
首页 > 代码库 > 【译】每个JavaScript开发者都该懂的Unicode
【译】每个JavaScript开发者都该懂的Unicode
本文是我(兔子)在众成翻译上认领并翻译的:每个JavaScript开发者都该懂的Unicode
(译者注:本文含有Unicode辅助平面的特殊字符,部分浏览器可能无法正确显示,但并不影响理解文章内容。)
在动笔写这篇文章之前,我得先忏悔一下:在很长一段时间里我对Unicode充满了恐惧。
每次遇到需要Unicode知识的编程问题时,我总是找一个hack方案来解决,但解决方案的原理我也不懂。
直到遇见一个需要深入了解Unicode知识才能解决的问题,我才停止了这种逃避。因为这个问题没办法应用特定情境的解决方案。
在努力读了一大堆文章之后,我惊讶地发现Unicode并不难懂。好吧,确实是有些文章起码得看3遍才能看懂。
但我发现Unicode标准不仅世界通用,而且十分优雅简洁,只不过要理解其中一些抽象概念有点困难。
如果你觉得理解Unicode很难,那么是时候来面对它了!其实它没你想的那么难。去沏一杯香浓的茶或咖啡吧?,让我们进入抽象概念、字符、星光平面(辅助平面)和代理对的世界。
本文首先会解释Unicode中的基本概念,这是必需的背景知识。
然后会说明JavaScript如何解析Unicode,以及你可能踩到哪些坑。
你还会学到如何利用ECMAScript 2015的新特性来解决部分难题。
准备好了?那就燥起来吧!
目录:
1 Unicode背后的思想
2 Unicode基本概念
2.1 字符与代码点
2.2 Unicode平面
2.3 码元
2.4 代理对
2.5 组合用字符
3 JavaScript中的Unicode
3.1 转义序列
3.2 字符串比较
3.3 字符串长度
3.4 字符定位
3.5 正则匹配
4 结语
1. Unicode背后的思想
首先问一个最基础的问题:你是怎样阅读并理解这篇文章的?答案很简单,因为你明白这些字以及由字组成的单词的含义。
那你又是如何明白这些字的含义的呢?答案也很简单,因为你(读者)和我(作者)对于这些(呈现在屏幕上的)图形与汉字(即含义)之间的联系有着相同的认知。
对计算机来说这个原理也差不多,只有一点不同:计算机不懂这些字(字母)的含义,只是将其理解为特定的比特序列。
让我们设想一个情景:计算机User1向计算机User2发送一条消息‘hello‘。
计算机并不知道这些字母的含义。所以计算机User1将消息‘hello‘转换为一串数字序列0x68 0x65 0x6C 0x6C 0x6F,每个字母对应一个数字:h对应0x68, e对应0x65,等等。
接着将这些数字发送给计算机User2。
计算机User2收到数字序列0x68 0x65 0x6C 0x6C 0x6F后,使用同一套字母与数字的对应关系重建消息内容,‘hello‘就能正确地显示出来了。
不同计算机之间对字母与数字之间对应关系的协议就是Unicode进行标准化的结果。
根据Unicode,h是一个名为LATIN SMALL LETTER H的抽象字符。这个抽象字符对应数字0x68,也就是一个标记为U+0068的代码点。这些概念将在下一章中说明。
Unicode的作用就是提供一个抽象字符列表(字符集),并给每一个字符分配一个独一无二的标识符代码点(编码字符集)。
2. Unicode基本概念
www.unicode.org网站提到:
Unicode为每一个字符分配一个专有的数字
不分平台
不分程序
不分语言
Unicode是一个世界通用的字符集,它定义了全世界大部分书写体系的字符集,并为每一个字符分配了一个独一无二的数字(代码点)。

Unicode囊括了大部分现代语言、标点符号、附加符号(变音符)、数学符号、技术符号、箭头和表情符号等。
Unicode第一版1.0于1991年10月发布,包含7161个字符。最新版9.0(2016年6月发布)则提供了128172个字符的编码。
Unicode的通用性与开放性解决了过去一直存在的一个问题:供应商们各自实现不同的字符集和编码规则,很难处理。
创建一个支持所有字符集和编码规则的应用是十分复杂的。更不用说你选用的编码可能不支持所有你需要的语言。
如果你觉得Unicode很难,那就想想如果没有它编程会更难。
我还记得从前随机选择所需的字符集和编码规则去读取文件内容的时候。全靠人品啊!
2.1 字符与代码点
抽象字符(即文本字符)是用来组织、管理或表现文本数据的信息单位。
Unicode中的字符是一个抽象概念。每一个抽象字符都有一个对应的名称,例如LATIN SMALL LETTER A。该抽象字符的图像表现形式(glyph)是a。(译者注:glyph即图像字符)
代码点是指被分配给某个抽象字符的数字
代码点以U+<hex>的形式表示,U+是代表Unicode的前缀,而<hex>是一个16进制数。例如U+0041和U+2603都是代码点。
代码点的取值范围是从U+0000到U+10FFFF。
记住代码点就是一个简单的数字。思考有关Unicode的问题时要记得这一点。
代码点就好像数组元素的下标。
Unicode的神奇之处就在于将代码点与抽象字符关联起来。例如U+0041对应的抽象字符名为LATIN CAPITAL LETTER A (表现为A),而U+2603对应的抽象字符名为SNOWMAN(表现为?)
注意,并非所有的代码点都有对应的抽象字符。可用的代码点有1114112个,但分配了抽象字符的只有128237个。
2.2 Unicode平面
平面是指从
U+n0000到U+nFFFF的区间,也就是65536(1000016)个连续的Unicode代码点,n的取值范围是从016到1016。
这些平面将Unicode代码点分为17个大小相等的集合:
平面0包含从
U+0000到U+FFFF的代码点平面1包含从
U+**1**0000到U+**1**FFFF的代码点...
平面16包含从
U+**10**0000到U+**10**FFFF的代码点
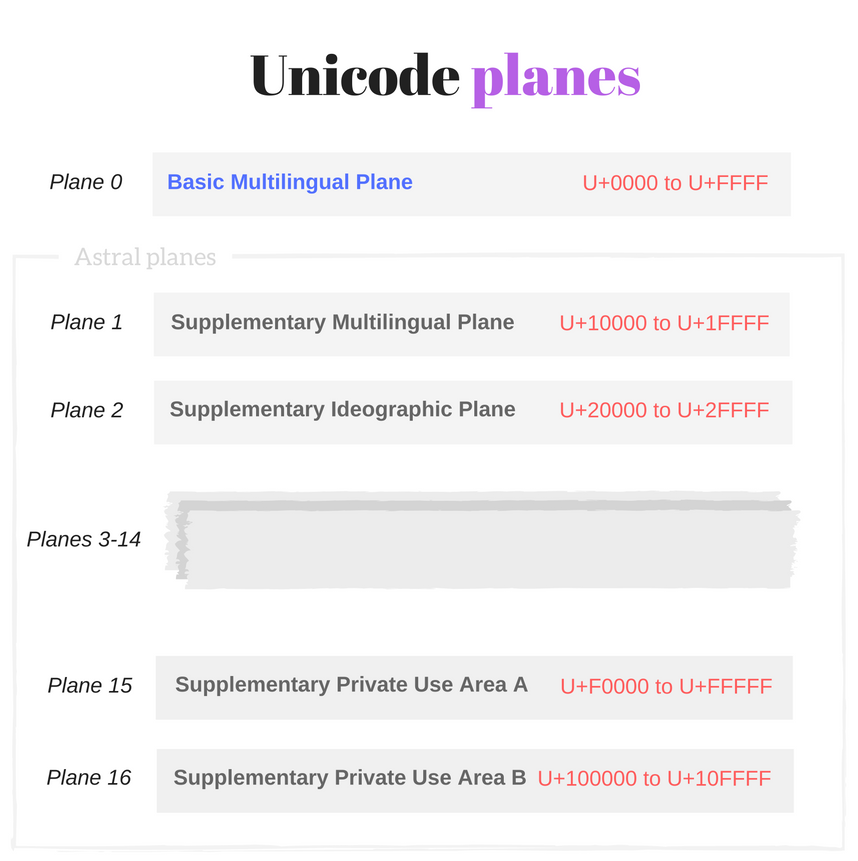
基本多文种平面
平面0比较特殊,被称为基本多文种平面或简称BMP。它包含了大多数现代语言的字符 (基本拉丁字母, 西里尔字母, 希腊字母等)和大量的符号。
如上文所述,基本多文种平面的代码点取值范围是从U+0000到U+FFFF,最多可以有4位16进制数字。
大多数时候开发者处理的都是BMP中的字符。它包含了大多数情况下的必需字符。
BMP中的一些字符:
e对应代码点U+0065抽象字符名: LATIN SMALL LETTER E|对应代码点U+007C抽象字符名: VERTICAL BAR■对应代码点U+25A0抽象字符名: BLACK SQUARE?对应代码点U+2602抽象字符名: UMBRELLA
星光平面
BMP之后的16个平面(平面1,平面2,…,平面16)被称为星光平面或辅助平面。
星光平面的代码点被称为星光代码点。这些代码点的取值范围是从U+10000到U+10FFFF。
星光代码点可能会有5位或6位16进制数字:U+ddddd或U+dddddd。
来看几个星光平面里的字符:
??对应U+1D11E抽象字符名:MUSICAL SYMBOL G CLEF??对应U+1D401抽象字符名:MATHEMATICAL BOLD CAPITAL B??对应U+1F035抽象字符名:DOMINO TITLE HORIZONTAL-00-04??对应U+1F600抽象字符名:GRINNING FACE
2.3 码元
计算机在存储时当然不会使用代码点或抽象字符,它们是存在于开发者大脑中的概念。
所以自然要有一种在物理层面表示Unicode代码点的方式:码元。
码元是指使用某种给定的编码规则给抽象字符编码后得到的比特序列。
字符编码将抽象层面的代码点转换为物理层面的比特序列:码元。
换句话说,字符编码的作用就是将Unicode代码点翻译成独一无二的码元序列。
常用的字符编码有UTF-8, UTF-16 和 UTF-32.
大多数JavaScript引擎使用UTF-16编码字符。它会影响JavaScript处理Unicode的方式。所以从这里开始让我们集中精力于UTF-16吧。
UTF-16(全称:16位统一码转换格式)是一种变长编码:
- BMP中的代码点编码为单个16位的码元
- 星光平面的代码点编码为两个16位的码元
来看几个例子
假设我们想把LATIN SMALL LETTER A,也就是抽象字符a存入硬盘。Unicode告诉我们抽象字符LATIN SMALL LETTER A对应代码点U+0061。
现在我们来看看UTF-16如何转换U+0061。编码规范上说,对于BMP中的代码点只需将它的16进制数字U+0061存入一个16位的码元就行了。
显然,BMP中的代码点刚好能存进一个16位的码元。编码BMP可谓小菜一碟。
2.4 代理对
现在让我们来研究一个复杂些的例子。假设我们想存储一个星光代码点(属于星光平面): GRINNING FACE character ??。该字符对应的代码点是 U+1F600。
由于星光代码点需要21个比特来存储字符信息,UTF-16需要两个码元来编码,每个16比特。代码点 U+1F600 被拆分为所谓的代理对:0xD83D(高位代理码元)与0xDE00(低位代理码元)。
代理对用来表示那些对应2个16位码元序列的抽象字符,其中第一个码元是高位代理码元而第二个是低位代理码元。
编码一个星光代码点需要两个码元:即一个代理对。比如前面那个例子,使用UTF-16编码U+1F600 (??)就使用了一个代理对:0xD83D 0xDE00。
Try in repl.it
`console.log(‘\uD83D\uDE00‘); // => ‘??‘`高位代理码元的取值范围是从0xD800到0xDBFF。 低位代理码元的取值范围是从0xDC00到0xDFFF。
代理对与代码点之间互相转换的算法如下所示:
Try in repl.it
function getSurrogatePair(astralCodePoint) { let highSurrogate = Math.floor((astralCodePoint - 0x10000) / 0x400) + 0xD800; let lowSurrogate = (astralCodePoint - 0x10000) % 0x400 + 0xDC00; return [highSurrogate, lowSurrogate];}getSurrogatePair(0x1F600); // => [0xDC00, 0xDFFF]function getAstralCodePoint(highSurrogate, lowSurrogate) { return (highSurrogate - 0xD800) * 0x400 + lowSurrogate - 0xDC00 + 0x10000;}getAstralCodePoint(0xD83D, 0xDE00); // => 0x1F600代理对并不是一个令人愉快的东西。在JavaScript中处理字符串时我们必须将它们视为特殊情况来处理,具体内容我们在下章细说。
但UTF-16的存储效率很高。因为99%需要处理的字符都属于BMP,只需要1个码元。
2.5 组合用字符
在一个书写系统的上下文中,一个字素或者符号是最小的可区分单元。
字素就是用户所认为的一个字符。屏幕上所展示的一个有形的字素称为图像字符(glyph)。
在大多数情况下,一个Unicode字符就代表一个字素。例如 U+0066 LATIN SMALL LETTER F就是一个英文字母f。
但有时候一个字素会包含一系列字符。
例如å在丹麦语书写系统中是一个不可再分的字素。但它是用U+0061 LATIN SMALL LETTER A (渲染为a) 结合一个特殊字符U+030A COMBINING RING ABOVE(渲染为??)来显示的。
U+030A用来修饰前一个字符,这种字符称为组合用字符。
Try in repl.it
console.log(‘\u0061\u030A‘); // => ‘a?‘ console.log(‘\u0061‘); // => ‘a‘组合用字符是应用在前一个基础字符上以形成完整字素的字符。
组合用字符包括以下字符:重音符号、变音符、希伯来语点、阿拉伯语元音符号和印度语节拍符。
组合用字符通常不会离开基础字符单独使用。我们应该避免单独显示它们。
与代理对一样,在JavaScript中处理组合用字符也很棘手。
在用户看来一个组合字符序列(基础字符+组合用字符)是【一】个符号(例如‘\u0061\u030A‘就是‘a?‘)。但开发者必须清楚实际上要用到两个代码点U+0061和U+030A来生成a?。

3. JavaScript中的Unicode
ES2015规范提到源代码文本使用Unicode(5.1及以上版本)表示。源码文本是一串取值范围从U+0000到U+10FFFF的代码点序列。尽管ECMAScript规范没有指明源码储存和交换的方式,但通常都以UTF-8编码(在web中推荐使用的编码)。
我建议将源代码文本控制在Basic Latin Unicode block(或者说ASCII)中。超出ASCII的字符应该避免使用。这能保证源码文本在编码时少出些问题。
ECMAScript 2015在语言层面上给出了JavaScript中String(字符串)的明确定义:
String类型是由16比特无符号整型数值(“元素”)组成的集合,最少包含0个元素,最多包含253-1个元素。String类型通常用来在运行ECMAScript的程序中表示文本信息,因此String中的每个元素都被当作一个UTF-16码元值。
字符串中的每一个元素都会被引擎解释为一个码元。而字符串的渲染结果并不能明确地反映它包含的码元(及其所代表的代码点)。看下面这个例子:
Try in repl.it
console.log(‘cafe\u0301‘); // => ‘cafe?‘ console.log(‘café‘); // => ‘café‘虽然字面量‘cafe\u0301‘和‘café‘有轻微的差别,但两者都被渲染为同样的字符序列cafe?。
字符串的长度是指其中包含的元素(即16位数值)的个数。ECMAScript在解释String类型时,字符串的每一个元素都被解释为一个UTF-16码元。
从上一章关于代理对和组合用字符的内容可知,某些字符需要2个以上的码元来表示。所以在计算字符长度或通过字符串索引访问字符时要格外小心。
Try in repl.it
let smile = ‘\uD83D\uDE00‘; console.log(smile); // => ‘??‘ console.log(smile.length); // => 2let letter = ‘e\u0301‘; console.log(letter); // => ‘e?‘ console.log(letter.length); // => 2字符串smile包含两个码元:\uD83D (高位代理)和\uDE00(低位代理)。由于字符串是码元的序列,因此尽管 smile 的渲染结果只有一个字符‘??‘,smile.length的值却为2。
对于字符串letter也一样。组合用字符U+0301应用于前一个字符,渲染结果是一个字符‘e?‘。然而letter包含2个码元,因此letter.length值为2。
我的建议是:始终将JavaScript中的字符串视为一串码元序列。字符串渲染的结果并不能清晰地表明它包含了怎样的码元。
星光符号和组合字符序列需要2个以上的码元来编码,却被视为一个语素。
如果字符串中含有代理对或组合用字符,而开发者又不清楚这一点,那么在计算字符串长度或通过索引访问字符时就可能会感到困惑。
大多数JavaScript字符串方法都不能识别Unicode。如果字符串含有混合的Unicode字符,在调用myString.slice()、myString.substring()等方法时就要小心了。
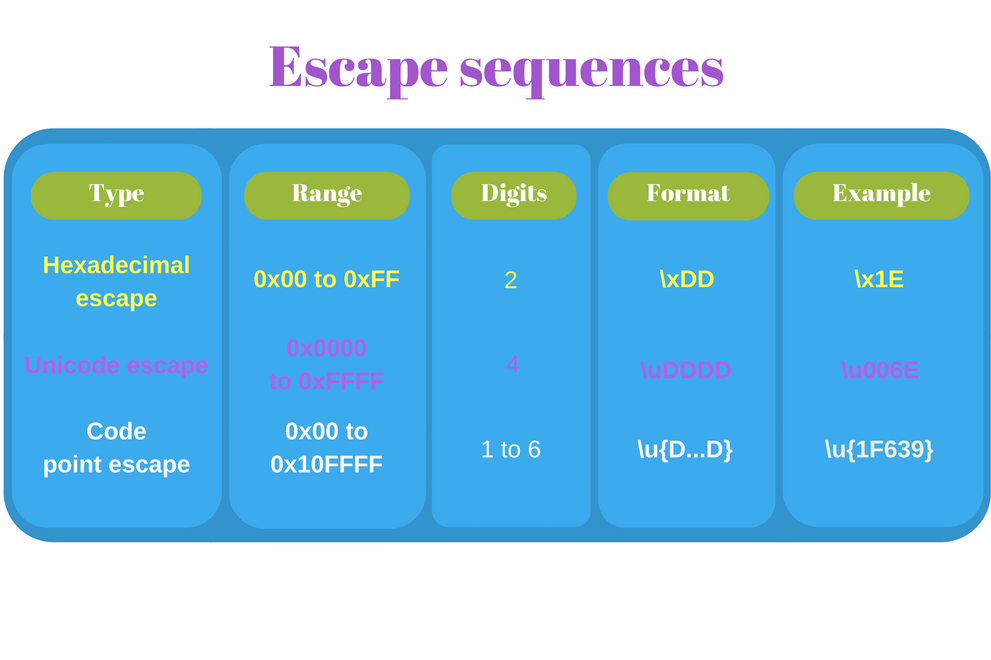
3.1 转义序列
JavaScript字符串中的转义序列通常都是基于代码点数字的。JavaScript有3种转义模式,在ECMAScript 2015中有相关介绍。
来详细看看这几种模式吧。
16进制转义序列
最简短的形式称为16进制转义序列:\x<hex>. \x为前缀,后面跟一个2位的16进制数。
比如‘\x30‘(字符 ‘0‘)和‘\x5B‘(字符 ‘[‘)。
在字符串中使用16进制转义序列如下所示:
Try in repl.it
var str = ‘\x4A\x61vaScript‘; console.log(str); // => ‘JavaScript‘ var reg = /\x4A\x61va.*/; console.log(reg.test(‘JavaScript‘)); // => true16进制转义序列只能编码从U+00到U+FF的有限数量的代码点,因为它只能有2位数字。但16进制转义序列的好处是它很短。
Unicode转义序列
如果你想转义整个BMP中的代码点,那就用Unicode转义序列。转义形式是\u<hex>,\u为前缀,后面跟一个4位的16进制数。
比如 ‘\u0051‘ (字符 ‘Q‘)和‘\u222B‘ (积分符号 ‘∫‘).
像下面这样使用Unicode转义序列:
Try in repl.it
var str = ‘I\u0020learn \u0055nicode‘; console.log(str); // => ‘I learn Unicode‘ var reg = /\u0055ni.*/; console.log(reg.test(‘Unicode‘)); // => trueUnicode转义序列可以编码从U+0000到U+FFFF的有限数量的代码点(BMP中全部代码点),因为它可以有4位数字。大多数时候这已经足够用来表示常用字符了。
想要在JavaScript文本中表示星光字符,可以用两个连续的Unicode转义序列(高位代理与低位代理),生成代理对:
Try in repl.it
var str = ‘My face \uD83D\uDE00‘; console.log(str); // => ‘My face ??‘代码点转义序列
ECMAScript 2015提供了能够表示整个Unicode空间:从U+0000到U+10FFFF,也就是BMP与星光平面的转义序列。
这种新格式被称为代码点转义序列:\u{<hex>},<hex>是一个长度为1至6位的16进制数。 比如‘\u{7A}‘(字符‘z‘)和‘\u{1F639}‘(Funny cat符号??)。
来看看它应该如何应用:
Try in repl.it
var str = ‘Funny cat \u{1F639}‘; console.log(str); // => ‘Funny cat ??‘ var reg = /\u{1F639}/u; console.log(reg.test(‘Funny cat ??‘)); // => true注意正则表达式/\u{1F639}/u有一个特殊flagu,它支持额外的Unicode特性(详情见3.5正则匹配)。
我喜欢代码点转义不需要使用代理对来表示星光符号这一点。让我们来转义代码点U+1F607 SMILING FACE WITH HALO吧: Try in repl.it
var niceEmoticon = ‘\u{1F607}‘; console.log(niceEmoticon); // => ‘??‘ var spNiceEmoticon = ‘\uD83D\uDE07‘ console.log(spNiceEmoticon); // => ‘??‘ console.log(niceEmoticon === spNiceEmoticon); // => true被赋给变量niceEmoticon的字符串字面量包含一个代码点转义序列‘\u{1F607}‘,它表示一个星光代码点U+1F607。
然而在这种表象之下代码点转义序列依旧生成了一个代理对(2个码元)。我们可以看到变量spNiceEmoticon被赋值为使用代理对创建的Unicode转义序列‘\uD83D\uDE07‘,而它与变量niceEmoticon是相等的。
如果正则表达式是用构造函数RegExp创建的,那么在字符串字面量中必须将每一个\ 替换为\\来表示Unicode转义序列。
以下正则表达式对象是相等的:
Try in repl.it
var reg1 = /\x4A \u0020 \u{1F639}/; var reg2 = new RegExp(‘\\x4A \\u0020 \\u{1F639}‘); console.log(reg1.source === reg2.source); // => true3.2 字符串比较
JavaScript中的字符串是码元的序列。因此字符串的比较可以看作是码元的计算与匹配。
这种方法快速而有效,对于“简单”的字符串不失为一种好方法。
Try in repl.it
var firstStr = ‘hello‘; var secondStr = ‘\u0068ell\u006F‘; console.log(firstStr === secondStr); // => true字符串firstStr与secondStr包含相同的码元序列,故它们相等。
假设你想比较两个渲染结果相同,但包含不同码元序列的字符串。
那么你可能会得到意外的结果,因为看上去相同的字符串经过比较却不相等:
Try in repl.it
var str1 = ‘ça va bien‘; var str2 = ‘c\u0327a va bien‘; console.log(str1); // => ‘ça va bien‘ console.log(str2); // => ‘c?a va bien‘ console.log(str1 === str2); // => falsestr1和str2渲染结果看起来相同,但包含不同的码元。
因为字素ç可以通过两种方法生成:
使用
U+00E7LATIN SMALL LETTER C WITH CEDILLA或者用组合字符序列:
U+0063LATIN SMALL LETTER C 加上组合用字符U+0327COMBINING CEDILLA.
那么该如何处理这种情况,正确地比较字符串?答案是字符串标准化。
标准化
标准化是指将字符串转换为统一的表示形式,以保证具有标准等价性(或兼容等价性)的字符串只有一种表示形式。
换句话说,当字符串包含组合用字符序列或其他混合结构等复杂的结构时,我们可以将它统一成标准的形式。标准化的字符串在进行比较或文本查找等操作时就很轻松了。
Unicode Standard Annex #15对标准化方法有详细地描述。
在JavaScript中对字符串进行标准化需要调用ES2015提供的myString.normalize([normForm])方法。normForm是一个可选参数(默认为‘NFC‘),取值为以下标准化模式之一:
‘NFC‘as Normalization Form Canonical Composition(标准化形式-标准性合成)‘NFD‘as Normalization Form Canonical Decomposition(标准化形式-标准性分解)‘NFKC‘as Normalization Form Compatibility Composition(标准化形式-兼容性合成)‘NFKD‘as Normalization Form Compatibility Decomposition(标准化形式-兼容性分解)
让我们利用字符串标准化来改进上面的例子吧,这次可以正确地比较字符串了:
Try in repl.it
var str1 = ‘ça va bien‘; var str2 = ‘c\u0327a va bien‘; console.log(str1 === str2.normalize()); // => true console.log(str1 === str2); // => false‘ç‘与‘c\u0327‘具有标准等价性。
调用str2.normalize(),会返回一个str2 的标准形式副本(‘c\u0327‘替换为‘ç‘)。因此比较语句str1 === str2.normalize()会如预期一般返回true.
str1不受标准化影响,因为它已经是标准形式了。
但为了使操作符两端都取得标准化字符串,将待比较的2个字符串都标准化也是合理的。
3.3 字符串长度
想要知道一个字符串的长度通常我们会访问myString.length这个属性。该属性表明了字符串中包含的码元个数。
对于只包含BMP代码点的字符串来说获取字符串长度通常都能符合预期:
Try in repl.it
var color = ‘Green‘; console.log(color.length); // => 5color中的每个码元都对应着一个字素。预期的字符串长度为5.
长度与代理对
当字符串中包含用来表示星光代码点的代理对时,事情就变得不对劲了。因为每个代理对包含2个码元(一个高位代理和一个低位代理),length属性值会比预期值要大。
比如这个例子:
Try in repl.it
var str = ‘cat\u{1F639}‘; console.log(str); // => ‘cat??‘ console.log(str.length); // => 5字符串str的渲染结果是4个字符cat??。
然而smile.length等于5,因为U+1F639是一个星光代码点,它被编码成了2个码元(一个代理对)。
不幸的是目前还没有一种高性能的原生方法能解决这个问题。
但至少ECMAScript 2015引入了一种能够识别星光字符的算法。星光字符即使被编译为2个码元,也会被计算为一个字符。
这个能够识别Unicode的利器就是字符迭代器String.prototype[@@iterator]()。你可以给字符串加上扩展操作符[...str]或Array.from(str)函数(两者都会调用字符串迭代器)。然后再计算返回数组中的字符个数。
需要注意的是这个解决方案如果大量使用可能会造成轻微的性能损失。
让我们用这个扩展操作符来改进上面的例子吧:
Try in repl.it
var str = ‘cat\u{1F639}‘; console.log(str); // => ‘cat??‘ console.log([...str]); // => [‘c‘, ‘a‘, ‘t‘, ‘??‘] console.log([...str].length); // => 4[...str]创建了一个包含4个字符的数组。编码U+1F639 CAT FACE WITH TEARS OF JOY ??的代理对原封不动地保留了下来,因为字符串迭代器能够识别Unicode。
长度与组合用字符
那么组合字符序列呢?由于每个组合用字符都是一个码元,因此你会遇到同样的困难。
这个问题对于标准化的字符串可以不用担心。如果运气好,组合字符序列会被标准化为单个字符。我们来试试看:
Try in repl.it
var drink = ‘cafe\u0301‘; console.log(drink); // => ‘cafe?‘ console.log(drink.length); // => 5 console.log(drink.normalize()) // => ‘café‘ console.log(drink.normalize().length); // => 4字符串drink包含5个码元(因此drink.length等于5),尽管它只显示4个字符。
在标准化drink时,我们幸运地发现组合字符序列‘e\u0301‘有标准形式‘é‘。因此drink.normalize().length返回了预期的4。
不幸的是标准化并不能解决所有问题。那些比较长的组合字符序列并不都有对应的单个字符标准形式。比如这个例子:
Try in repl.it
var drink = ‘cafe\u0327\u0301‘; console.log(drink); // => ‘cafe??‘ console.log(drink.length); // => 6 console.log(drink.normalize()); // => ‘caf??‘ console.log(drink.normalize().length); // => 5drink包含6个码元所以drink.length值为6。然而drink只包含4个字符。
标准化函数drink.normalize()将组合序列‘e\u0327\u0301‘转换为含有2个字符的标准形式‘?\u0301‘(只去掉了一个组合用字符)。于是我们很难过地发现drink.normalize().length的值为5,仍然不能正确地计算字符的个数。
3.4 字符定位
由于字符串是码元的序列,通过字符串索引来访问字符同样会有困难。
如果字符串只包含BMP字符(除了从U+D800到U+DBFF的高位代理和从U+DC00到U+DFFF的低位代理),字符定位可以得到正确的结果。
Try in repl.it
var str = ‘hello‘; console.log(str[0]); // => ‘h‘ console.log(str[4]); // => ‘o‘上例中每个字符被编码为一个码元,因此通过索引访问字符可以得到正确的结果。
字符定位与代理对
当字符串中包含星光字符时情况就不一样了。
星光字符被编码为2个码元(一个代理对)。因此通过索引来访问字符可能会返回一个单独的高位代理或低位代理,而单独的高位/低位代理是无效字符。
下面这个例子演示了访问星光字符的情形:
Try in repl.it
var omega = ‘\u{1D6C0} is omega‘; console.log(omega); // => ‘?? is omega‘ console.log(omega[0]); // => ‘‘ (unprintable symbol) console.log(omega[1]); // => ‘‘ (unprintable symbol)由于U+1D6C0 MATHEMATICAL BOLD CAPITAL OMEGA是一个星光字符,它的编码使用了一个代理对,即2个码元。
omega[0]访问的是高位代理码元而omega[1]访问的是低位代理码元,代理对被分成了两半。
想要正确地访问字符串中星光字符,有2种方法:
使用能够识别Unicode的字符串迭代器生成一个字符数组
[...str][index]用
number = myString.codePointAt(index)获取代码点,然后用String.fromCodePoint(number)将代码点转换为字符(推荐方法)
让我们来尝试一下这两种方法:
Try in repl.it
var omega = ‘\u{1D6C0} is omega‘; console.log(omega); // => ‘?? is omega‘ // Option 1console.log([...omega][0]); // => ‘??‘ // Option 2var number = omega.codePointAt(0); console.log(number.toString(16)); // => ‘1d6c0‘ console.log(String.fromCodePoint(number)); // => ‘??‘[...smile]返回一个包含字符串omega中字符的数组。代理对被正确识别,因此访问第一个字符返回了符合预期的结果:[...smile][0]返回‘??‘.
函数omega.codePointAt(0)能够识别Unicode,因此它返回了字符串omega第一个字符的星光代码点数字0x1D6C0。函数String.fromCodePoint(number)则返回了这个代码点对应的字符:‘??‘。
字符定位与组合用字符
字符定位在遇到组合用字符时会出现和上面一样的问题。
通过索引访问字符实际上是访问码元。然而组合字符序列应该被整体访问,而不是被分成单个的码元。
下面这个例子演示了这个问题:
Try in repl.it
var drink = ‘cafe\u0301‘; console.log(drink); // => ‘cafe?‘ console.log(drink.length); // => 5 console.log(drink[3]); // => ‘e‘ console.log(drink[4]); // => ??drink[3]只访问到了基础字符e,没有包括组合用字符U+0301 COMBINING ACUTE ACCENT(渲染为?? )。
drink[4]访问的是独立的组合用字符?? 。
这种情况需要使用字符串标准化。组合字符序列U+0065 LATIN SMALL LETTER E +U+0301 COMBINING ACUTE ACCENT有对应的标准形式U+00E9 LATIN SMALL LETTER E WITH ACUTE é
我们来改进一下前面的例子:
Try in repl.it
var drink = ‘cafe\u0301‘; console.log(drink.normalize()); // => ‘cafe?‘ console.log(drink.normalize().length); // => 4 console.log(drink.normalize()[3]); // => ‘é‘需要注意的是并非所有组合字符序列都有对应的单个标准字符。因此标准化并不能解决所有问题。
好在对于欧洲/北美语言来说它可以解决大部分问题。
3.5 正则匹配
正则表达式与字符串一样,是基于码元工作的。因此与上文描述的情形相似,使用正则表达式在处理代理对和组合字符序列时也会遇到困难。
BMP字符的匹配是符合预期的,因为一个码元对应一个字符:
Try in repl.it
var greetings = ‘Hi!‘; var regex = /.{3}/; console.log(regex.test(greetings)); // => truegreetings有3个字符,编码为3个码元。正则表达式/.{3}/期望的是3个码元,因此与greetings匹配成功。
在匹配星光字符(被编码为2个码元的代理对)时,你可能会遇到困难:
Try in repl.it
var smile = ‘??‘; var regex = /^.$/; console.log(regex.test(smile)); // => falsesmile包含星光字符U+1F600 GRINNING FACE。U+1F600被编码为一个代理对0xD83D 0xDE00。
然而正则表达式/^.$/期望的是1个码元,于是正则匹配regexp.test(smile)失败了。
在定义字符区间的时候情况会更糟。JavaScript直接报错了:
Try in repl.it
var regex = /[??-??]/; // => SyntaxError: Invalid regular expression: /[??-??]/: // Range out of order in character class星光代码点会被编码为代理对,因此JavaScript会用码元/[\uD83D\uDE00-\uD83D\uDE0E]/来表示这个正则表达式。而在pattern中每个码元被视为一个单独的元素,所以正则表达式会忽略代理对这个概念。
又由于\uDE00比\uD83D大,\uDE00-\uD83D这个字符区间是无效的,所以就报错了。
正则表达式 u 标志
好在ECMAScript 2015引入了u标志,使得正则表达式能够识别Unicode。这个标志让我们能够正确处理星光字符。
在正则表达式中可以使用Unicode转义序列/u{1F600}/u。这样比写高位代理和低位代理/\uD83D\uDE00/要短。
让我们来尝试应用一下u标志,看看.操作符(包括量词?、+、*和{3}、{3,}, {2,3})能否匹配星光字符:
Try in repl.it
var smile = ‘??‘; var regex = /^.$/u; console.log(regex.test(smile)); // => true正则表达式/^.$/u由于加上了u标志而能够识别Unicode,因此正确地匹配了星光字符。
u标志还能使星光字符区间被正确处理:
Try in repl.it
var smile = ‘??‘; var regex = /[??-??]/u; var regexEscape = /[\u{1F600}-\u{1F60E}]/u; var regexSpEscape = /[\uD83D\uDE00-\uD83D\uDE0E]/u; console.log(regex.test(smile)); // => true console.log(regexEscape.test(smile)); // => true console.log(regexSpEscape.test(smile)); // => true现在[??-??]被视为一个星光字符的区间了。/[??-??]/u成功匹配了‘??‘。
正则表达式与组合用字符
不幸的是不论有没有u标志,正则表达式都会把组合用标记视为独立的码元来处理。
要匹配组合字符序列,只能分别匹配基础字符与组合用字符。
看下面的例子:
Try in repl.it
var drink = ‘cafe\u0301‘; var regex1 = /^.{4}$/; var regex2 = /^.{5}$/; console.log(drink); // => ‘cafe?‘ console.log(regex1.test(drink)); // => false console.log(regex2.test(drink)); // => true字符串渲染为4个字符cafe?。
然而成功匹配‘cafe\u0301‘的正则表达式是匹配5个元素的/^.{5}$/。
4. 结语
也许在JavaScript中有关Unicode的最重要的概念就是将字符串视为码元序列,事实也确实如此。
如果开发者认为字符串是由字素(或字符)组成,忽略码元序列这个概念,就会感到困惑。
在处理包含代理对或组合字符序列的字符串时这种想法会造成误解。
获取字符串长度
字符定位
正则匹配
注意JavaScript中大多数字符串方法都不能识别Unicode:比如myString.indexOf()、myString.slice()等。
ECMAScript 2015在字符串和正则表达式中增加了一些很棒的特性,例如代码点转义序列\u{1F600}。
新的正则表达式标志u使字符串匹配能够识别Unicode,这样一来匹配星光字符就简单多了。
字符串迭代器String.prototype[@@iterator]()能够识别Unicode。使用扩展操作符[...str]或Array.from(str)可以创建一个字符数组,通过这个数组的下标来计算字符串长度或访问字符就不会把代理对拆开了。但要注意这种方法会影响性能。
如果你需要更好的办法来处理Unicode字符,你可以使用punycode库或者生成特殊的正则表达式。
但愿此文能帮助你掌握Unicode!
版权声明
【译】每个JavaScript开发者都该懂的Unicode