
首页 > 代码库 > 使用分层的Selenium框架进行复杂 Web 应用的自动测试
使用分层的Selenium框架进行复杂 Web 应用的自动测试
?
Selenium概述
Selenium是一种Web应用的自动测试工具,通过模拟用户对Web页面的各种操作,可以精确重现软件测试人员编写的Test Cases步骤。Selenium包含三个工具:Selenium-IDE,Selenium-RC以及Selenium-Core。其中,Selenium-Core是驱动Selenium工作的核心部分,作为一个用JavaScript编写的测试引擎,它可以操作Web页面上的各种元素,诸如:点击按钮、输入文本框,以及断言Web页面上存在某些文本与Web元素等。
Selenium-IDE是一个Firefox插件,能够录制回放用户在Firefox中的行为,并把所记录的Selenese(Selenium Commands)转化为Java/C#/Python/Ruby等语言,在Selenium-RC中修改复用。对于较为复杂的Test Cases,Selenium-IDE的功能有限,往往用它录制大致的步骤,再转化为测试人员熟悉的编程语言,在此基础上完善,形成更为强大且灵活的Selenium-RC Test Cases。
Selenium-RC(Selenium Remote Control)在Web浏览器与需要测试的Web应用间架设代理服务器(Selenium Server),使得JavaScript引擎与被测Web应用同源,绕开同源策略的限制(Same Origin Policy),进而取得对Web页面进行各种操作的权限。
开发环境配置
以Java作为 测试用语言为例,在Eclipse中新建一个Java项目Test Search Engine,下载Selenium-RC软件包,把selenium server/selenium java client driver的Jar以及JUnit库加入到该项目的Java Build Path。

图1.Build Path配置
启动Selenium-Server,可以在命令行中使用java-jar命令直接运行可执行Jar包(对于中文Windows操作系统且使用IBM JDK,还需要加参数-Dibm.stream.nio=true)。如果想在Java程序中启动/停止Selenium-Server,首先,新建一个RemoteControlConfiguration对象rcc,并指定远程控制参数(包括配置Selenium Server的监听端口,Firefox浏览器的Profile等),然后新建一个SeleniumServer对象,把rcc传入SeleniumServer的构造函数(对于中文Windows操作系统且使用IBM JDK,在Eclipse的Run Configurations的VM arguments中加入-Dibm.stream.nio=true)。
清单1.使用Java启动/停止Selenium Server
RemoteControlConfiguration rcc=new RemoteControlConfiguration();
rcc.setPort(4444);//指定Selenium Server开放端口
SeleniumServer SELENIUM_SERVER;
SELENIUM_SERVER=new SeleniumServer(rcc);
SELENIUM_SERVER.start();//启动server
//测试代码
SELENIUM_SERVER.stop();//停止server
此外,Selenium Server还可以通过Ant脚本来控制启动/停止,这提供了另一种灵活而强大的项目控制方式。
清单2.使用Ant脚本启动/停止Selenium Server
在Selenium-Server启动后,建立一个Selenium类的实例selenium,并通过这个实例与Selenium-Server进行交互,方法如下。
清单3.Selenium实例的启动/停止
Selenium selenium=new DefaultSelenium(java.lang.String serverHost,
int serverPort,
java.lang.String browserStartCommand,
java.lang.String browserURL);
selenium.start();
//经由selenium控制浏览器模拟各种用户操作
selenium.stop();
Selenium实例包含丰富接口,可以对各种Web元素进行各种操作。例如,在谷歌页面中输入“developerWorks”,点击搜索按钮,在结果页面中验证是否包含“developerWorks中国”字样等。
清单4.Selenium测试的简单示例
Selenium selenium=new DefaultSelenium( "localhost",4444,"*firefox",
"http://www.google.cn");
selenium.start();//启动浏览器
selenium.open( "/");//打开www.google
selenium.type( "q","developerworks");//输入文本框
selenium.click( "btnG");//点击搜索按钮
selenium.waitForPageToLoad( "30000");//等待加载结果页面
verifyTrue(selenium.isTextPresent( "developerWorks中国"));//验证是否存在指定字符
selenium.stop();//关闭浏览器
当Selenim遇到TestNG
用Selenium 测试Web页面时,所重现的各种行为依赖于测试人员的输入参数,例如:选择下拉餐单的项目,在文本框中输入字符等。不同的测试用例对应不同的输入,若有方法能够简单有效的传入测试用参数,会大大提高测试用例的复用性和可 维护性。当Selenium遇到TestNG,这些就可以实现。TestNG中的NG,意为Next Generation,事实上,该测试框架引入了不少新特性:灵活的测试配置,支持JDK 5注释,支持数据驱动的测试,强大的执行模型等。
继续上文谷歌搜索的场景,通过实例来了解TestNG的用法与功能。
清单5.TestNG应用示例
@Parameters({"url","query-string","btn-id","txt-id","verify-String"})
@Test
public void testGoogle(String url,String queryString,String btnID,
String txtID,String verifyString){
selenium=new DefaultSelenium("localhost",4444,"*firefox",url);
selenium.start();
selenium.open("/");
selenium.type(txtID,queryString);
selenium.click(btnID);
selenium.waitForPageToLoad("30000");
verifyTrue(selenium.isTextPresent(verifyString));
selenium.stop();
}
上面的代码清单中,注释Parameters指定的参数在TestNG测试框架的配置文件testng.xml里有具体定义,如下所示:
清单6.testng.xml示例
不难想到,只要修改testng.xml中的参数值,就能由输入参数驱动不同的测试用例。然而,仅仅在testng.xml中指定参数有很大的局限性,显然过多的参数会难以维护,无法井井有条地组织分属不同Test Cases的输入。在下文中,我们来解决这个问题。
回页首
基于Selenium的分层测试框架
作者在工作中,测试基于OSGi平台的多个插件。每个插件实现特有的功能,有多条测试路径需要覆盖,同时,各个插件之间又有共通之处,可以抽取某些部分进行复用。对此,我们假设这样的场景:分别在谷歌、百度和必应中搜索各种关键字,并在返回的结果页面中验证是否存在目标字符串。每个搜索引擎都可以视为一个待测的组件,分别为它们撰写Test Cases,并组织成一个Test Suite,用于执行测试。事实上,3个搜索引擎的测试由于同质性,还能够合并为一种测试,用不同的输入参数来指定所要测试的那个搜索引擎。这里视为三个组件,只是为了说明如何在Selenium+TestNG环境中组织多个测试模块。
自上而下地考虑,上段描述的测试场景能够进行分解。Test Suite包含三类Test Cases(谷歌、百度与必应),每类Test Cases的一个Test Case由若干可复用的Test Tasks组成,通过传入不同的参数,Test Task完成同质的不同行为。在Test Task之下,定义相关文件,包含待测试的Web页面元素的定位信息。因此,分层Selenium框架有三个层次:
appObjects——Web页面元素定位信息,如按钮与文本框等;
tasks——测试步骤中可复用的行为;
test cases——由tasks组成的测试用例。
Web元素locators定义与收集
Selenium根据XPath来定位Web元素,XPath的相关知识不属于本文的内容。前面例子中,在TestNG的配置文件testng.xml里定义文本框与按钮的locators,对于复杂的测试场景而言,这不是好的实践。因此,我们在appObjects层建立文件,将Web页面元素locators归入,便于维护使用。Selenium-IDE的Find功能适于完成这一步骤。文件googlePages.properties的内容如下:
清单7.locators文件示例
#define the keys and corresponding XPaht locators of google page.
googleSearchTxtField=//input[@name=‘q‘]
googleSearchBtn=//input[@name=‘btnG‘]
这时,在testng.xml中,删去locators相关的parameters,只需要解析.properties文件,生成locators的properties备用。在所附的源码中可以看到.properties文件的解析器PropUtils的简单实现。
测试任务分解与实现
为说明任务分解,以简单的搜索过程为例,可以分为输入搜索关键字、点击搜索按钮、以及验证结果页面。实际代码如下所示,不难发现,由参数决定行为方式的 测试任务,都接受一个paraMap数据结构,并根据其内容在方法内采取适当的行为。通过这种方式,test cases能够以参数配置文件来驱动测试任务实施其想要的行为。
清单8.Test Task代码示例
public void openSite(){
selenium.open( "/");
}
public void typeSearchTxtField(HashMap paraMap){
utils.waitForElement((String)elemMap
.get(TestGoogleConstants.GOOGLE_SEARCH_TXT_FIELD),30);
selenium.type((String)paraMap
.get(TestGoogleConstants.GOOGLE_SEARCH_TXT_FIELD),
(String)elemMap
.get(TestGoogleConstants.GOOGLE_SEARCH_TXT_FIELD));
}
public void clickSearchBtn(){
utils.waitForElement((String)
elemMap.get(TestGoogleConstants.GOOGLE_SEARCH_BTN),30);
selenium.click((String)elemMap.get(TestGoogleConstants.GOOGLE_SEARCH_BTN));
}
public void verifyResult(HashMap paraMap){
stc.verifyTrue(selenium.isTextPresent((String)
paraMap.get(TestGoogleConstants.VERIFY_STRING)));
}
clickSearchBtn方法无需参数输入,因为其任务只是点击搜索按钮,在test cases需要时调用即可。这里只是以一个简单的例子说明如何分解任务,对于实际的test case,这个过程会复杂许多,但其后的复用与灵活调用完全值得这些工作的付出。
Test Cases实现与Test Tasks调用
Test Cases作为一系列测试步骤的集合,可以通过调用若干Test Tasks实现。以贯穿本文的搜索引擎为例,以此调用上一部分定义的test taskss,重现整个测试过程。简单代码如下所示。
清单9.Test Case代码示例
@Parameters({"google_se_para_1"})
@Test
public void testGoogle_1(String paraFile){
paraMap=(HashMap)XMLParser.getInstance()
.parserXml(paraFile);
tgTasks.openSite();
tgTasks.typeSearchTxtField(paraMap);
tgTasks.clickSearchBtn();
tgTasks.verifyResult(paraMap);
}
Test Cases在分层Selenium测试框架下,就是按照要求调用已有的Test Tasks。值得注意的是,在上面两个代码列表里的paraMap参数。这个哈希表由我们实现的解析器解析参数定义文件而得到。TestNG的Parameters参数机制,使得Test Cases能够灵活地指定参数文件,从而驱动不同的Test Cases。
清单10.参数定义文件示例
developerworks
developerWorks中国
建立输入参数解析器(parser)及参数文件
Test Cases与Test Tasks的顺畅工作,需要输入参数文件及对应的参数解析器的配合。我们以上面代码清单的例子说明参数文件的格式。标签在最外层,其内的子元素为具体的参数值,如标签表示一个页面元素与其对应的输入。元素的id属性与清单6中的.properties文件定义的locators对应,而其子元素则表示该locator的输入值。解析器的具体实现可以参见所附的示例源代码。
回页首
导出可执行Jar包以部署到各类测试服务器
为了能够把Selenium测试脚本导出成一个可执行Jar包,我们可以把testng.xml中定义的相关内容,在Java代码中实现,如下所示。
清单11.testng.xml的Java表示
//suite tag
XmlSuite suite=new XmlSuite();
//set suite name
suite.setName("Test Search Engine");
//set parameter tag
HashMap para=new HashMap();
para.put("google_se_para_1","/src/resources/google_se_para_1.xml");
suite.setParameters(para);
//test tag
XmlTest testGoogle=new XmlTest(suite);
testGoogle.setName("LDAP configuration template");
List classes=new ArrayList();
classes.add(new XmlClass(TestGoogleTestCase.class));
testGoogle.setXmlClasses(classes);
这份代码列表的功能与前文的testng.xml完全相同,把这些代码添加到新定义的类SearchEngineSuite的main函数中,在这个类的方法中启动并关闭Selenium服务器,并把相关文件打成一个可执行Jar,就可以通过命令行的java–jar命令,执行Selenium测试。当然,因为具有通用性,也可以部署到各类测试服务器,执行测试。
这里推荐使用Eclipse的插件Fat Jar导出runnalbe Jar。首先,填入输出Jar的命名,并把SearchEngineSuite设置为Main-Class。然后,勾选”merge individual-sections of all MANIFEST.MF files”,后一项视需求勾选。

图2.Fat Jar导出步骤1
进入下一步,选择要导出的文件,包含源代码以及用到的Jar文件,点击完成即可。
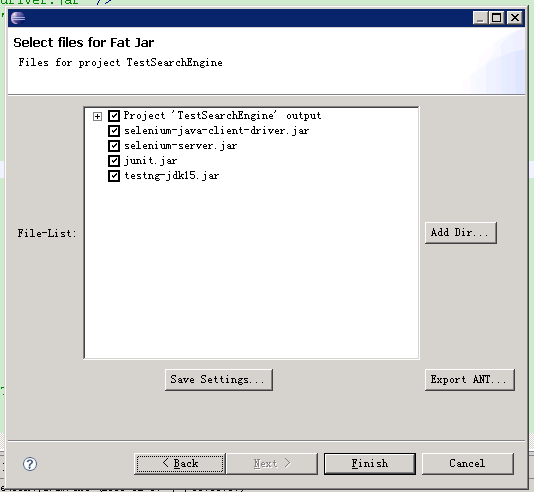
图3.Fat Jar导出步骤2
导出后的runnable Jar,使用命令java–jar TestSearchEngine_fat.jar运行即可。
结束语
通读本文不难发现,Selenium提供了一种Web 测试的新方法,在分层框架的支持下,其功能更为强大,运用灵活,有很强的复用性。通过指定不同的参数文件,本文的例子可以对Google进行不同关键字的测试验证,同样的方法可以应用于百度与必应。并通过testng.xml或者其Java代码形式整合为一个Test Suite运行。在所附源代码中可以看到详细的实现。在作者的实际工作中,复杂的测试需求也能应付自如。
本文选自:http://www.spasvo.com/ceshi/open/kygncsgj/Selenium/2014128164908.html
使用分层的Selenium框架进行复杂 Web 应用的自动测试