
首页 > 代码库 > 第六章、epub文件处理 -- 解析container文件与.opf文件
第六章、epub文件处理 -- 解析container文件与.opf文件
第六章、epub文件处理 -- 解析container文件与.opf文件
这一章我们会接着第三章结尾介绍的FBReaderApp类的openBookInternal继续,开始介绍解析container文件与.opf文件。
这一章中会涉及到第二章、第四章、第五章中介绍的内容,大家可以互相参照,加深理解
首先,我们来回顾下第四章“epub文件处理 -- epub文件内部组成”的内容。我们在第四章中曾经介绍过,epub文内部包含的文件包括“container.xml文件、.opf文件、.ncx文件、.xhtml文件”。这些文件都是被压缩过的xml文件,而在这些不同的xml文件中包含着不同的标签,每种标签又都代表着不同的信息。为了对每种xml文件的标签作统一处理,FBReader程序对每种文件都设置了对应的类。每种类就专门处理来对应的xml文件里面的标签。
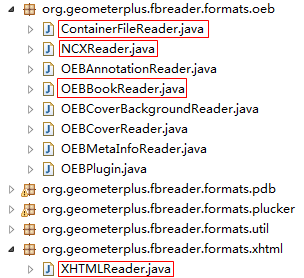
ContainerFileReader类对应container.xml文件;OEBBookReader类对应.opf文件; NCXReader类对应.ncx文件文件;XHTMLReader类对应.xhtml文件。
PS:这些类都是ZLXMLReaderAdapter抽象类的子类,本章会涉及到ContainerFileReader类与OEBBookReader类
我们在第四章中还曾经分别介绍过container文件与.opf文件分别的作用。
container文件的“作用就是标明了.opf文件的位置”;.opf文件则描述了epub书籍的元信息、epub文件内部对应不同章节对应的文件的位置以及每个章节出现的先后次序。
我们这一章解析这两种文件,就是为了获取这些信息。
在介绍解析流程之前,我们还需要再回顾下解析xml文件的三个核心类。这个部分内容,我们曾经在第二章“解析资源文件”中介绍过。当时,我们是这么介绍的:“
继续回到解析xml文件的核心类ZMLZMLProcessor、ZLXMLParser、ZLXMLReader。
这三个核心类的调用顺序一般是这样的:
1、ZLXMLReaderAdapter抽象类的子类(ResourceTreeReader类)里面的read方法调用ZLXMLProcessor类的read方法
2、ZLXMLProcessor类的read方法通过AndroidAssetsFile类(ZLResourceFile类的子类)的getInputStream方法获取一个针对资源文件的字节流类(AssetInputStream类),并以这个字节流类为参数初始化了一个针对资源文件的字符流类。接着,就调用了ZLXMLParser类的doIt方法。
3、 ZLXMLParser类的doIt方法利用字符流类将文件转换成一个char数组。再利用for循环迭代byte数组的过程中,doIt方法又反过来调用ZLXMLReader接口实现类(ResourceTreeReader类)的startElementHandler与endElementHandler方法对byte数组中元素所代表的不同节点进行操作。
请注意,上面这段话标红的部分,这些部分在解析epub内部文件的流程中已经不适用了。
1、ZLXMLReaderAdapter抽象类的子类(ContainerFileReader类、OEBBookReader类、NCXReader类、XHTMLReader类中的一种)里面的read方法调用ZLXMLProcessor类的read方法
2、ZLXMLProcessor类的read方法通过ZLZipEntryFile类的getInputStream方法和ZLZipEntryFile类对应的LocalFileHeader类获取一个针对epub内部xml文件的字节流类(ZipInputStream类),并以这个字节流类为参数初始化了一个针对资源文件的字符流类。接着,就调用了ZLXMLParser类的doIt方法。
3、 ZLXMLParser类的doIt方法利用字符流类将文件转换成一个char数组(第五章用一整个章节介绍了这个转换的流程)。再利用for循环迭代byte数组的过程中,doIt方法又反过来调用ZLXMLReader接口实现类(ResourceTreeReader类)的startElementHandler与endElementHandler方法对byte数组中元素所代表的不同节点进行操作。
首先,“ZLXMLReaderAdapter抽象类的子类”已经不再是那个ResourceTreeReader类了,而是专门对应epub内部各种xml文件的一个类(ContainerFileReader类、OEBBookReader类、NCXReader类、XHTMLReader类中的一种)。
PS:ResourceTreeReader类是程序专门为处理资源文件内部的标签而创建的类
其次,程序在解析epub内部xml文件的时候,不会去获取“针对资源文件的字节流类”,而是会通过调用ZLZipEntryFile类的getInputStream方法获取针对epub内部xml文件的字节流类(ZipInputStream类)。相对得,之后也会以这个字节流类来获得对应的字符流类。
PS:ZLZipEntryFile类的getInputStream方法的具体处理流程我们曾经用了第五章“XML文件处理 -- 解压”一整章来作介绍
好了,下面我们就正式开始解析流程。
FBReaderApp类的openBookInternal方法中会调用BookModel类的createModel方法。

crateModel方法,会调用PluginCollection类的getPlugin方法

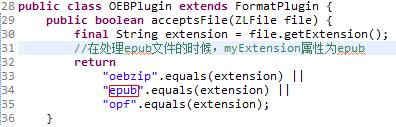
getPlugin方法调用了所有FormatPlugin抽象类子类的acceptsFile方法,这个方法其实就是比较了Book类中File属性指向的File类的myExtension属性(这个属性的赋值我们在第三章“获取书籍信息”中介绍过),如果myExtension属性代码内置的变量相同,getPlugin方法就会返回当前的FormatPlugin抽象类子类。而在处理epub文件时,代码会返回OEBPlugin类。
OEBPlugin类readModel方法
获得了OEBPlugin类之后,代码就会调用该类中的readModel方法。

readModel方法调用了两个方法:OEBPlugin类的getOpfFile方法与OEBBookReader类readBook方法

OEBPlugin类的getOpfFile方法:
getOpfFile方法一共有三步:
第一步 调用ZLFile类的createFile方法
这个方法的参数oebFile参数是Book类的File属性(这个属性的赋值过程在第三章“获取书籍信息”介绍过),最终这个方法会返回一个代表container.xml文件的ZLZipEntryFile类。
我们曾经在第二章“解析资源文件”中介绍过:“ZLZipEntryFile类用来处理epub文件内部的xml文件”。也曾经在第四章“epub文件处理 -- epub文件内部组成”介绍过container.xml文件,这个文件的作用就是“标明了.opf文件的位置”。
我们从代码中可以看到,代表container.xml文件的ZLZipEntryFile会包含两个属性(85行):一个代表epub文件的ZLPhysicalFile类,一个代表epub内部xml文件名种子的String变量(在这里就是)。
第六章、epub文件处理 -- 解析container文件与.opf文件