
首页 > 代码库 > 1_大端模式和小端模式
1_大端模式和小端模式
转自-http://blog.csdn.net/hackbuteer1/article/details/7722667
在 各种计算机体系结构中,对于字节、字等的存储机制有所不同,因而引发了计算机 通信领 域中一个很重要的问题,即通信双方交流的信息单元(比特、字节、字、双字等等)应该以什么样的顺序进行传送。如果不达成一致的规则,通信双方将无法进行正 确的编/译码从而导致通信失败。目前在各种体系的计算机中通常采用的字节存储机制主要有两种:Big-Endian和Little-Endian,下面先从字节序说起。
一、什么是字节序
字节序,顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了)。其实大部分人在实际的开 发中都很少会直接和字节序打交道。唯有在跨平台以及网络程序中字节序才是一个应该被考虑的问题。
在所有的介绍字节序的文章中都会提到字 节序分为两类:Big-Endian和Little-Endian,引用标准的Big-Endian和Little-Endian的定义如下:
a) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
b) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
c) 网络字节序:TCP/IP各层协议将字节序定义为Big-Endian,因此TCP/IP协议中使用的字节序通常称之为网络字节序。
1.1 什么是高/低地址端
首先我们要知道C程序映像中内存的空间布局情况:在《C专 家编程》中或者《Unix环境高级编程》中有关于内存空间布局情况的说明,大致如下图:
----------------------- 最高内存地址 0xffffffff
栈底
栈
栈顶
-----------------------
NULL (空洞)
-----------------------
堆
-----------------------
未初始 化的数据
----------------------- 统称数据段
初始化的数据
-----------------------
正 文段(代码段)
----------------------- 最低内存地址 0x00000000
由图可以看出,再内存分布中,栈是向下增长的,而堆是向上增长的。
以上图为例如果我们在栈 上分配一个unsigned char buf[4],那么这个数组变量在栈上是如何布局的呢?看下图:
栈底 (高地址)
----------
buf[3]
buf[2]
buf[1]
buf[0]
----------
栈顶 (低地址)
其实,我们可以自己在编译器里面创建一个数组,然后分别输出数组种每个元素的地址,来验证一下。
1.2 什么是高/低字节
现在我们弄清了高/低地址,接着考虑高/低字节。有些文章中称低位字节为最低有效位,高位字节为最高有效位。如果我们有一个32位无符号整型0x12345678,那么高位是什么,低位又是什么呢? 其实很简单。在十进制中我们都说靠左边的是高位,靠右边的是低位,在其他进制也是如此。就拿 0x12345678来说,从高位到低位的字节依次是0x12、0x34、0x56和0x78。
高/低地址端和高/低字节都弄清了。我们再来回顾 一下Big-Endian和Little-Endian的定义,并用图示说明两种字节序:
以unsigned int value = http://www.mamicode.com/0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下图:
栈底 (高地址)
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
栈顶 (低地址)
Little-Endian: 低地址存放低位,如下图:
栈底 (高地址)
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
--------------
栈 顶 (低地址)
二、各种Endian
2.1 Big-Endian
计算机体系结构中一种描述多字节存储顺序的术语,在这种机制中最重要字节(MSB)存放在最低端的地址 上。采用这种机制的处理器有IBM3700系列、PDP-10、Mortolora微处理器系列和绝大多数的RISC处理器。
+----------+
| 0x34 |<-- 0x00000021
+----------+
| 0x12 |<-- 0x00000020
+----------+
图 1:双字节数0x1234以Big-Endian的方式存在起始地址0x00000020中
在Big-Endian中,对于bit序列 中的序号编排方式如下(以双字节数0x8B8A为例):
bit 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+----------------------------------------+
图 2:Big-Endian的bit序列编码方式
2.2 Little-Endian
计算机体系结构中 一种描述多字节存储顺序的术语,在这种机制中最不重要字节(LSB)存放在最低端的地址上。采用这种机制的处理器有PDP-11、VAX、Intel系列微处理器和一些网络通信设备。该术语除了描述多字节存储顺序外还常常用来描述一个字节中各个比特的排放次序。
+----------+
| 0x12 |<-- 0x00000021
+----------+
| 0x34 |<-- 0x00000020
+----------+
图3:双字节数0x1234以Little-Endian的方式存在起始地址0x00000020中
在 Little-Endian中,对于bit序列中的序号编排和Big-Endian刚好相反,其方式如下(以双字节数0x8B8A为例):
bit 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
+-----------------------------------------+
val | 1 0 0 0 1 0 1 1 | 1 0 0 0 1 0 1 0 |
+-----------------------------------------+
图 4:Little-Endian的bit序列编码方式
注意:通常我们说的主机序(Host Order)就是遵循Little-Endian规则。所以当两台主机之间要通过TCP/IP协议进行通信的时候就需要调用相应的函数进行主机序 (Little-Endian)和网络序(Big-Endian)的转换。
采用 Little-endian模式的CPU对操作数的存放方式是从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。 32bit宽的数0x12345678在Little-endian模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
内存地址 0x4000 0x4001 0x4002 0x4003
存放内容 0x78 0x56 0x34 0x12
而在Big- endian模式CPU内存中的存放方式则为:
内存地址 0x4000 0x4001 0x4002 0x4003
存放内容 0x12 0x34 0x56 0x78
具体的区别如下:
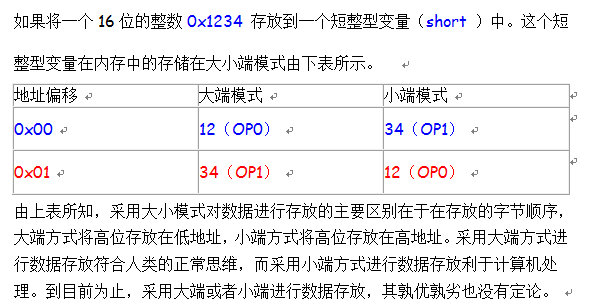
三、Big-Endian和Little-Endian优缺点
Big-Endian优点:靠首先提取高位字节,你总是可以由看看在偏移位置为0的字节来确定这个数字是 正数还是负数。你不必知道这个数值有多长,或者你也不必过一些字节来看这个数值是否含有符号位。这个数值是以它们被打印出来的顺序存放的,所以从二进制到十进制的函数特别有效。因而,对于不同要求的机器,在设计存取方式时就会不同。
Little-Endian优点:提取一个,两个,四个或者更长字节数据的汇编指令以与其他所有格式相同的方式进行:首先在偏移地址为0的地方提取最低位的字节,因为地址偏移和字节数是一对一的关系,多重精度的数学函数就相对地容易写了。
如果你增加数字的值,你可能在左边增加数字(高位非指数函数需要更多的数字)。 因此, 经常需要增加两位数字并移动存储器里所有Big-endian顺序的数字,把所有数向右移,这会增加计算机的工作量。不过,使用Little- Endian的存储器中不重要的字节可以存在它原来的位置,新的数可以存在它的右边的高位地址里。这就意味着计算机中的某些计算可以变得更加简单和快速。
四、请写一个C函数,若处理器是Big_endian的,则返回0;若是Little_endian的,则返回1。
- int checkCPU(void)
- {
- union
- {
- int a;
- char b;
- }c;
- c.a = 1;
- return (c.b == 1);
- }
剖析:由于联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性就可以轻松地获得了CPU对内存采用Little- endian还是Big-endian模式读写。
说明:
1 在c中,联合体(共用体)的数据成员都是从低地址开始存放。
2 若是小端模式,由低地址到高地址c.a存放为0x01 00 00 00,c.b被赋值为0x01;
————————————————————————————
地址 0x00000000 0x00000001 0x00000002 0x00000003
c.a 01 00 00 00
c.b 01 00
————————————————————————————
3 若是大端模式,由低地址到高地址c.a存放为0x00 00 00 01,c.b被赋值为0x0;
————————————————————————————
地址 0x00000000 0x00000001 0x00000002 0x00000003
c.a 00 00 00 01
c.b 00 00
————————————————————————————
4 根据c.b的值的情况就可以判断cpu的模式了。
举例,一个16进制数是 0x11 22 33,其存放的位置是
地址0x3000 中存放11
地址0x3001 中存放22
地址0x3002 中存放33
连起来就写成地址0x3000-0x3002中存放了数据0x112233
而这种存放和表示方式,正好符合大端。
另外一个比较好理解的写法如下:
- bool checkCPU() // 如果是大端模式,返回真
- {
- short int test = 0x1234;
- if( *((char *)&test) == 0x12) // 低地址存放高字节数据
- return true;
- else
- return false;
- }
- int main(void)
- {
- if( !checkCPU())
- cout<<"Little endian"<<endl;
- else
- cout<<"Big endian"<<endl;
- return 0;
- }
或者下面两种写法也是可以的
- int main(void)
- {
- short int a = 0x1234;
- char *p = (char *)&a;
- if( *p == 0x34)
- cout<<"Little endian"<<endl;
- else
- cout<<"Big endian"<<endl;
- return 0;
- }
- int main(void)
- {
- short int a = 0x1234;
- char x0 , x1;
- x0 = ((char *)&a)[0];
- x1 = ((char *)&a)[1];
- if( x0 == 0x34)
- cout<<"Little endian"<<endl;
- else
- cout<<"Big endian"<<endl;
- return 0;
- }

1_大端模式和小端模式