
首页 > 代码库 > hadoop压缩与解压
hadoop压缩与解压
1 压缩
一般来说,计算机处理的数据都存在一些冗余度,同时数据中间,尤其是相邻数据间存在着相关性,所以可以通过一些有别于原始编码的特殊编码方式来保存数据, 使数据占用的存储空间比较小,这个过程一般叫压缩。和压缩对应的概念是解压缩,就是将被压缩的数据从特殊编码方式还原为原始数据的过程。
压缩广泛应用于海量数据处理中,对数据文件进行压缩,可以有效减少存储文件所需的空间,并加快数据在网络上或者到磁盘上的传输速度。在Hadoop中,压缩应用于文件存储、Map阶段到Reduce阶段的数据交换(需要打开相关的选项)等情景。
数据压缩的方式非常多,不同特点的数据有不同的数据压缩方式:如对声音和图像等特殊数据的压缩,就可以采用有损的压缩方法,允许压缩过程中损失一定的信 息,换取比较大的压缩比;而对音乐数据的压缩,由于数据有自己比较特殊的编码方式,因此也可以采用一些针对这些特殊编码的专用数据压缩算法。
2 Hadoop压缩简介
Hadoop作为一个较通用的海量数据处理平台,在使用压缩方式方面,主要考虑压缩速度和压缩文件的可分割性。
所有的压缩算法都会考虑时间和空间的权衡,更快的压缩和解压缩速度通常会耗费更多的空间(压缩比较低)。例如,通过gzip命令压缩数据时,用户可以设置 不同的选项来选择速度优先或空间优先,选项–1表示优先考虑速度,选项–9表示空间最优,可以获得最大的压缩比。需要注意的是,有些压缩算法的压缩和解压 缩速度会有比较大的差别:gzip和zip是通用的压缩工具,在时间/空间处理上相对平衡,gzip2压缩比gzip和zip更有效,但速度较慢,而且 bzip2的解压缩速度快于它的压缩速度。
当使用MapReduce处理压缩文件时,需要考虑压缩文件的可分割性。考虑我们需要对保持在HDFS上的一个大小为1GB的文本文件进行处理,当前 HDFS的数据块大小为64MB的情况下,该文件被存储为16块,对应的MapReduce作业将会将该文件分为16个输入分片,提供给16个独立的 Map任务进行处理。但如果该文件是一个gzip格式的压缩文件(大小不变),这时,MapReduce作业不能够将该文件分为16个分片,因为不可能从 gzip数据流中的某个点开始,进行数据解压。但是,如果该文件是一个bzip2格式的压缩文件,那么,MapReduce作业可以通过bzip2格式压 缩文件中的块,将输入划分为若干输入分片,并从块开始处开始解压缩数据。bzip2格式压缩文件中,块与块间提供了一个48位的同步标记,因 此,bzip2支持数据分割。
表3-2列出了一些可以用于Hadoop的常见压缩格式以及特性。
表3-2 Hadoop支持的压缩格式
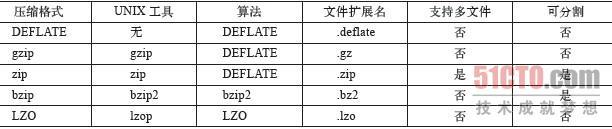
为了支持多种压缩解压缩算法,Hadoop引入了编码/解码器。与Hadoop序列化框架类似,编码/解码器也是使用抽象工厂的设计模式。目前,Hadoop支持的编码/解码器如表3-3所示。
表3-3 压缩算法及其编码/解码器

同一个压缩方法对应的压缩、解压缩相关工具,都可以通过相应的编码/解码器获得。
3 Hadoop压缩API应用实例
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionInputStream;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.ReflectionUtils;
public class CodecTest {
public static void main(String[] args) throws Exception {
compress("org.apache.hadoop.io.compress.BZip2Codec");
// compress("org.apache.hadoop.io.compress.GzipCodec");
// compress("org.apache.hadoop.io.compress.Lz4Codec");
// compress("org.apache.hadoop.io.compress.SnappyCodec");
// uncompress("text");
// uncompress1("hdfs://master:9000/user/hadoop/text.gz");
}
// 压缩文件
public static void compress(String codecClassName) throws Exception {
Class<?> codecClass = Class.forName(codecClassName);
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
//输入和输出均为hdfs路径
FSDataInputStream in = fs.open(new Path("/test.log"));
FSDataOutputStream outputStream = fs.create(new Path("/test1.bz2"));
System.out.println("compress start !");
// 创建压缩输出流
CompressionOutputStream out = codec.createOutputStream(outputStream);
IOUtils.copyBytes(in, out, conf);
IOUtils.closeStream(in);
IOUtils.closeStream(out);
System.out.println("compress ok !");
}
// 解压缩
public static void uncompress(String fileName) throws Exception {
Class<?> codecClass = Class
.forName("org.apache.hadoop.io.compress.GzipCodec");
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
CompressionCodec codec = (CompressionCodec) ReflectionUtils
.newInstance(codecClass, conf);
FSDataInputStream inputStream = fs
.open(new Path("/user/hadoop/text.gz"));
// 把text文件里到数据解压,然后输出到控制台
InputStream in = codec.createInputStream(inputStream);
IOUtils.copyBytes(in, System.out, conf);
IOUtils.closeStream(in);
}
// 使用文件扩展名来推断二来的codec来对文件进行解压缩
public static void uncompress1(String uri) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path inputPath = new Path(uri);
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
CompressionCodec codec = factory.getCodec(inputPath);
if (codec == null) {
System.out.println("no codec found for " + uri);
System.exit(1);
}
String outputUri = CompressionCodecFactory.removeSuffix(uri,
codec.getDefaultExtension());
InputStream in = null;
OutputStream out = null;
try {
in = codec.createInputStream(fs.open(inputPath));
out = fs.create(new Path(outputUri));
IOUtils.copyBytes(in, out, conf);
} finally {
IOUtils.closeStream(out);
IOUtils.closeStream(in);
}
}
}
hadoop压缩与解压