
首页 > 代码库 > 字符集与编码01--charset vs encoding
字符集与编码01--charset vs encoding
声明:此文章转载自 http://my.oschina.net/goldenshaw/blog/304493
许多时候,字符集与编码这两个概念常被混为一谈,但两者是有差别的,作为深入理解的第一步,首先要明确:
字符集与字符集编码是两个不同层面的概念
charset是character set的简写,即字符集。
encoding是charset encoding的简写,即字符集编码,简称编码。
与接口及接口实现的对比
可以把这两者与接口及接口实现做个对比:
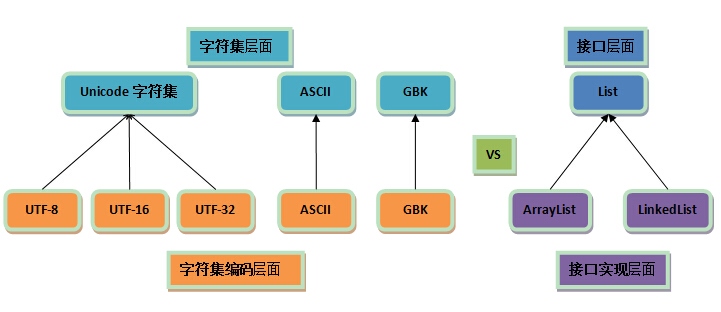
从这里可以很清楚地看到,
编码是依赖于字符集的,就像代码中的接口实现依赖于接口一样;
一个字符集可以有多个编码实现,就像一个接口可以有多个实现类一样。
具体例子及规范用法
可以简单看两个例子,一个自于html文件,用的是charset:
<meta http-equiv="content-type" content="text/html;charset=utf-8">另一个来自于xml文件,用的是encoding:
<?xml version="1.0" encoding="UTF-8"?>哪一种用法更规范呢?显然是后者,它更加准确地区分了字符集与编码的概念。
“charset=utf-8”容易让人误解为存在一种叫“UTF-8”的字符集,但实际上,无论是UTF-8还是UTF-16,UTF-32都是对同一种字符集的不同编码实现而已。
为什么要严格区分字符集与编码这两个概念?
字符集与编码一对一的情形
有很多的字符编码方案,一个字符集只有唯一一个编码实现,两者是一一对应的。比如GB2312,这种情况,无论你怎么去称呼它们,比如“GB2312编码”,“GB2312字符集”,说来说去其实都是一个东西,可能它本身就没有特意去做什么区分,所以无论怎么说都不会错。
为什么一对一是一种普遍的情况呢?
我们以GB2312为例,GB=Guo Biao=国标=国家标准,标准出来本来就为了统一,你一个标准弄出N个编码实现来,你让人家用哪个呢?
字符集与编码一对多的情形
事情到了Unicode这里,变得不一样了,唯一的Unicode字符集对应了三种编码:UTF-8,UTF-16,UTF-32。如果还是这么笼统地去称呼,就很容易搞混了。
为什么Unicode这么特殊?
人们弄出新的字符集标准,驱动力无外乎是旧的字符集里的字符不够用了。
Unicode的目标是统一所有的字符集,囊括所有的字符,所以字符集发展到它这里就到头了,再去整什么新的字符集就没必要也不应该了。
但如果觉得它现有的编码方案不太好呢?在不能弄出新的字符集情况下,只能在编码方面做文章了,于是就有了多个实现,这样一来传统的一一对应关系就打破了。
我们严格地区分字符集与编码两个概念,理由就在这里。
指定了编码,它所对应的字符集自然就指定了,编码才是我们最终要关心的。
Unicode早期与现在的对比
让我们来看一个图,它展现了Unicode早期与现在的一些差别:

注:由于历史方面的原因,你还会在不少地方看到把Unicode和UTF-8混在一块的情况,这种情况下的Unicode通常就是UTF-16或者是更早的UCS-2编码,在后面的篇章中我们会进一步分析。
下面是“记事本程序”保存时的一个截图,是Unicode的一个不规范使用,这里的Unicode就是指UTF-16:

我们现在说了不少Unicode,由于各种原因,必须承认,在不同的语境下,“Unicode”这个词有着不同的含义,它可能指:
Unicode标准
Unicode字符集
Unicode的抽象编码(编号),也即码点(code point)
Unicode的一个具体编码实现,通常即为变长的UTF-16(16或32位),又或者是更早期的定长16位的UCS-2
关于这些话题在后面的篇章里会做进一步探讨。
字符集与编码01--charset vs encoding