
首页 > 代码库 > Heat-AutoScaling
Heat-AutoScaling
在openstack的I版本号中,Heat中加入了对于AutoScaling资源的支持,github上也提供了相应的AutoScaling的模板,同一时候也支持使用ceilometer的alarm来触发Scaling Policy。
AutoScaling定义的流程

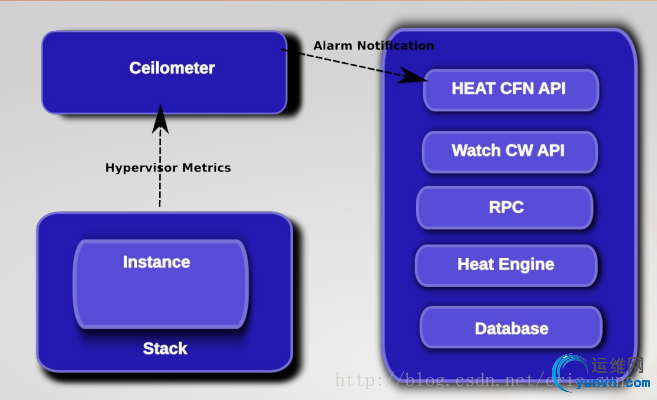
AutoScaling的工作流程
AutoScaing实战为了简单,下载https://github.com/openstack/hea ... ot/autoscaling.yaml。以此为基础进行调整
模板文件没什么好说,用到了HOT模板的一些资源。
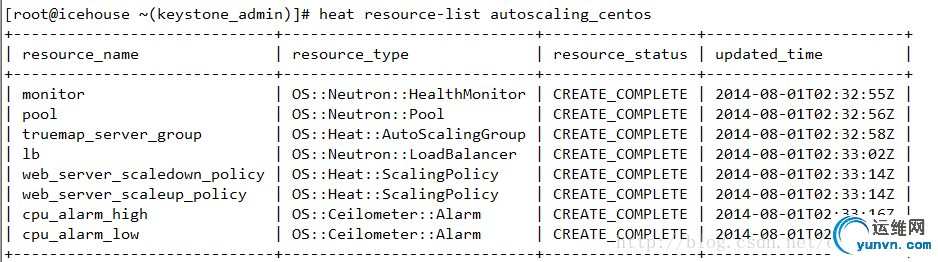
下图为Alarm的列表
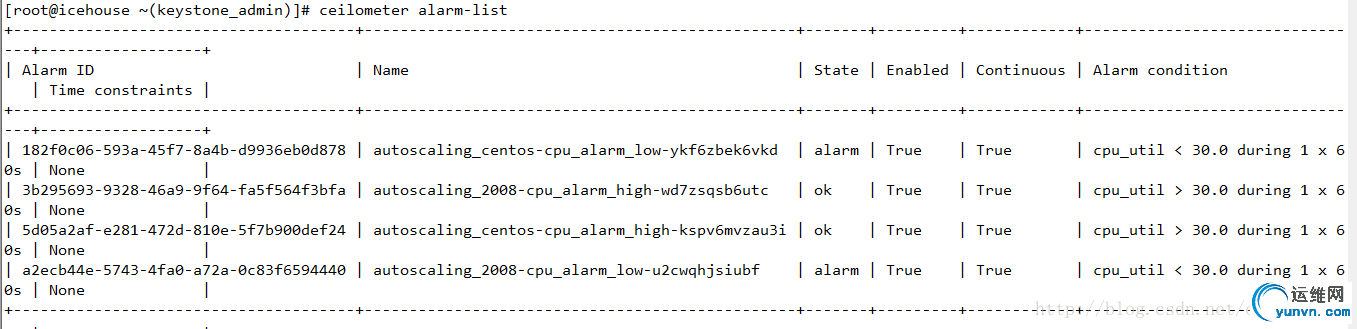
下图为某个Alarm的history
IceHouse中的alarm是一个监控特定指标的对象。alarm的状态包含:
1、OK。表示指标正常
2、ALARM。表示指标异常。
AutoScaling定义的流程
- 首先定义一个Auto Scaling Group,该Group 定义了能够持有资源的类型以及的最大、最小资源数
- 依据需求定义Alarm的触发条件,比如当CPU利用率在一分钟内平均值超过50%时触发警报
- 针对某个详细的Alarm。定义Policy,比如CPU利用率长时间偏高时,就在AutoScalingGroup中又一次初始化一个同样实例,该Policy须要与 1中定义的Group绑定
- 为了更好的提高资源利用率,在定义自己主动收缩机制的同一时候能够定义负载均衡(Neutron LBAAS)。
AutoScaling的工作流程
- Ceilometer通过获取实例的监控參数,发现实例的监控项的统计信息在阈值范围内,且符合已经定义的Alarm触发规则
- 触发Policy.在生成Policy和Alarm时,Alarm会设置其alarm_actions属性,该属性的值能够理解为调用特定Policy服务的URL,此时该URL被调用
- Policy被调用,依据配置,决定添加还是降低实例
AutoScaing实战为了简单,下载https://github.com/openstack/hea ... ot/autoscaling.yaml。以此为基础进行调整
模板文件没什么好说,用到了HOT模板的一些资源。
- 该模板中的Alarm创建出来后,查看alarm 列表能够发现Continues属性都是false( 假设查看明细该属性相应的是repeat_actions属性)该属性的为false代表alarm_action仅仅会被运行一次。所以为了达到更好的演示效果。须要将其改动为True
- 为了达到演示的效果,能够将Alarm的Period设置的短一点,比方说10s
- 假设Alarm的状态长时间为insufficent_data,说明ceilometer长时间没有採集到监控指标的数据,为了达到更好的演示效果能够调整/etc/ceilometer/pipeline.yaml文件里採集指标的间隔。
默认的间隔是600秒。能够将其设置为小于CoolDown或是Alarm Period 的时间
- 对于运行的过程,主要能够參考heat-engine.log, heat-api-cfn.log, alarm-evaluator.log等日志
- 当前的版本号运行过程中有下面错误产生。能够參考https://review.openstack.org/#/c/92887/进行解决2014-08-0105:38:08.410 3834 ERROR heat.engine.service[req-96a84baa-6b6f-4a4e-a2f3-90c0a02612e7 None] Unable to retrieve stack40e7560e-848e-4d78-bac0-8eb4f26ac22f for periodic task
下图为Alarm的列表
下图为某个Alarm的history
IceHouse中的alarm是一个监控特定指标的对象。alarm的状态包含:
1、OK。表示指标正常
2、ALARM。表示指标异常。
假设连续几个周期都处于ALARM状态,那么就会触发一个或多个policy,进而触发scaling group的扩缩。
3、INSUFFICIENT_DATA。表示数据不可用。出现这个状态主要是由于 缺少监控指标的数据,处于这个状态的Alarm也不会被触发。假设为了測试目的。能够通过改动/etc/ceilometer/pipeline.yaml文件里的interval參数来调整收集数据的间隔
Heat-AutoScaling
声明:以上内容来自用户投稿及互联网公开渠道收集整理发布,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任,若内容有误或涉及侵权可进行投诉: 投诉/举报 工作人员会在5个工作日内联系你,一经查实,本站将立刻删除涉嫌侵权内容。