper-3.4.9.tar.gz-C /root
[root@node1 conf]# cp/root/zookeeper-3.4.9/conf/zoo_sample.cfg /root/zookeeper-3.4.9/conf/zoo.cfg
[root@node1 conf]# vi /root/zookeeper-3.4.9/conf/zoo.cfg


[root@node1 conf]# mkdir/root/zookeeper-3.4.9/zkData
[root@node1 conf]# touch/root/zookeeper-3.4.9/zkData/myid
[root@node1 conf]# echo 1 >/root/zookeeper-3.4.9/zkData/myid
[root@node1 conf]# scp -r /root/zookeeper-3.4.9node2:/root
[root@node1 conf]# scp -r/root/zookeeper-3.4.9 node3:/root
[root@node2 conf]# echo 2 >/root/zookeeper-3.4.9/zkData/myid
[root@node3 conf]# echo 3 >/root/zookeeper-3.4.9/zkData/myid
7.1 超级权限
[root@node1 ~]# vi/root/zookeeper-3.4.9/bin/zkServer.sh
在下面启动Java

[root@node1 ~]#/root/zookeeper-3.4.9/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 11] addauthdigest super:AAAaaa111
现在就可以任意删除节点数据了:
[zk: localhost:2181(CONNECTED) 15] rmr/rmstore/ZKRMStateRoot
7.2 问题
zookeeper无法启动"Unable to loaddatabase on disk"
[root@node3 ~]# more zookeeper.out
2017-01-24 11:31:31,827 [myid:3] - ERROR[main:QuorumPeer@557] - Unable to load database on disk
java.io.IOException: The accepted epoch, dis less than the current epoch, 17
atorg.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:554)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:500)
atorg.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:153)
atorg.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
[root@node3 ~]# more/root/zookeeper-3.4.9/conf/zoo.cfg | grep dataDir
dataDir=/root/zookeeper-3.4.9/zkData
[root@node3 ~]# ls/root/zookeeper-3.4.9/zkData
myid version-2 zookeeper_server.pid
清空version-2
[root@node3 ~]# rm -f/root/zookeeper-3.4.9/zkData/version-2/*.*
[root@node3 ~]# rm -rf/root/zookeeper-3.4.9/zkData/version-2/acceptedEpoch
[root@node3 ~]# rm -rf/root/zookeeper-3.4.9/zkData/version-2/currentEpoch
8 Hadoop
[root@node1 ~]# wget -O /root/hadoop-2.7.2.tar.gz http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
[root@node1 ~]# tar -zxvf /root/hadoop-2.7.2.tar.gz-C /root
8.1 hadoop-env.sh
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/hadoop-env.sh

下面这个存放PID

8.2 hdfs-site.xml
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<description>
The default block size for new files, in bytes.
You can use the following suffix (case insensitive):
k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (suchas 128k, 512m, 1g, etc.),
Or provide complete size in bytes (such as 134217728 for 128 MB).
注:1.X
</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>注:
</property>
<property>
<name>dfs.nameservices</name>
<value>cluster1,cluster2</value>
<description>
</property>
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster2</name>
<value>nn3,nn4</value>
</property>
<!--
<property>
<name>dfs.namenode.rpc-address.cluster1.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster1.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster2.nn3</name>
<value>node3:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster2.nn4</name>
<value>node4:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster1.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster2.nn3</name>
<value>node3:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster3.nn4</name>
<value>node4:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/cluster1</value>
</property>
<!--
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/cluster2</value>
</property>
-->
<property>
</property>
<property>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster2</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>NameNode
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
</configuration>
8.3 core-site.xml
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1:8020</value>
<description>在使用客户端(或程序)时,如果不指定具体的接入地址?该值来自于
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.7.2/tmp</value>
<description>这里的路径默认是
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
<description>
</property>
<!-- 下面的配置可解决NameNode连接JournalNode超时异常问题
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates thenumber of milliseconds a client will wait for
before retrying toestablish a server connection.
</description>
</property>
</configuration>
8.4 slaves
指定DataNode
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/slaves

8.5 yarn-env.sh
[root@node1 ~]# vi/root/hadoop-2.7.2/etc/hadoop/yarn-env.sh

8.6 mapred-site.xml
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
<description>
</property>
</configuration>
8.7 yarn-site.xml
[root@node1 ~]# vi /root/hadoop-2.7.2/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn-cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<description>RM
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
<description>
</property>
</configuration>
8.8 复制与修改
[root@node1 ~]# scp -r /root/hadoop-2.7.2/node2:/root
[root@node1 ~]# scp -r /root/hadoop-2.7.2/node3:/root
[root@node1 ~]# scp -r /root/hadoop-2.7.2/node4:/root
[root@node3 ~]# vi /root/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
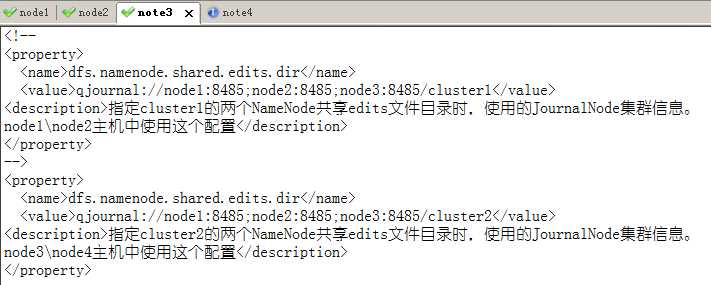
[root@node3 ~]# scp /root/hadoop-2.7.2/etc/hadoop/hdfs-site.xmlnode4:/root/hadoop-2.7.2/etc/hadoop
[root@node2 ~]# vi /root/hadoop-2.7.2/etc/hadoop/mapred-site.xml
[root@node3 ~]# vi /root/hadoop-2.7.2/etc/hadoop/mapred-site.xml
[root@node4 ~]# vi /root/hadoop-2.7.2/etc/hadoop/mapred-site.xml
[root@node2 ~]# vi /root/hadoop-2.7.2/etc/hadoop/yarn-site.xml
[root@node3 ~]# vi /root/hadoop-2.7.2/etc/hadoop/yarn-site.xml
[root@node4 ~]# vi /root/hadoop-2.7.2/etc/hadoop/yarn-site.xml
8.9 启动ZK
[root@node1 bin]#/root/zookeeper-3.4.9/bin/zkServer.sh start
[root@node2 bin]#/root/zookeeper-3.4.9/bin/zkServer.sh start
[root@node3 bin]#/root/zookeeper-3.4.9/bin/zkServer.sh start
[root@node1 bin]# jps
1622 QuorumPeerMain
查看状态:
[root@node1 ~]#/root/zookeeper-3.4.9/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config:/root/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
[root@node2 ~]#/root/zookeeper-3.4.9/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config:/root/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader
查看数据节点:
[root@node1 hadoop-2.7.2]#/root/zookeeper-3.4.9/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
8.10格式化zkfc
在每个集群上的任意一节点上进行操作,目的是在
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfszkfc -formatZK
[root@node3 ~]# /root/hadoop-2.7.2/bin/hdfszkfc -formatZK
格式化后,会在ZK
[root@node1 ~]#/root/zookeeper-3.4.9/bin/zkCli.sh

8.11启动journalnode
[root@node1 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart journalnode
[root@node2 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart journalnode
[root@node3 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart journalnode
[root@node1 ~]# jps
1810 JournalNode
8.12 namenode格式化和启动
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfsnamenode -format -clusterId CLUSTER_UUID_1
[root@node1 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart namenode
[root@node1 ~]# jps
1613 NameNode
同一集群中的所有集群


[root@node2 ~]#/root/hadoop-2.7.2/bin/hdfs namenode -bootstrapStandby
[root@node2 ~]#/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start namenode

[root@node3 ~]#/root/hadoop-2.7.2/bin/hdfs namenode -format -clusterId CLUSTER_UUID_1
[root@node3 ~]#/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start namenode

[root@node4 ~]#/root/hadoop-2.7.2/bin/hdfs namenode -bootstrapStandby
[root@node4 ~]#/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start namenode

8.13启动zkfc
ZKFC(
[root@node1 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart zkfc
[root@node2 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart zkfc
[root@node1 ~]# jps
5280 DFSZKFailoverController
自动切换成功:


[root@node3 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart zkfc
[root@node4 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart zkfc
8.14启动datanode
[root@node2 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart datanode
[root@node3 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart datanode
[root@node4 ~]# /root/hadoop-2.7.2/sbin/hadoop-daemon.shstart datanode
8.15HDFS验证
上传到指定的集群
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfsdfs -put /root/hadoop-2.7.2.tar.gz hdfs://cluster2/
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfsdfs -put /root/test_upload.tar hdfs://cluster1:8020/
上传时如果未明确指定路径,则会默认使用
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfsdfs -put /root/hadoop-2.7.2.tar.gz /
也可以具体到某台主机(但要是处于激活状态):
/root/hadoop-2.7.2/bin/hdfs dfs -put /root/hadoop-2.7.2.tarhdfs://node3:8020/
/root/hadoop-2.7.2/bin/hdfs dfs -put /root/hadoop-2.7.2.tarhdfs://node3/

8.16HA验证
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfshaadmin -ns cluster1 -getServiceState nn1
active
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfshaadmin -ns cluster1 -getServiceState nn2
standby
[root@node1 ~]# jps
2448 NameNode
3041 DFSZKFailoverController
3553 Jps
2647 JournalNode
2954 QuorumPeerMain
[root@node1 ~]# kill 2448
[root@node1 ~]# /root/hadoop-2.7.2/bin/hdfshaadmin -ns cluster1 -getServiceState nn2
active


8.16.1 手动切换
/root/hadoop-2.7.2/bin/hdfs haadmin -nscluster1 -failover nn2 nn1
/root/hadoop-2.7.2/bin/hdfs haadmin -nscluster2 -failover nn4 nn3
8.17启动yarn
[root@node1 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.shstart resourcemanager
[root@node2 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.shstart resourcemanager
[root@node2 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.shstart nodemanager
[root@node3 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.shstart nodemanager
[root@node4 ~]# /root/hadoop-2.7.2/sbin/yarn-daemon.shstart nodemanager
http://node1:8088/cluster/cluster
注:输入地址为

http://node2:8088/cluster/cluster

查看状态命令:
[root@node4 logs]# /root/hadoop-2.7.2/bin/yarnrmadmin -getServiceState rm2
8.18MapReduce测试
[root@node4 ~]# /root/hadoop-2.7.2/bin/hdfsdfs -mkdir hdfs://cluster1/hadoop
[root@node4 ~]# /root/hadoop-2.7.2/bin/hdfsdfs -put /root/hadoop-2.7.2/etc/hadoop/*xml* hdfs://cluster1/hadoop
[root@node4 ~]# /root/hadoop-2.7.2/bin/hadoopjar /root/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jarwordcount hdfs://cluster1:8020/hadoop/h* hdfs://cluster1:8020/hadoop/m*hdfs://cluster1/wordcountOutput
注:MapReduce
8.19脚本
以下脚本放在node1
8.19.1 启动与停用脚本
自动交互
在通过脚本进行RM
[root@node1 ~]# yum install expect
[root@node1 ~]# vi/root/starthadoop.sh
#rm -rf/root/hadoop-2.7.2/logs/*.*
#ssh root@node2 ‘exportBASH_ENV=/etc/profile;rm -rf /root/hadoop-2.7.2/logs/*.*‘
#ssh root@node3 ‘exportBASH_ENV=/etc/profile;rm -rf /root/hadoop-2.7.2/logs/*.*‘
#ssh root@node4 ‘exportBASH_ENV=/etc/profile;rm -rf /root/hadoop-2.7.2/logs/*.*‘
/root/zookeeper-3.4.9/bin/zkServer.shstart
ssh root@node2 ‘exportBASH_ENV=/etc/profile;/root/zookeeper-3.4.9/bin/zkServer.sh start‘
ssh root@node3 ‘exportBASH_ENV=/etc/profile;/root/zookeeper-3.4.9/bin/zkServer.sh start‘
/root/hadoop-2.7.2/sbin/start-all.sh
ssh root@node2 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/yarn-daemon.sh startresourcemanager‘
/root/hadoop-2.7.2/sbin/hadoop-daemon.shstart zkfc
ssh root@node2 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc‘
ssh root@node3 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc‘
ssh root@node4 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh start zkfc‘
#ret=`/root/hadoop-2.7.2/bin/hdfsdfsadmin -safemode get | grep ON | head -1`
#while [ -n"$ret" ]
#do
#echo ‘
#sleep 1s
#ret=`/root/hadoop-2.7.2/bin/hdfsdfsadmin -safemode get | grep ON | head -1`
#done
/root/hadoop-2.7.2/bin/hdfshaadmin -ns cluster1 -failover nn2 nn1
/root/hadoop-2.7.2/bin/hdfshaadmin -ns cluster2 -failover nn4 nn3
echo ‘Y‘ | sshroot@node1 ‘export BASH_ENV=/etc/profile;/root/hadoop-2.7.2/bin/yarn rmadmin-transitionToActive --forcemanual rm1‘
/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.shstart historyserver
ssh root@node2 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh starthistoryserver‘
ssh root@node3 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver‘
ssh root@node4 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh starthistoryserver‘
#
/root/spark-2.1.0-bin-hadoop2.7/sbin/start-all.sh
echo‘--------------node1---------------‘
jps | grep -v Jps |sort -k 2 -t ‘ ‘
echo‘--------------node2---------------‘
ssh root@node2"export PATH=/usr/bin:$PATH;jps | grep -v Jps | sort -k 2 -t ‘‘"
echo‘--------------node3---------------‘
ssh root@node3"export PATH=/usr/bin:$PATH;jps | grep -v Jps | sort -k 2 -t ‘‘"
echo‘--------------node4---------------‘
ssh root@node4"export PATH=/usr/bin:$PATH;jps | grep -v Jps | sort -k 2 -t ‘‘"
#
ssh root@node4 ‘exportBASH_ENV=/etc/profile;service mysql start‘
ssh root@node3 ‘exportBASH_ENV=/etc/profile;/root/hive-1.2.1/bin/hive --service metastore&‘
[root@node1~]# vi /root/stophadoop.sh
#
/root/spark-2.1.0-bin-hadoop2.7/sbin/stop-all.sh
#
ssh root@node4 ‘exportBASH_ENV=/etc/profile;service mysql stop‘
ssh root@node3 ‘exportBASH_ENV=/etc/profile;/root/jdk1.8.0_92/bin/jps | grep RunJar | head -1 |cut-f1 -d " "| xargs kill‘
ssh root@node2 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/yarn-daemon.sh stopresourcemanager‘
/root/hadoop-2.7.2/sbin/stop-all.sh
/root/hadoop-2.7.2/sbin/hadoop-daemon.shstop zkfc
ssh root@node2 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh stop zkfc‘
ssh root@node3 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh stop zkfc‘
ssh root@node4 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/hadoop-daemon.sh stop zkfc‘
/root/zookeeper-3.4.9/bin/zkServer.shstop
ssh root@node2 ‘exportBASH_ENV=/etc/profile;/root/zookeeper-3.4.9/bin/zkServer.sh stop‘
ssh root@node3 ‘exportBASH_ENV=/etc/profile;/root/zookeeper-3.4.9/bin/zkServer.sh stop‘
/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.shstop historyserver
ssh root@node2 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh stop historyserver‘
ssh root@node3 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh stophistoryserver‘
ssh root@node4 ‘exportBASH_ENV=/etc/profile;/root/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh stophistoryserver‘
[root@node1 ~]#chmod 777 starthadoop.sh stophadoop.sh
8.19.2 重启、关机
[root@node1 ~]# vi /root/reboot.sh
ssh root@node2"export PATH=/usr/bin:$PATH;reboot"
ssh root@node3"export PATH=/usr/bin:$PATH;reboot"
ssh root@node4"export PATH=/usr/bin:$PATH;reboot"
reboot
[root@node1 ~]# vi /root/shutdown.sh
ssh root@node2"export PATH=/usr/bin:$PATH;shutdown -h now"
ssh root@node3"export PATH=/usr/bin:$PATH;shutdown -h now"
ssh root@node4"export PATH=/usr/bin:$PATH;shutdown -h now"
shutdown -h now
[root@node1 ~]# chmod 777 /root/shutdown.sh/root/reboot.sh
8.20Eclipse插件
8.20.1 插件安装




- Map/Reduce(V2) Master :这个端口不用管,不影响任务远程提交与执行。如果配置正确,下面这个就可以在Eclips直接监视任务执行情况了(这个捣鼓了很久,还是没出来,在hadoop1.2.1倒是搞出来过):

- DFS Master: Name Node的IP和端口,hdfs-site.xml中dfs.namenode.rpc-address配置端口,这个配置决定了左边树是否可以连上Hadoop的dfs:

8.20.2 WordCount工程

8.20.2.1 WordCount.java
package
import
import
import
import
import
import
import
import
import
import
import
import
import
import
public
System.
+value);
StringTokenizeritr = newStringTokenizer(value.toString());
context.write(
}
}
}
sum+= val.get();
}
context.write(key,result);
System.
+sum);
}
}
Loggerlog = Logger.getLogger(WordCount.class
log.debug(
System.
Configurationconf = new Configuration();
conf.set(
conf.set(
conf.set(
conf.set(
conf.set(
Jobjob = Job.getInstance(conf, "wordcount"
job.setJarByClass(WordCount.
job.setMapperClass(TokenizerMapper.
job.setReducerClass(IntSumReducer.
job.setOutputKeyClass(Text.
job.setOutputValueClass(IntWritable.
FileInputFormat.addInputPath(job,new Path("hdfs://node1/hadoop/core-site.xml"
FileInputFormat.addInputPath(job,new Path("hdfs://node1/hadoop/m*"
FileSystemfs = FileSystem.get(URI.create("hdfs://node1"
fs.delete(
FileOutputFormat.setOutputPath(job,new Path("hdfs://node1/wordcountOutput"
System.exit(job.waitForCompletion(
System.
}
}
8.20.2.2 yarn-default.xml
注:工程中的yarn-default.xml

8.20.2.3 build.xml
<project
8.20.2.4 log4j.properties
log4j.rootLogger=
log4j.appender.stdout=
log4j.appender.stdout.layout=
log4j.appender.stdout.layout.ConversionPattern=
log4j.appender.R=
log4j.appender.R.File=
log4j.appender.R.MaxFileSize=
log4j.appender.R.MaxBackupIndex=
log4j.appender.R.layout=
log4j.appender.R.layout.ConversionPattern=
8.20.3 打包执行
打开工程中的build.xml
 包结构如下:
包结构如下:

然后打开工程中的


8.20.4 权限访问
运行时如果报以下异常:
Exception in thread"main" org.apache.hadoop.security.AccessControlException
atorg.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(
atorg.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(
atorg.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(
atorg.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(
atorg.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(
atorg.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(
atorg.apache.hadoop.hdfs.server.namenode.FSDirectory.checkOwner(
atorg.apache.hadoop.hdfs.server.namenode.FSDirAttrOp.setPermission(
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.setPermission(
atorg.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.setPermission(
atorg.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.setPermission(
atorg.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(
atorg.apache.hadoop.ipc.RPC$Server.call(RPC.java:969
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045
atjava.security.AccessController.doPrivileged(NativeMethod)
atjavax.security.auth.Subject.doAs(Subject.java:422
atorg.apache.hadoop.security.UserGroupInformation.doAs(
[root@node1 ~]#/root/hadoop-2.7.2/bin/hdfs dfs -chmod -R 777 /
8.21杀任务
如果发现任务提交后,停止不前,则可以杀掉该任务:
[root@node1 ~]#/root/hadoop-2.7.2/bin/hadoop job -list
[root@node1 ~]#/root/hadoop-2.7.2/bin/hadoop job -kill job_1475762778825_0008
8.22日志
8.22.1 Hadoop系统服务日志
如NameNode
http://node1:19888/logs/

这些日志实际上对应每台主机上的本地日志文件,进入相应主机可以看到原始文件:

当日志到达一定的大小将会被切割出一个新的文件,后面的数字越大,代表日志越旧。在默认情况下,只保存前20
*.out
http://node2:19888/logs/

http://node3:19888/logs/
http://node4:19888/logs/
也可以这样点进来:

8.22.2 Mapreduce日志
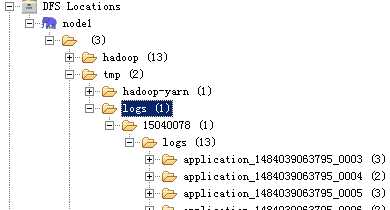
Mapreduce日志可以分为历史作业日志和Container日志。


注:这一类日志文件是放在
(
YARN提供了两种存放容器(
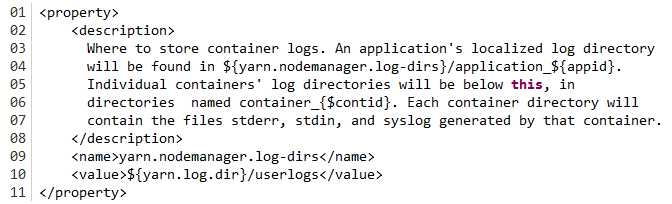
<property>
<description>Where to aggregate logs to.</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<property>
<description>The remote log dir will be created at{yarn.nodemanager.remote-app-log-dir}/${user}/{thisParam}
</description>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
默认情况下,这些日志信息是存放在
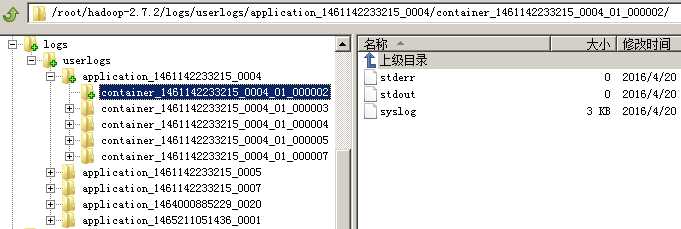
我们可以通过下面的配置进行修改:
2)
通过

点击相应链接可以查看到每个

8.22.3 System.out
JOB

如果作业提交到远程服务器上运行,在哪个节点(

如果是Map



这些日志还可以通过

8.22.4 log4j
在
作业提交代码(即


由于在log4j.properties

从输出来看,除了

提交到服务上运行时:此时的配置文件为
而
<property>
<name>mapreduce.map.log.level</name>
<value>INFO</value>
<description>The logging level for themap task. The allowed levels are:
OFF, FATAL, ERROR, WARN, INFO, DEBUG, TRACE andALL.
The setting here could be overridden if"mapreduce.job.log4j-properties-file"
is set.
</description>
</property>
<property>
<name>mapreduce.reduce.log.level</name>
<value>INFO</value>
<description>The logging level for thereduce task. The allowed levels are:
OFF, FATAL, ERROR, WARN, INFO, DEBUG, TRACE andALL.
The setting here could be overridden if"mapreduce.job.log4j-properties-file"
is set.
</description>
</property>
Map

注:
9 MySQL
[root@node4~]# wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
[root@node4~]# rpm -ivh mysql-community-release-el7-5.noarch.rpm
安装这个包后,会获得两个
[root@node4~]# yum install mysql-server
[root@node4/root]# service mysql start
[root@node4/root]# mysqladmin -u root password‘AAAaaa111‘
[root@node4/root]# mysql -h localhost -u root -p
Enterpassword: AAAaaa111
mysql> GRANT ALLPRIVILEGES ON *.* TO ‘root‘@‘%‘ IDENTIFIED BY ‘AAAaaa111‘ WITH GRANT OPTION;
mysql> flushprivileges;
mysql> show variables like ‘character%‘;

[root@node4/root]# vi /etc/my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character-set-server=utf8
不区分表名的大小写
[root@node4/root]# vi /etc/my.cnf
[mysqld]
lower_case_table_names = 1
其中
[root@node4/root]# service mysql stop
[root@node4/root]# service mysql start
mysql>show variables like ‘character%‘;

mysql> createdatabase hive;
mysql> showdatabases;
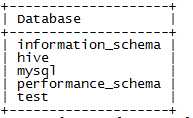
mysql> use hive;
10 HIVE安装10.1三种安装模式
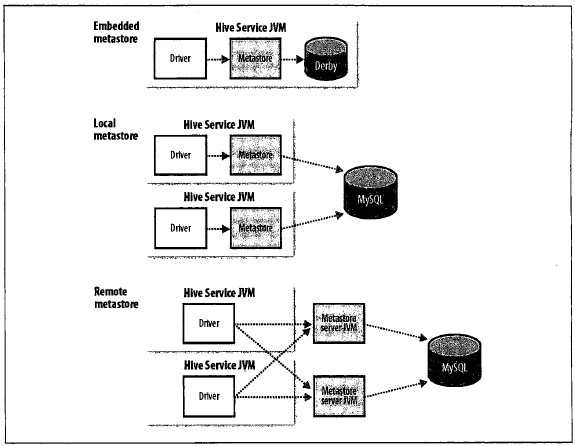
该模式无需特殊配置
2.中间是本地模式,特点是:
该模式只需将

该模式需要将hive.metastore.local
<name>hive.metastore.uris</name>
<value>thrift://127.0.0.1:9083</value>
</property>
把这些理解后,大家就会明白,其实仅连接
10.2远程模式安装
在node1
1、
Hadoop
[root@node1 ~]# wgethttp://apache.fayea.com/hive/stable/apache-hive-1.2.1-bin.tar.gz
2、
3、
4、
export HIVE_HOME=/root/hive-1.2.1
exportPATH=.:$PATH:$JAVA_HOME/bin:$HIVE_HOME/bin
5、
6、
7、
8、

经过上面这些操作后,应该可以启动
[root@node1 ~]# hive
Logging initialized using configuration injar:file:/root/hive-1.2.1/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive>
9、
10、
<property>
<name>hive.metastore.uris</name>
<value>thrift://
</property>
11、
12、
13、
[root@node1 ~]# hive --service hiveserver
[1] 3310
[root@hadoop-master /root]# jps
3310 RunJar
进程号名也是RunJar
注:不要使用 hive--service hiveserver 来启动服务,否则会抛异常:
Exception in thread"main" java.lang.ClassNotFoundException:org.apache.hadoop.hive.service.HiveServer
注
14、
15、
[root@node4/root]# mysql -h localhost -u root -p
16、

11 Scala安装
1、
2、
3、
export SCALA_HOME=/root/scala-2.12.1
exportPATH=.:$PATH:$JAVA_HOME/bin:$HIVE_HOME/bin:$SCALA_HOME/bin
4、
5、
Scala code runner version 2.12.1 --Copyright 2002-2016, LAMP/EPFL and Lightbend, Inc.
[root@node1 ~]# scala
Welcome to Scala 2.12.1 (Java HotSpot(TM)64-Bit Server VM, Java 1.8.0_92).
Type in expressions for evaluation. Or try:help.
scala> 9*9;
res0: Int = 81
scala>
6、
[root@node1 ~]#scp -r /root/scala-2.12.1 node3:/root
[root@node1 ~]#scp -r /root/scala-2.12.1 node4:/root
[root@node1 ~]#scp /etc/profile node2:/etc
[root@node1 ~]#scp /etc/profile node3:/etc
[root@node1 ~]#scp /etc/profile node4:/etc
[root@
[root@
[root@
12 Spark安装
1、
2、
3、
exportSPARK_HOME=/root/spark-2.1.0-bin-hadoop2.7
exportPATH=.:$PATH:$JAVA_HOME/bin:$HIVE_HOME/bin:$SCALA_HOME/bin:$
4、
5、
6、
exportSCALA_HOME=/root/scala-2.12.1
exportJAVA_HOME=//root/jdk1.8.0_92
exportHADOOP_CONF_DIR=/root/hadoop-2.7.2/etc/hadoop
7、
8、

7、
[root@node1 ~]#scp -r /root/spark-2.1.0-bin-hadoop2.7 node3:/root
[root@node1 ~]#scp -r /root/spark-2.1.0-bin-hadoop2.7 node4:/root
[root@node1 ~]#scp /etc/profile node2:/etc
[root@node1 ~]#scp /etc/profile node3:/etc
[root@node1 ~]#scp /etc/profile node4:/etc
[root@
[root@
[root@
8、

[root@node1 ~]# jps
2569 Master
[root@node2 ~]# jps
2120 Worker
[root@node3 ~]# jps
2121 Worker
[root@node4 ~]# jps
2198 Worker
12.1测试
直接在

valfile=sc.textFile("hdfs://node1/hadoop/core-site.xml")
val rdd =file.flatMap(line => line.split(" ")).map(word =>(word,1)).reduceByKey(_+_)
rdd.collect()
rdd.foreach(println)
使用
[root@node1 ~]# spark-submit --masterspark://node1:7077 --class org.apache.hadoop.examples.WordCount --namewordcount /root/hadoop-2.7.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jarhdfs://node1/hadoop/core-site.xml hdfs://node1/output
不过此种情况还是提交成
使用
spark-submit --master spark://node1:7077--class org.apache.spark.examples.JavaWordCount --name wordcount/root/spark-2.1.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.0.jarhdfs://node1/hadoop/core-site.xml hdfs://node1/output
该示例也是

12.2Hive启动问题
Hive在

[root@node1 ~]# vi/root/hive-1.2.1/bin/hive
#sparkAssemblyPath=`ls ${SPARK_HOME}/lib/spark-assembly-*.jar`
sparkAssemblyPath=`ls ${SPARK_HOME}/jars/*.jar`
[root@node1 ~]# scp /root/hive-1.2.1/bin/hivenode3:/root/hive-1.2.1/bin
13 清理与压缩
yum 会把下载的软件包和
[root@node1 ~]# yum clean all
[root@node1 ~]# dd if=/dev/zero of=/0bitsbs=20M //将碎片空间填充上0,结束的时候会提示磁盘空间不足,忽略即可
[root@node1 ~]# rm /0bits //删除上面的填充
关闭虚拟机,然后打开
vmware-vdiskmanager -k D:\hadoop\spark\VM\node1\node1.vmdk //注:这个vmdk
14 hadoop2.x常用端口
| 组件 | 节点 | 默认端口 | 配置 | 用途说明 |
| HDFS | DataNode | 50010 | dfs.datanode.address | datanode服务端口,用于数据传输 |
| HDFS | DataNode | 50075 | dfs.datanode.http.address | http服务的端口 |
| HDFS | DataNode | 50475 | dfs.datanode.https.address | https服务的端口 |
| HDFS | DataNode | 50020 | dfs.datanode.ipc.address | ipc服务的端口 |
| HDFS | NameNode | 50070 | dfs.namenode.http-address | http服务的端口 |
| HDFS | NameNode | 50470 | dfs.namenode.https-address | https服务的端口 |
| HDFS | NameNode | 8020 | fs.defaultFS | 接收Client连接的RPC端口,用于获取文件系统metadata信息。 |
| HDFS | journalnode | 8485 | dfs.journalnode.rpc-address | RPC服务 |
| HDFS | journalnode | 8480 | dfs.journalnode.http-address | HTTP服务 |
| HDFS | ZKFC | 8019 | dfs.ha.zkfc.port | ZooKeeper FailoverController,用于NN HA |
| YARN | ResourceManager | 8032 | yarn.resourcemanager.address | RM的applications manager(ASM)端口 |
| YARN | ResourceManager | 8030 | yarn.resourcemanager.scheduler.address | scheduler组件的IPC端口 |
| YARN | ResourceManager | 8031 | yarn.resourcemanager.resource-tracker.address | IPC |
| YARN | ResourceManager | 8033 | yarn.resourcemanager.admin.address | IPC |
| YARN | ResourceManager | 8088 | yarn.resourcemanager.webapp.address | http服务端口 |
| YARN | NodeManager | 8040 | yarn.nodemanager.localizer.address | localizer IPC |
| YARN | NodeManager | 8042 | yarn.nodemanager.webapp.address | http服务端口 |
| YARN | NodeManager | 8041 | yarn.nodemanager.address | NM中container manager的端口 |
| YARN | JobHistory Server | 10020 | mapreduce.jobhistory.address | IPC |
| YARN | JobHistory Server | 19888 | mapreduce.jobhistory.webapp.address | http服务端口 |
| HBase | Master | 60000 | hbase.master.port | IPC |
| HBase | Master | 60010 | hbase.master.info.port | http服务端口 |
| HBase | RegionServer | 60020 | hbase.regionserver.port | IPC |
| HBase | RegionServer | 60030 | hbase.regionserver.info.port | http服务端口 |
| HBase | HQuorumPeer | 2181 | hbase.zookeeper.property.clientPort | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| HBase | HQuorumPeer | 2888 | hbase.zookeeper.peerport | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| HBase | HQuorumPeer | 3888 | hbase.zookeeper.leaderport | HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| Hive | Metastore | 9083 | /etc/default/hive-metastore中export PORT=<port>来更新默认端口 |
|
| Hive | HiveServer | 10000 | /etc/hive/conf/hive-env.sh中export HIVE_SERVER2_THRIFT_PORT=<port>来更新默认端口 |
|
| ZooKeeper | Server | 2181 | /etc/zookeeper/conf/zoo.cfg中clientPort=<port> | 对客户端提供服务的端口 |
| ZooKeeper | Server | 2888 | /etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | follower用来连接到leader,只在leader上监听该端口。 |
| ZooKeeper | Server | 3888 | /etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 | 用于leader选举的。只在electionAlg是1,2或3(默认)时需要。 |
15 Linux命令
查超出10M
find . -type f -size +10M -print0 |xargs -0 du -h | sort -nr
将前最大的前20
du -hm --max-depth=5 / | sort -nr | head-20
find /etc -name ‘*srm*‘
清除YUM
yum
更改所有者
chown -R -v 15040078 /tmp
16 hadoop文件系统命令
[root@node1 ~/hadoop-2.6.0/bin]# ./hdfs dfs-chmod -R 700 /tmp
附件列表
CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装