
首页 > 代码库 > 气象业务数据格式的介绍
气象业务数据格式的介绍
气象业务数据格式的介绍
一.Net-CDF数据格式
1.1 Net-CDF概述
NetCDF全称为network Common Data Format,中文译法为“网络通用数据格式”,对程序员来说,它和zip、jpeg、bmp文件格式类似,都是一种文件格式的标准。netcdf文件开始的目的是用于存储气象科学中的数据,现在已经成为许多数据采集软件的生成文件的格式。
从数学上来说,netcdf存储的数据就是一个多自变量的单值函数。用公式来说f(x,y,z,...)=value, 函数的自变量x,y,z等在netcdf中叫做维(dimension)或坐标轴(axix),函数值value在netcdf中叫做变量(Variables).而自变量和函数值在物理学上的一些性质,比如计量单位(量纲)、物理学名称等等,在netcdf中就叫属性(Attributes).
1.2 Net-CDF的下载
netcdf的是官方网站为http://www.unidata.ucar.edu/software/netcdf/
在本文中,我们主要讨论在windows平台上使用netcdf软件库。我们将要从这个网站上
下载如下资源
⑴netcdf的源代码,目前的地址为
ftp://ftp.unidata.ucar.edu/pub/netcdf/netcdf-4/netcdf-beta.tar.gz
⑵netcdf的在windows平台预编译好的dll,地址为
ftp://ftp.unidata.ucar.edu/pub/netcdf/contrib/win32/netcdf-3.6.1-win32.zip
解压后里面有如下东西:
netcdf.dll 为编译好的dll
ncgen.exe 为生成netcdf文件的工具
ncdump.exe 为读取netcdf文件的工具
netcdf.lib 和 netcdf.exp在编程时会用到,后面会讲。
⑶netcdf的相关文档,包括
①netcdf的用户手册,下载地址为http://www.unidata.ucar.edu/software/netcdf/docs/netcdf.pdf
②netcdf的入门教程, 下载地址为
http://www.unidata.ucar.edu/software/netcdf/docs/netcdf-tutorial.pdf
③netcdf的c接口api手册,下载地址为http://www.unidata.ucar.edu/software/netcdf/docs/netcdf-c.pdf
下面我们来看netcdf文件的具体内容。
1.3 Net-CDF文件的内容
一个netcdf文件的结构包括以下对象:
变量(Variables)
变量对应着真实的物理数据。比如我们家里的电表,每个时刻显示的读数表示用户的到该时刻的耗电量。这个读数值就可以用netcdf里的变量来表示。它是一个以时间为自变量(或者说自变量个数为一维)的单值函数。再比如在气象学中要作出一个气压图,就是“东经xx度,北纬yy度的点的大气压值为多少帕”,这是一个二维单值函数,两维分别是经度和纬度。函数值为大气压。
从上面的例子可以看出,netcdf中的变量就是一个N维数组,数组的维数就是实际问题中的自变量个数,数组的值就是观测得到的物理值。变量(数组值)在netcdf中的存储类型有六种,ascii字符(char) ,字节(byte), 短整型(short), 整型(int), 浮点(float), 双精度(double). 显然这些类型和c中的类型一致,搞C的朋友应该很快就能明白。
2、维(dimension)
一个维对应着函数中的某个自变量,或者说函数图象中的一个坐标轴,在线性代数中就是一个N维向量的一个分量(这也是维这个名称的由来)。在netcdf中,一个维具有一个名字和范围(或者说长度,也就是数学上所说的定义域,可以是离散的点集合或者连续的区间)。在netcdf中,维的长度基本都是有限的,最多只能有一个具有无限长度的维。
3、属性(Attribute)
属性对变量值和维的具体物理含义的注释或者说解释。因为变量和维在netcdf中都只是无量纲的数字,要想让人们明白这些数字的具体含义,就得靠属性这个对象了。
在netcdf中,属性由一个属性名和一个属性值(一般为字符串)组成。比如,在某个cdl文件(cdl文件的具体格式在下一节中讲述)中有这样的代码段temperature:units = "celsius" ;
前面的temperature是一个已经定义好的变量(Variable),即温度,冒号后面的units就是属性名,表示物理单位,=后面的就是units这个属性的值,为“celsius” ,即摄氏度,整个一行代码的意思就是温度这个物理量的单位为celsius,很好理解。
1.4 CDL结构
CDL全称为network Common data form Description Language,它是用来描述netcdf文件
的结构的一种语法格式。它包括前面所说的三种netcdf对象(变量、维、属性)的具体定义。
看一个具体例子(这个例子cdl文件是从netcdf教程中的2.1 节The simple xy Example摘出来的):
netcdf simple_xy {
dimensions:
x = 6 ;
y = 12 ;
variables:
int data(x, y) ;
data:
data =
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47,
48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59,
60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71 ;
}
上面的代码定义了一个符合netcdf格式的结构simple_xy。
这个结构包括三个部分
1、维的定义,以dimensions:关键字开头
dimensions:x = 6 ;y = 12 ;
定义了两个轴(或者说两维),名字分别为x和y,x轴的长度(准确的说是坐标点的个数)为6, y轴的长度为12。
2、变量的定义:以variables:开头
variables:int data(x, y);
定义了一个以x轴和y轴为自变量的函数data,数学公式就是f(x,y)=data;
注意维出现的顺序是有序的,它决定data段中的具体赋值结果.
3、数据的定义,以data:开头
data:
data =
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11,
12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35,
36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47,
48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59,
60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71 ;
这个段数据用数学的函数公式f(x,y)=data来看,
x=0,y=0时,data = 0;
x=0,y=1时,data = 1;
x=5,y=11是,data=http://www.mamicode.com/71;
要注意的是:
1、赋值顺序:
我们给出的是c格式的cdl文件,因此这里的赋值顺序和c语言中的一致,也就是通常所说的“行式赋值”,而fortran语言中则是“列式赋值”,因此在fortran格式的cdl文件中,data段的数值顺序和这里正好行列互换。
2、自变量的默认取值和坐标变量
如果只给出维的长度,那么维的值默认从0开始,然后自动加1,到(长度-1)停止,很多情况下我们要自己给出每个点的坐标值,这时就需要用到netcdf里的坐标变量"coordinate varibles":增加一个和只和维相关的一元函数(自变量)并给出它的取值范围。
比如下面的cdl文件(摘自netcdf教程中的2.2 The sfc pres temp Example)
netcdf sfc_pres_temp {
dimensions:
latitude = 6 ; //纬度轴
longitude = 12 ; //经度轴
variables:
float latitude(latitude) ; //坐标变量,存储具体纬度
latitude:units = "degrees_north" ;
float longitude(longitude) ; //坐标变量,存储具体纬度
longitude:units = "degrees_east" ;
float pressure(latitude, longitude) ; //某个点(经度和纬度的交点)的大气压值
pressure:units = "hPa" ; //大气压的单位为
float temperature(latitude, longitude) ; //某个点(经度和纬度的交点)的温度值
temperature:units = "celsius" ; //温度的单位为
data:
latitude = 25, 30, 35, 40, 45, 50 ;
longitude = -125, -120, -115, -110, -105, -100, -95, -90, -85, -80, -75, -70 ;
pressure =
900, 906, 912, 918, 924, 930, 936, 942, 948, 954, 960, 966,
901, 907, 913, 919, 925, 931, 937, 943, 949, 955, 961, 967,
902, 908, 914, 920, 926, 932, 938, 944, 950, 956, 962, 968,
903, 909, 915, 921, 927, 933, 939, 945, 951, 957, 963, 969,
904, 910, 916, 922, 928, 934, 940, 946, 952, 958, 964, 970,
905, 911, 917, 923, 929, 935, 941, 947, 953, 959, 965, 971 ;
temperature =
9, 10.5, 12, 13.5, 15, 16.5, 18, 19.5, 21, 22.5, 24, 25.5,
9.25, 10.75, 12.25, 13.75, 15.25, 16.75, 18.25, 19.75, 21.25, 22.75, 24.25, 25.75,
9.5, 11, 12.5, 14, 15.5, 17, 18.5, 20, 21.5, 23, 24.5, 26,
9.75, 11.25, 12.75, 14.25, 15.75, 17.25, 18.75, 20.25, 21.75, 23.25, 24.75,26.25,
10, 11.5, 13, 14.5, 16, 17.5, 19, 20.5, 22, 23.5, 25, 26.5,
10.25, 11.75, 13.25, 14.75, 16.25, 17.75, 19.25, 20.75, 22.25, 23.75,25.25
对于上面的数据,就是
latitude = 25,longitude = -125时,pressure = 900,temperature = 9;
latitude = 25,longitude = -120时,pressure = 906,temperature = 10.5;
以此类推。
1.5 Net-CDF文件的读写
“学以致用” ,前面讲的都是netcdf的基本知识,都是为了本节的核心问题——读写netcdf格式的文件做铺垫之用,下面我们就来看看如何建立一个netcdf格式文件,以及如何再读出它的内容。
1、在命令行下读写netcdf文件
⑴建立一个simple_xy.cdl文件,内容就是上一节“CDL结构”中的第一个例子。
⑵用ncgen.exe工具(下载地址见前面的第二节)建立netcdf文件
①将ncgen所在目录加到系统path变量中或者直接将ncgen.exe拷到simple_xy.cdl所在目录下
②执行ncgen -o simple_xy.nc simple_xy.cdl生成netcdf格式文件simple_xy.nc
⑶生成的simple_xy.nc是一个二进制文件,要想从这个文件中还原出数据信息,就要用ncdump工具
①将ncdump所在目录加到系统path变量中或者直接将ncdump.exe拷到simple_xy.nc所在目录下
②在命令行下执行ncdump simple_xy.nc,这时屏幕的输出和simple_xy.cdl内容完全一样。说明我们的文件读写操作都是正确的。
2、编程读写netcdf文件(C语言读写)
前面我们知道如何手工去建立和读取netcdf文件,下面我们来看看如何在程序中用代码实现netcdf文件的建立和分析。我的编程环境为win2000+vc6.0 并安装了vc sp6补丁包。例子代码选自netcdf教程中的2.1节The simple_xy Example
⑴将netcdf的源代码解压。我们将用到里面的libsrc/netcdf.h头文件
⑵在vc6中建立一个空的win32控制台项目.名字为SimpleXyWrite,这个项目用来建立netcdf文件
⑶把如下文件拷贝到项目目录中
①netcdf源代码中的libsrc/netcdf.h头文件
②netcdf源代码中的examples/C/simple_xy_wr.c文件,并改名为simple_xy_wr.cpp
③netcdf预编译包中的netcdf.dll文件和 netcdf.lib文件
⑷把netcdf.h文件和simple_xy_wr.cpp加入到项目的文件列表中
(具体菜单操作project->add to project->files)
⑸把netcdf.lib加入到项目的lib列表中
(具体菜单操作project->add to project->settings->Link->object/library modules)
⑹编译并运行这个项目,会在项目目录下生成一个simple_xy.nc文件,其内容和我们手工生成的文件内容完全一样。
simple_xy_wr.c文件是建立netcdf文件的c代码,而examples/C/simple_xy_rd.c文件则是分析netcdf文件的代码,读者可以用和刚才类似的步骤在vc6中编译这个文件。运行时把把刚才生成的simple_xy.nc拷贝到项目的目录下,如果文件格式没错误,会提示*** SUCCESS reading example file simple_xy.nc!然后退出。
3、用ncgen命令自动生成c代码:给定了simple_xy.cdl文件后,可以用
ncgen -c simple_xy.cdl
命令直接在屏幕上输出c代码.不过,这个办法只限于cdl的数据比较简单时才可以采用。对于真正的项目,是需要我们自己去编写代码的。
1.6关于Net-CDF的总结
总体来说,netcdf的核心内容就是通过cdl描述文法来建立一个netcdf格式文件。抓住了这一点,如果继续深入看netcdf的其他资料时,应该就没什么太大的难度了。
----------------- 资料来源:作者:laomai http://blog.csdn.net/laomai
二.Grib数据格式
2.1 Grib数据格式概述
GRIB码是世界气象组织(WMO)建议并通过的一种二进制比特流代码,它适用于表示数值天气分析和预报的格点场产品。GRIB码具有与计算机无关的特点,采用压缩数据表示形式,压缩率一般在50%以上,因而利用GRIB码能加快数据传输速度,减少存储空间,因为GRIB码是压缩的二进制代码。现行的GRIB 码版本有GRIB1 和GRIB2 两种格式,GRIB2较之GRIB1具有加大优点而被广泛使用。如:表示多维数据、模块性结构、支持多种压缩方式、IEEE标准浮点表示法等。
在现行气象业务中,所使用的气象资料编码主要有以下两种:字符编码和表格驱动码编码。字符编码简单直观,但是由于种类格式繁多复杂、适应性差,而且对于每一种资料格式都要有相应的编解码工作,且解码复杂、工作量大,不能很好地满足不断增长的气象数据格式的需求。表格驱动码具有较强的自我描述、灵活和扩展性、数据压缩功能、编解码程序的简化和可作为标准格式直接存档等特点,由于气象数据种类不断增多,对数量和质量的要求越来越高,而字符编码的局限性使得字符编码不能很好地满足这样的需求。世界气象组织(WMO) 建议逐渐由字符格式编码向表格驱动码编码进行过渡,并制定了过渡计划。WMO推荐使用的表格驱动编码为气象数据通用格式(BUFR :Binary Universal FoRm) 、用于数据表示和字符格式(CREX:Character Representation form for data EXchange) 和二进制格点加工数据( GRIB :GRIdded Binary) 。
2.2 GRIB1
2.2.1 GRIB1 编码格式
一份GRIB1 编码资料分为6 段:
0 段: 指示段
1 段: 产品定义段
2 段: (网格描述段)
3 段: (位图段)
4 段: 二进制数据段
5 段: 7777
代码的开始和结束分别在0 段和5 段,由4 个8 位组的国际电报字符5 号码GRIB 表示开始和7777 表示结束。0 段是指示段,还包含整个资料的长度和GRIB 码版本号。1 段是产品定义段,内容包含段长、编码的分析或预报产品的标识符。2 段网格描述段,是可选段,内容包含该段段长以及网格的几何形状。虽然该段是可选段, 但强烈要求GRIB1 资料都应编发该段。3 段位图段,也是可选段,内容包含段长和数据位图,每个格点一位,按照顺序存放,比特位的取值指明对应格点上的数据是否被省略(0 :省略;1 :未省略) 。4 段数据段内容包含段长和数据值。
2.2.2 模板概念
GRIB1 开始使用模板概念。模板是一个数据实体的标准格式的描述。在GRIB1 中,1 段和2 段使用了模板。1 段仅使用不变的一个标准模板,2 段可以选取描述网格类型的标准模板中的一个来使用。模板中元数据或参数的取值列在模板所指引的码表中。
2.2.3 GRIB1的缺陷
GRIB1 被广泛用于NWP 产品,或是WAFS 产品。但是ICAO(国际民用航空组织) 在使用GRIB1来分发WAFS 产品时遇到阻碍,因为GRIB1 在传输或存档某些产品时还有缺陷。
(1) 表示数据的局限性,这是由GRIB 1 的结构所决定的。在GRIB1 中只能使用一个产品定义模板和网格描述模板,所以它只允许传输在一个格点某一个层上的一个场。
(2) 缺乏对谱数据的支持和对图像的有限支持,GRIB1 这方面的不足关键是因为数据压缩方式
还比较少。GRIB1 仅支持对格点数据的简单压缩、二级压缩和对球谐函数的简单压缩、复杂压缩。
(3) 不能对一些新的产品进行处理,例如集合预报系统的产品、长期预报产品和气候预测产品,还有槽脊图,因为GRIB1 没有表示相应产品的模板。因此需要开发GRIB 的第2 个版本,经过几年的开发和两年的试验以及合法性测试,WMO 批准了GRIB2 作为WMO 的可操作的表驱码。
2.3 GRIB2
2.3.1 GRIB2编码格式
一份GRIB2 编码资料分为9 段:
0 段: 指示段 --0 段指示段包含GRIB、学科、GRIB 码版本号、资料长度;
1 段: 标识段 --1 段标识段内容包含段长、段号,应用于GRIB 资料中全部加工数据的特征;
2 段: (本地使用段) --2 段包含段长、段号,由编报中心附加的本地使用的信息;
3 段: 网格定义段 --3 段网格定义段含有段长、段号、网格面和面内数据的几何形状定义;
4 段: 产品定义段 --4 段产品定义段内容包括段长、段号、数据的性质描述;
5 段: 数据表示段 --5 段数据表示段内容有段长、段号、数据值表示法描述;
6 段: 位图段 --6 段位图段内容含有段长、段号,以及指示每个格点上的数据是否存在;
7 段: 数据段 --7 段数据段内容是段长、段号、数据值;
8 段: 7777 --8 段结束段只含有“7777”4 个字符。
2.3.2 GRIB2的优势
(1) 表示多维数据
GRIB2 能传输多个网格场数据,GRIB2 也能描述在时间和空间方面的多维网格数据。在GRIB2中若是3 段到7 段循环,即允许在一个GRIB2 资料中包含多个格点场、多个产品、多个参数数据(如果本地使用段需要定义,2 段到7 段也可循环) 。如果需要在同一个格点场传送多个产品参数,就可以重复4 段到7 段。
(2) 更具模块性的结构
GRIB2 广泛使用模板,3 段使用网格定义模板,4 段使用产品定义模板,5 段使用数据表示模板。网格定义模板包含等距圆柱面(正方形平面) 、墨托卡、极射赤面投影、兰伯特正形、高斯经纬度、球谐函数系数、空间观察的透视和正射、基于二十面体的三角形、赤道方位角的等距投影、在水平面上有相等间隔点的剖面、在水平面上有相等间隔点的槽脊图以及时间剖面等类型的网格。产品定义模板包含分析预报、单项集合预报、概率预报、导出预报、百分比预
报、雷达产品、卫星产品等产品类型。数据表示模板包含的内容在下文的(3) 中介绍。在GRIB2 中,模板、码表管理更清晰,他们都根据所在的段来进行编号,而且根据功能和方向的不同进行分离。这些丰富的模板使得GRIB2 可以对一些新的产品进行编码,例如集合预报系统的产品,长期预报、气候预测、集合海浪预报或者交通模型、剖面段和槽脊类型图。GRIB2 能够展现目前可用的新产品,而且为扩展和增加提供方便的途径。GRIB2 的结构比GRIB1 更加体现了模块化和面向对象性。GRIB2 更具灵活性和可扩展性。在GRIB2 中,当需要传输一个新的参数或者新的数据类型时,新的元素只需要添加到新的表中去,这样就充分体现了灵活性。无需开发新的软件,处理过程和流程是固定的,只要扩充表就可以,这使得当新产品或者新参数需要增加时软件维护更加容易,充分体现了可扩展性。
(3) 更多的压缩方式
GRIB2 提供更多的压缩方式,特别是对谱数据和图像数据的支持(体现在数据表示模板) ,包含格点数据的简单压缩、复杂压缩和空间差分压缩方式,还有谱数据的简单压缩方式和对球谐函数数据的复杂压缩。最重要的是还采用了图像压缩方式(JPEG2000 和 PNG 压缩算法,这两种数据表示模板到2006 年本文发稿时已经包含在正式文档中) 。这两种压缩算法不仅能够提供对图像数据的支持,例如雷达产品和卫星产品,而且其他格点数据也可以使用它们来对格点数据进行压缩,以获得理想的精度。
(4) IEEE 标准浮点表示法
在GRIB2 中有一些数值是采用了IEEE 标准浮点数表示法。单精度浮点数用4 个8 位组表示:seeeeeee emmmmmmm mmmmmmmm mmmmmmmm 其中:s 为符号位,0 为正,1 为负;e…e :有偏指数,用8 个比特表示;m…m:尾数,但不包含第1个比特位;其数值由表1 给出。

表1 IEEE浮点表示法
数的存储是从高序列的8位组开始,符号位是第1个8位组的第1位,尾数的低序列位是第4个8位组的最后一位(第8位)。
2.3.3 GRIB2 解码
在了解了GRIB2 资料的结构后,我们着手做了GRIB2 的解码工作,自行编写了解码软件,目前已能解开GRIB2 的示例文件,以后还需进一步完善。在做解码工作时,有几个重点的问题值得探讨。
(1) 对字节的处理
由于GRIB2 资料都是由一些8 位组(字节) 构成的,所以在解码获得数据时就是对这些8 位组字节的处理。
①根据长度不同:各段的属性值或者模板中的要素值有的占1 个字节,有的占2 个或4 个字节,甚
至占8 个字节,所以要根据该值所占的字节个数来分别处理,同时要注意所选用的数据类型的表示范围。
②根据正负不同:在GRIB2 资料中,有些值是负值,负值通过最高位置1 来表示。
③ IEEE 标准表示的浮点数、位图和数据段数据。对这两种数据的处理都要处理到字节中的位。对于IEEE 标准表示的浮点数,需要从4 字节中获得1 个比特的符号位,8 个比特的有偏指数以及23个比特的尾数。数据段每个压缩值所占的比特数在5 段的数据表示模板中表示,若所占的比特数不是8 的倍数,则也需要处理到字节中的位,而且需要按顺序取出每个压缩值的比特位然后得到相应的值。位图段中的位图如果编发的话则指示每个格点上的数据是否存在,每个格点对应一个比特,存在时比特值为1 ,不存在时比特值为0 。
(2) 对结构的处理
解码程序一定要能处理GRIB2 资料中27 段、37 段、47 段可以重复的情况。特别需要注意的是在重复的段序列中,应包含该序列的所有段,并按照上述段号循序排列,不重复的段在再定义之前一直有效。所以在循环出现的地方,需要正确定位数据段所对应的产品定义段和格点定义段。
(3) 使用图像压缩方式的GRIB2 资料的解码
如果GRIB2 资料采用的是图像压缩方式进行编码,因为压缩算法比较复杂,在编解码的时候就需要专门的软件包来对数据进行处理,例如JasPer。
2.4 小结
由于目前模板的数量比较大,在解码过程中如何管理模板以及必要的码表是值得探讨的问题。GRIB2 的编码工作也是下一步的工作计划。GRIB2包含的模板很丰富,如何准确地使用好这些模板,特别是一些新增模板,使其能发挥它的优越性,在业务中获得很好的应用是编码工作需要进一步探索和研究的内容。
三.HDF5 数据格式
3.1 HDF5简介
HDF(分层数据格式)是用于存储和分发科学数据的一种自我描述、多对象文件格式。HDF是由美国国家超级计算应用中心(NCSA)创建的,为了满足各种领域研究需求而研制的一种能高效存储和分发科学数据的新型数据格式。该数据格式有别于以往常规资料所用到的二进制文件、ASCII文件,它提供了一种总体目录结构, 采用了二叉树的方式建立文件内容的“索引”,能够通过“索引”直接从嵌套的文件中快速获得信息,并且可以将不同类型的数据源存于一个文件中,同时这些数据源又可以同时包含其数据信息和其他相关信息。
3.2 HDF5的数据类型
HDF提供6种基本数据类型:光栅图像(Raster Image),调色板(Palette),科学数据集(Scientific Data Set),注解(Annotation),虚拟数据(Vdata)和虚拟组(Vgroup),这些数据结构,方便了我们对于信息的提取。例如,当我们打开一个HDF图像文件时,除了可以读取图像信息以外,还可以很容易的查取其地理定位,轨道参数,图像噪声等各种信息参数。HDF可以表示出科学数据存储和分布的许多必要条件。
HDF5是用于存储科学数据的一种文件格式和库文件。它被设计并实现满足科学数据存储不断增加和数据处理不断变化的需求,为了充分利用当今计算机系统的能力和特点,克服HDF4.x的不足。HDF5有一个强大和灵活的数据模块,支持管理的文件大于2GB(HDF4.x管理文件的极限),并且还支持并行I/O,设计时考虑了安全线程问题。
3.3 HDF5文件组织
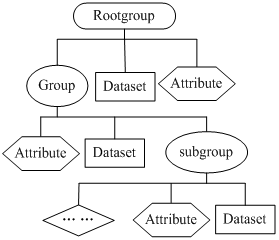
一个HDF5文件就是由两种基本数据对象(groups and datasets),分别是组(Group)和数据集(Dataset),同时有其它的辅助对象类型,即数据类型(Datatype)、数据空间(Dataspace)和数据属性(Attribute),存放多种科学数据的容器。其中,组可以看作一个容器,包含任意数量的其它组和数据集。在HDF5的逻辑结构里,整个文件作为一个Root组存在,所有内容均为Root组的成员。
HDF5 group:包含0个或者多个HDF5对象以及支持元数据(metadata)的一个群组结构。
HDF5 dataset:数据元素的一个多维数组以及支持元数据(metadata)。
任何HDF5的群组或数据集或许都有一个对应的属性列表。HDF5属性是一个用户自定义的HDF5结构,能为HDF5对象提供附加信息。使用群组和数据集时再许多方面类似于使用UNIX的目录和文件。HDF5文件里的对象经常通过他的绝对路径来引用。
3.4 HDF5文件逻辑结构
3.5 HDF的特性列表
(1)自述性:对于一个HDF文件里的每一个数据对象,有关于该数据的综合信息(元数据)。在没有任何外部信息的情况下,HDF允许应用程序解释HDF文件的结构和内容。
(2)通用性:许多数据类型都可以被嵌入在一个HDF文件里。例如,通过使用合适的HDF数据结构,符号、数字和图形数据可以同时存储在一个HDF文件里。
(3)灵活性:HDF允许用户把相关的数据对象组合在一起,放到一个分层结构中,向数据对象添加描述和标签。它还允许用户把科学数据放到多个HDF文件里。
(4)扩展性:HDF极易容纳将来新增加的数据模式,容易与其他标准格式兼容。
(5)跨平台性:HDF是一个与平台无关的文件格式。HDF文件无需任何转换就可以在不同平台上使用。
3.6 HDF/Net-CDF的局限
有效的分析大量科学数据常常需要一种方法来快速搜索并选择我们需要的部分数据基于特定搜索条件,但是针对HDF/Net-CDF文件格式,目前没有有效的查询机制来进行高效的查询,因此其本身的查询效率比较低。
关于Query的解决方案:使用Fast Query技术,由LBNL(美国劳伦斯伯克利国家实验室)组织提出并研发,基于FastBit Indexing Technology(位图快速索引技术)和PyTable的数据查询技术,底层采用的是Bitmap Index(位图索引)的数据结构。FastBit技术生成压缩位图索引,加快搜索HDF5数据集,可以把这些数据集放在一个HDF5文件中存储,与其他索引方案相比,压缩位图索引紧凑,非常适合查询多维数据甚至任意复杂的范围条件的组合。FastBit索引技术已经被供应商引入一些商业数据库系统例如Sybase,IBM和Oracle中,FastBit 也被整合到HDF5文件格式中,集成系统命名HDF5-FastQuery,但是目前还没有公开发行。
科学数据面临问题的解决方案:HDF5/Net-CDF + Fast Query可以解决以上问题。
Bitmap Index的数据结构:

四.NCEP/NCAR数据格式
4.1 NCEP简介
继美国环境预报中心(NCEP)和国家大气研究中心(NCAR)联合推出月平均再分析资料(1949-01)和日平均再分析资料(1958-01-01)后,最近又正式对外发布逐6h再分析资料集(1958-01-01T00),这为研究天气尺度和中尺度系统变化过程提供了良好的条件,并能为中尺度数值模式及区域气候模式提供初始场和侧边界条件。
该资料以netCDF(netware Common Data Form)的形式存储,通常可用COLA发展的自由软件GrADS或PMEL发展的可视化自由软件FERRET和RSI提供的商用软件包IDL进行操作处理,逐6h再分析资料集包括7个基本气象要素,根据变量名逐年生成独立文件。气温、位势高度、纬向风和经向风文件容量均为521Mb/a(17层);相对湿度和比湿文件容量均为245Mb/a(8层);垂自速度文件容量为367Mb/a(12层)。因此全部42年7要素逐6h再分析资料需要124Gb的介质存储,资料量极其庞大。中心近期已获得1969、1980、1991和1998年完整的资料集(注:这些年份是在近30年来长江流域4个降水正异常年份),它们分别存放在4个8mm磁带上和24个光盘上,其中98A表示1998年A盘即1998年气温,同样91A表示1991年A盘即1991年气温,依次类推.
4.2 NCEP再分析资料介绍
(1) 格点资料(GRIB格式)
数据内容:采用NCEP的实时格点资料,(1.0X1.0或2.5X2.5)网格,4月16日前的数据为16层,4月16日以后的数据为26层,主要的变量包括:TMP、HGT、UGRD、VGRD、RH、VVEL等。
文件名的组织方法:文件以gribyyyymmddhh格式来存放,其中yyyy为4位的年,mm为2位
的月,dd为2位的日期,hh为2位的时次。grib.big目录用来存放(1.0X1.0)网格数据wgrib目录用来存放(2.5X2.5)网格数据。
2)站点资料(BUFR格式)
数据内容:包括全球的地面,高空,卫星观测报
文件的组织方法:文件以bufryyyymmddhh格式来存放,其中yyyy为4位的年,mm为2位
的月,dd为2位的日期,hh为2位的时次wbufr目录用来存放台站数据。
很多在数据资料的一个网站http://www.cdc.noaa.gov/PublicData/ 对各种资料有比较详细的解释说明,也可以免费下载。http://dss.ucar.edu/datasets/ds083.2/从1999年到现在都有,需要先注册。大气所ftp的/data/backup/wgrib.big/下载。
气象业务数据格式的介绍