
首页 > 代码库 > RHCS
RHCS
简单的说,集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源。这些单个的计算机系统就是集群的节点(node)。一个理想的集群是,用户从来不会意识到集群系统底层的节点,在他/她们看来,集群是一个系统,而非多个计算机系统。并且集群系统的管理员可以随意增加和删改集群系统的节点。
通过特殊的软件将若干服务器连接在一起并提供故障切换功能的实体我们称之为高可用集群。可用性是指系统的uptime,在7x24x365的工作环境中,99%的可用性指在一年中可以有87小时36分钟的DOWN机时间,通常在关键服务中这种一天多的故障时间是无法接受的,所以提出了前面提到的错误恢复概念,以满足99.999%的高可用性需求。
这里我们先说一下几个概念:
1、服务(Service),是HA集群中提供的资源,包括Float IP,共享的存储,apache等等。
2、成员服务器(Member Server) 也叫节点(Node),是HA中实际运行服务提供资源的服务器。
3、失效域(Failover Domain),是HA中提供资源的服务器的集合,当内部某个成员出现故障时,可以将服务切换到其他正常的成员服务器上。在HA中一个失效域一般包含2台成员服务器(未应用虚拟技术)。
4、心跳(HeartBeat)是HA中监控成员服务器状态的方法,一般心跳是通过网线和串口线来传输的。
5、单一故障点(Single Point Of Failuer,SPOF)是指一个系统的这样的一个部件,当它失效或者停止运行,将导致整个系统不能工作。在HA中通常使用双电源,多网卡,双交换机等来避免SPOF。
6、仲裁(Quorum)是HA中为了准确的判断服务器及其提供的服务是否正常而采用的在共享磁盘中保存成员服务器信息的方法。共享的状态信息包括群集是否活跃。服务状态信息包括服务是否在运行以及哪个成员正在运行该服务。每个成员都检查这些信息来保证其它成员处于最新状态。在一个只有两个成员的群集中,每个成员都定期把一个时间戳和群集状态信息写入位于共享磁盘贮存区的两个共享群集分区上。要保证正确的群集操作,如果某成员无法在启动时写入主共享群集分区和屏蔽共享群集分区,它将不会被允许加入群集。此外,如果某群集成员不更新其时间戳,或者到系统的"heartbeats"(心跳)失败了,该成员就会从群集中删除。
7、Fence设备,Fence设备的作用时在一个节点出现问题时,另一个节点通过fence设备把出现问题的节点重新启动,这样做到了非人工的干预和防止出现问题的节点访问共享存储,造成文件系统的冲突,关于Fence 设备,有外置的比如APC的电源管理器.很多服务器都是内置的,只不过不同厂家的叫法不同而已。比如HP的称为iLo,IBM的称为BMC,Dell的称为DRAC。
LUCI——RHCS(RedHat Cluster Suite)提供了多种集群配置和管理工具,常用的有基于GUI的system-config-cluster、Conga等,也提供了基于命令行的管理工具。system-config-cluster是一个用于创建集群和配置集群节点的图形化管理工具,它有集群节点配置和集群管理两个部分组成,分别用于创建集群节点配置文件和维护节点运行状态。一般用在RHCS早期的版本中。 Conga是一种新的基于网络的集群配置工具,与system-config-cluster不同的是,Conga是通过web方式来配置和管理集群节点的。Conga有两部分组成,分别是luci和ricci,luci安装在一独立的计算机上(即服务器),用于配置和管理集群,ricci安装在每个集群节点上,Luci通过ricci和集群中的每个节点进行通信。
一、HA的搭建
实验环境:RHEL6.5 iptables and selinux disabled
三台主机: IP hostname
192.168.2.60(服务器) server60.example.com
192.168.2.167(node1) server67.example.com
192.168.2.168(node2) server68.example.com
分别修改两节点的/etc/hosts
192.168.2.167 server67.example.com
192.168.2.168 server68.example.com
关闭火墙#iptables -F
#service iptables save
关闭selinux #setenforce 0
同步两台主机的系统时间
#yum install ntpdate
#ntpdate 192.168.2.60
在两台节点主机上分别安装ricci
#yum install ricci
启动ricci服务
#service ricci start
设置为开机自启动
#chkconfig ricci on
为ricci设置密码
#passwd ricci
重启服务器的luci
#service luci restart
Stop luci... [ OK ]
Start luci... [ OK ]
Point your web browser to https://server60.example.com:8084 (or equivalent) to access luci
web访问https://server60.example.com:8084/cluster/
进入网页编辑
先用root登录

再用本地用户登录
再用root登录时点击右上角Admin,为普通用户lee授权

这时候就可以创建集群



这时,两节点主机将会重启。这就是为什么把ricci服务设置为开机自启动且将iptables关闭的原因。
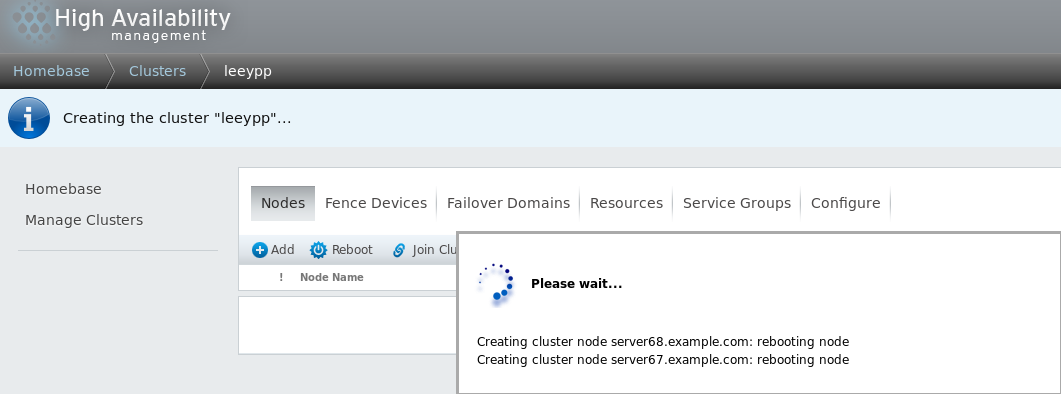

创建完成会自动在节点上写入文件/etc/cluster/cluster.conf
<?xml version="2.0"?>
<cluster config_version="1" name="leeypp">
<clusternodes>
<clusternode name="server67.example.com" nodeid="1"/>
<clusternode name="server68.example.com" nodeid="2"/>
</clusternodes>
<cman expected_votes="1" two_node="1"/>
<fencedevices/>
<rm/>
</cluster>
二、fence device 隔离设备
用kvm虚拟机来做这个隔离设备
实验环境:RHEL6 selinux and iptables disabled
主机:KVM虚拟机
hostname ip kvm domain name
node1 192.168.2.137 vm1
node2 192.168.2.138 vm2
192.168.2.60 服务器
#yum install fence-virt fence-virtd fence-virtd-libvirt fence-virtd-multicast -y
# fence_virtd -c 设置隔离设备
Module search path [/usr/lib64/fence-virt]:
Available backends:
libvirt 0.1
Available listeners:
multicast 1.0
Listener modules are responsible for accepting requests
from fencing clients.
Listener module [multicast]:
The multicast listener module is designed for use environments
where the guests and hosts may communicate over a network using
multicast.
The multicast address is the address that a client will use to
send fencing requests to fence_virtd.
Multicast IP Address [225.0.0.12]:
Using ipv4 as family.
Multicast IP Port [1229]:
Setting a preferred interface causes fence_virtd to listen only
on that interface. Normally, it listens on all interfaces.
In environments where the virtual machines are using the host
machine as a gateway, this *must* be set (typically to virbr0).
Set to ‘none‘ for no interface.
Interface [none]: br0
The key file is the shared key information which is used to
authenticate fencing requests. The contents of this file must
be distributed to each physical host and virtual machine within
a cluster.
Key File [/etc/cluster/fence_xvm.key]:
Backend modules are responsible for routing requests to
the appropriate hypervisor or management layer.
Backend module [libvirt]:
The libvirt backend module is designed for single desktops or
servers. Do not use in environments where virtual machines
may be migrated between hosts.
Libvirt URI [qemu:///system]:
Configuration complete.
=== Begin Configuration ===
backends {
libvirt {
uri = "qemu:///system";
}
}
listeners {
multicast {
key_file = "/etc/cluster/fence_xvm.key";
interface = "br0";
port = "1229";
address = "225.0.0.12";
family = "ipv4";
}
}
fence_virtd {
backend = "libvirt";
listener = "multicast";
module_path = "/usr/lib64/fence-virt";
}
=== End Configuration ===
Replace /etc/fence_virt.conf with the above [y/N]? y
注:以上设置除“Interface”处填写虚拟机通信接口外,其他选项均可回车保持默认。
#dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
#scp /etc/cluster/fence_xvm.key 192.168.2.138:/etc/cluster(该目录默认是不存在的,可用mkdir来创建)
#scp /etc/cluster/fence_xvm.key 192.168.2.137:/etc/cluster
#service fence_virtd start
#chkconfig fence_virtd on
# netstat -anulp |grep fence
udp 0 0 0.0.0.0:1229 0.0.0.0:* 7519/fence_virtd
#cd /etc/cluster
查看是否存在fence_virtd文件
现在在网页管理上添加隔离设备

在domain后添加server37主机的uuid

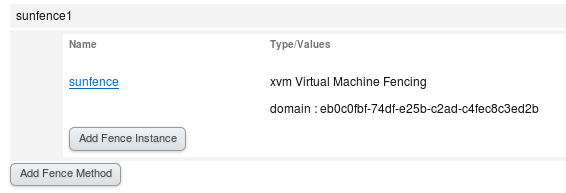

在domain后添加server38主机的uuid


#fence_xvm -H vm1 看看是否可以操作你的虚拟机,如果成功,vm1将会重启。
且另一个节点会热接管
设置两节点的下列服务为开机自启动:
#chkconfig cman on
#chkconfig rgmanager on
#chkconfig modclusterd on
#chkconfig clvmd on
设置故障转移域(failover domains)

添加资源(resourses)
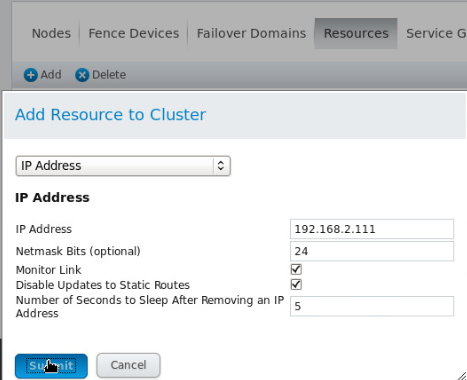
(该IP不为其他主机所用)
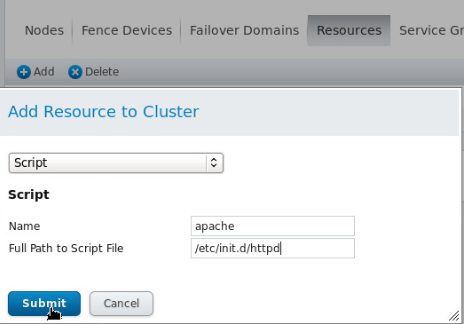
添加成功之后

添加服务组(Server Groups)


在节点上执行的命令
#clusvcadm -d www 关闭此服务组
#clustat 查看节点和服务的状态
#clusvcadm -e www 开启此服务组
刚刚添加了apache服务,所以要在每个节点上安装apache服务
#yum install -y httpd
为了区分两台内容可以重新编辑一下默认访问主页
#cd /var/www/html/
#echo `hostname` > index.html
ok现在可以在web网页上访问
http://192.168.2.111就有主机名
刚刚添加的那个ip服务,它是一个浮动ip
192.168.2.111就可以看到你做的那个优先级高的再接管服务
如果将这个节点上的http关掉,那么那个优先级低的候补立马接管
如果ifconfig eth0 down 是这个节点的网可关掉,它会尝试恢复,如果恢复不了,就会被集群forceoff,然后重启当替补,如果优先级高的话,那么它就会立即接管给集群管理加存储服务
三、给集群管理加存储服务
1.ext4文件系统
192.168.0.237(节点)server67.example.com
192.168.0.248(节点)server68.example.com
192.168.0.60(服务器)server60.example.com
在一个存储服务器上共享一块硬盘,作为存储(在实验中,就直接在集群管理的那台服务器上共享一块硬盘)
#yum install scsi-*
#vgs
#lvcreate -L 1G -n iscsi cinder-volumes
#lvs
#vim /etc/tgt/targets.conf

#/etc/init.d/tgtd start
#chkconfig tgtd on
#tgt-admin -s
#在节点上要可以发现这个共享的存储设备 ,在两个节点上都执行
#yum install iscsi-initiator-utils
#iscsiadm -m discovery -t st -p 192.168.0.60
#iscsiadm -m node -l 激活设备
#fdisk -l /dev/sda
现在在两个节点上给此设备做 分区和格式化 (做本地文件系统 ext4)
#fdisk -cu /dev/sda


#mkfs.ext4 /dev/sda1

在web管理界面上添加存储设备资源和资源组

再去资源组(Server Groups)添加此资源

ok现在操作服务组
#clustat

#clusvcadm -d www
现在将此设备先挂载到/var/www/html下

启动服务
#clusvcadm -e www
#clustat 查看服务是否启动成功
#clusvcadm -r www -m server38.example.com
#clustat 这是会发现www运行在server38主机上
2.设备的分区和格式化 (即网络文件系统 gfs2)
clusvcadm -d www 先停掉服务组
删掉服务组里(servies groups)的文件系统(filesystem)资源,再到资源里删掉(delete)存储设备资源

fdisk -cu /dev/sda 把它做成LVM形式
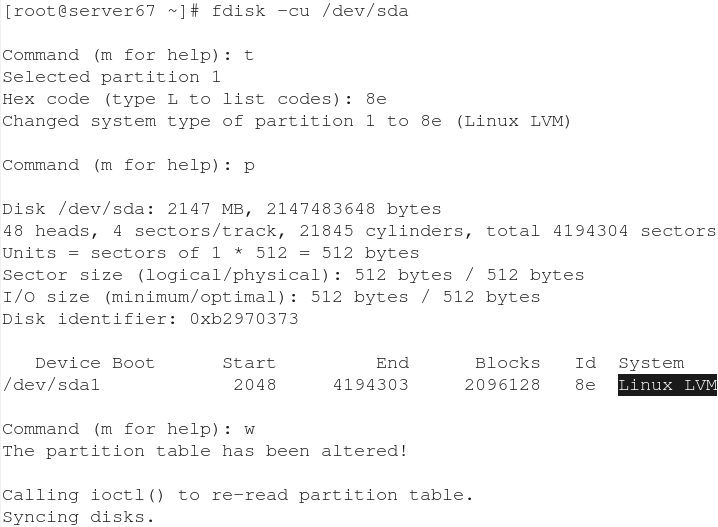
这时在另一节点主机上运行pvs就可以看到刚创建的
pvcreate /dev/sda1
lvmconf --enble-cluster 在 /etc/lvm/lvm.conf做更改,使它可以支持集群
重启服务 /etc/init.d/clvmd restart

在另一节点主机上运行lvs,可以看见同步到的gfs2demo
格式化为gfs2的格式 -t跟更集群的名字:后是标签

两节点主机都进行挂载
# mount /dev/clustervg/gfs2demo /var/www/html
设置为开机自动挂载 直接写入/etc/fstab文件, 在所有节点都做这个操作
查看系统设备信息

vim /etc/fstab

现在mount -a 刷此文件,同时挂载
cd /var/www/html
vim index.html 写东西来进行web测试
web访问集群
192.168.0.111可以看到index.html文件里写入的内容
ok现在开启服务组
clusvcadm -e www
clusvcadm -d www 先停掉服务组
在web管理上面添加
在/etc/fstab中注释掉gfs2设备的挂载 ,解挂
现在在资源加存储设备资源,集群管控添加服务组


ok现在开启服务组
clusvcadm -e www
现在哪个节点工作,那个节点挂载
前提:clusvcadm -d www 删掉原来的存储设备
lvs
vgs
vgremove clustervg
lvs
pvs
pvremove /dev/sda1
iscsiadm -m node -u
iscsiadm -m node -o delete