
首页 > 代码库 > HashMap的工作原理
HashMap的工作原理
1.前言
在探讨HashMap源码之前,先说一下HashCode,为什么呢?因为HashMap有一个特性是Key是唯一值,如何确定key的唯一性呢,这就用到了hash算法。在HashMap(jdk1.7)的put方法实现中首先利用了hash()生成key的hashCode,然后比较key的hashCode是否已经存在集合,如果不存在,就插入到集合,如果已存在,则返回null。
1.1 hashCode方法和equals方法比较
为什么用HashCode比较比用equals方法比较要快呢?我们要想比较hashCode与equals的性能,得先了解HashCode是什么。HashCode是jdk根据对象的地址或字符串或者数字利用hash算法计算出的int类型的数值。Java采用了哈希表的原理,将数据依照特定算法直接指定到一个地址上,这样可以简单的理解为hashCode方法返回的就是对象存储位置的映像。因此HashCode能够快速的定位对象所在的地址,并且根据Hash常规协定,如果两个对象相等,则他们一定有相同的HashCode。而equals方法对比两个对象实例是否相等时,对比的就是对象示例的ID(内存地址)是否是同一个对象实例;该方法是利用的等号(==)的判断结果。所以HashCode的效率远远大于equals
但是HashCode并不保证唯一性,因此当对象的HashCode相同时,再利用equals方法来判断两个对象是否相同,就大大加快了对比的速度。
1.2 java对象比较方法总结
等号(==):对比对象实例的内存地址来判断是否是同一对象实例;也可以说是判断对象实例是否物理相等。
equals():当对象没有重写Object的equals方法时,equals方法判断的是对象实例的ID,也就是内存地址,是否是同一对象实例;该方法就是使用等号(==)的判断结果。Object类的源码如下:
public boolean equals(Object obj) {
return (this == obj);
}当对象所属的类重写equals方法时,要根据自身逻辑来判断是否相等。
hashCode():根据对象的地址或字符串或者数字等计算出对象实例的哈希码。可以简单的说,hashCode比较的是对象的内存地址。
1.3 为什么要hash算法
Hash算法一般也被称为散列算法,通过散列算法将任意的值转化成固定的长度输出,该输出就是散列值,这是一种压缩映射,也就是,散列值的空间远远小于输入的值空间。
简单的说,hash算法的意义在于提供了一种快速存取数据的方法,它用一种算法建立键值与真实值之间的对应关系,(每一个真实值只能有一个键值,但是一个键值可以对应多个真实值),这样可以快速在数组等里面存取数据。HashMap就是采用了Hash算法来实现快速存取数据。
注意:jdk1.8版本对HashMap改动很大,jdk1.7之前的版本,HashMap采用的是链表+位桶的方式,也就是我们经常说的散列表的方式,但是在jdk1.8版本中,HashMap采用的是位桶+链表/红黑树的方式,也是非线程安全的。当某个位桶的链表的长度到达某个阈值的时候,这个链表就转化为红黑树。
2.HashMap(JDK1.6)简介
2.1.HashMap是什么
HashMap基于哈希表的 Map 接口的实现。此实现提供所有可选的Map操作,并允许使用 null 值和 null 键。(除了非同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
HashMap的实例有两个参数影响其性能:初始容量和加载因子。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行rehash操作(重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常默认加载因子(.75)在时间和空间成本上寻求一种折衷。加载因子过高虽然减小了空间开销,但是同时也增加了查询成本。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少rehash操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生rehash操作。
如果很多映射关系要存储到HashMap实例中,则相对于按需执行自动的rehash操作以增大表的容量来说,使用足够大的初始化容量创建它将使得映射关系能够更有效的存储。
注意,此实现不是同步。如果多个线程同时访问同一个HashMap,而其中至少一个线程从结构上修改了该映射(增删映射关系),则它必须保持外部同步。这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用Collections.synchronizedMap方法来“包装”该映射。最好在创建时完成这一操作,防止对映射进行意外的非同步访问,示例代码如下:
private static Map<String, CbossHomeDuplicateConfigDataModule> cbossHomeDuplicateConfigMap = Collections.synchronizedMap(new HashMap<String, CbossHomeDuplicateConfigDataModule>()); //这样能够面对并发的修改时,迭代器很快就完全失败,就避免了在不确定的时间发生任意不确定行为的风险。
但是,虽然有Collections.synchronizedMap方法来规避风险,但是还是应该尽量避免在并发程序中使用HashMap.可以考虑使用current包下的ConcurrentHashMap。
2.2.HashTable是什么
很多时候HashMap与HashTable都纠缠到一起。特别是面试的时候就会HashMap和HashTable的区别。那么HashTable是什么?哈希表(Hashtable)又称为“散置”,Hashtable是会根据索引键的哈希程序代码组织成的索引键(Key)和值(Value)配对的集合。Hashtable 对象是由包含集合中元素的哈希桶(Bucket)所组成的。而Bucket是Hashtable内元素的虚拟子群组,可以让大部分集合中的搜寻和获取工作更容易、更快速。
2.3.HashMap和HashTable的区别
我们都知道HashMap和HashTable的主要区别就是:
- HashMap是非线程同步的,HashTable是线程同步的。
- HashMap允许null作为键或者值,HashTable不允许
- HashTable中有个一个contains方法,HashMap去掉了此方法
- 效率上来讲,HashMap因为是非线程安全的,因此效率比HashTable高
从定义上看,hashTable继承Dictionary,而HashMap继承Abstract
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializablepublic class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable从实现上看,hashTable的put方法实现了同步,而hashMap没有
hashMap的put、get方法源码:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = http://www.mamicode.com/e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}hashTable的put()、get()方法源码:
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<K,V>(hash, key, value, e);
count++;
return null;
}
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}从源码中可以看出hashTable实现了synchronized,并不允许null作为键值。
2.4 HashMap的存储结构
HashMap的数据结构是基于数组和链表的。数组和链表是数据结构的基本组成。但是这两个都有很大的弊端:
- 数组的存取区间是连续的,占用内存严重,因此空间复杂度很大。但是数组的二分查找事件复杂度小为O(1);数组的特点是:寻址容易,插入和删除困难
- 链表的存储区间离散,占用内存比较松散,因此空间复杂度很小,单事件复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易
鉴于此种情况,为寻求寻址容易且插入和删除操作也都容易的数据结构。哈希表应运而生。哈希表的存储结构:
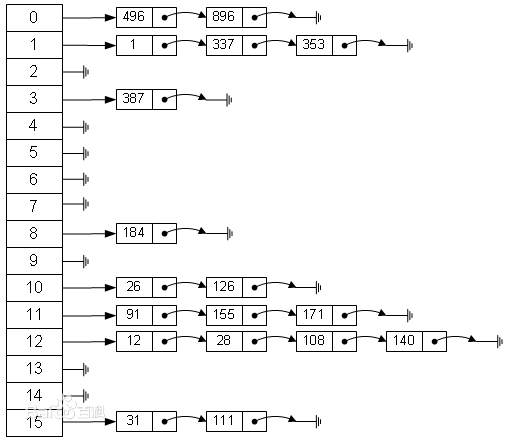
由上图可以看出哈希表是一个数组+链表的存储结构。HashMap存储结构文字解释:
元素0 →[hashCode=1,Entry<K,V>]
元素1 →[hashCode=2,Entry<K,V>]
...
依次类推
2.5 HashMap的数据结构
java.lang.Object
? java.util.AbstractMap<K, V>
? java.util.HashMap<K, V>
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable { }- HashMap继承AbstractMap类,实现了Map接口(AbstractMap已经实现了Map接口,不明白为什么HashMap要再次实现Map接口)。
- Java的HashMap是通过“拉链法”实现的哈希表。包括table、size、threshold、loadFactor和modCount。其中table是一个Entry[]数组类型,而Entry实际上是一个单向链表。哈希表的“key-value键值对”都是存放在Entry数组中。size是HashMap的大小,它是HashMap保存的键值对的数量。threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold = “容量 * 加载因子”,当HashMap中存储数据的数量达到threshold值时,就需要rehash,将HashMap容量扩展到原来的2倍。loadFactor就是加载因子。modCount用来实现fail-fast机制。
3.源码解析HashMap
为了更了解HashMap的工作原理,下面对HashMap的源码做出解析。
3.1.HashMap对HashCode碰撞的处理
Java中HashMap是利用“拉链法”处理HashCode的碰撞问题。在调用HashMap的put方法或get方法时,都会首先调用hashcode方法,去查找相关的key,当有冲突时,再调用equals方法。hashMap基于hasing原理,我们通过put和get方法存取对象。当我们将键值对传递给put方法时,他调用键对象的hashCode()方法来计算hashCode,然后找到bucket(哈希桶)位置来存储对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当碰撞发生了,对象将会存储在链表的下一个节点中。hashMap在每个链表节点存储键值对对象。当两个不同的键却有相同的hashCode时,他们会存储在同一个bucket位置的链表中。键对象的equals()来找到键值对。HashMap的put和get方法源码如下:
/**
* Returns the value to which the specified key is mapped,
* or if this map contains no mapping for the key.
*
* 获取key对应的value
*/
public V get(Object key) {
if (key == null)
return getForNullKey();
//获取key的hash值
int hash = hash(key.hashCode());
// 在“该hash值对应的链表”上查找“键值等于key”的元素
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
/**
* Offloaded version of get() to look up null keys. Null keys map
* to index 0.
* 获取key为null的键值对,HashMap将此键值对存储到table[0]的位置
*/
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
/**
* Returns <tt>true</tt> if this map contains a mapping for the
* specified key.
*
* HashMap是否包含key
*/
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
/**
* Returns the entry associated with the specified key in the
* HashMap.
* 返回键为key的键值对
*/
final Entry<K,V> getEntry(Object key) {
//先获取哈希值。如果key为null,hash = 0;这是因为key为null的键值对存储在table[0]的位置。
int hash = (key == null) ? 0 : hash(key.hashCode());
//在该哈希值对应的链表上查找键值与key相等的元素。
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* 将“key-value”添加到HashMap中,如果hashMap中包含了key,那么原来的值将会被新值取代
*/
public V put(K key, V value) {
//如果key是null,那么调用putForNullKey(),将该键值对添加到table[0]中
if (key == null)
return putForNullKey(value);
//如果key不为null,则计算key的哈希值,然后将其添加到哈希值对应的链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果这个key对应的键值对已经存在,就用新的value代替老的value。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = http://www.mamicode.com/e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}从HashMap的put()和get方法实现中可以与拉链法解决hashCode冲突解决方法相互印证。并且从put方法中可以看出HashMap是使用Entry<K,V>来存储数据。数据节点Entry的数据结构如下:
// Entry是单向链表。
// 它是 “HashMap链式存储法”对应的链表。
// 它实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
//指向下一个节点
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
* 输入参数包括"哈希值(h)", "键(k)", "值(v)", "下一节点(n)"
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = http://www.mamicode.com/v;"hljs-function">public final K getKey() 从这段代码中,我们可以看出Entry是一个单向链表,这也是我们为什么说HashMap是通过拉链法解决hash冲突的原因。Entry实现了Map.Entry接口。
3.2 HashMap的构造函数
HashMap共包括4个构造函数
// 默认构造函数。构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap
public HashMap() {
// 设置“加载因子”
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
// 创建Entry数组,用来保存数据
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
// 构造一个带指定初始容量和加载因子的空 HashMap。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// HashMap的最大容量只能是MAXIMUM_CAPACITY
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// 设置“加载因子”
this.loadFactor = loadFactor;
// 设置“HashMap阈值”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
threshold = (int)(capacity * loadFactor);
// 创建Entry数组,用来保存数据
table = new Entry[capacity];
init();
}
// 构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 构造一个映射关系与指定 Map 相同的新 HashMap。
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
// 将m中的全部元素逐个添加到HashMap中
putAllForCreate(m);
}3.3 hashMap的主要方法
hashMap的主要方法| public int size():返回此映射中的键-值映射关系数 |
| public void clear():从此映射中移除所有映射关系。此调用返回后,映射将为空。 |
| public boolean containsValue(Object value):如果此映射将一个或多个键映射到指定值,则返回 true。 |
| public boolean containsKey(Object key):如果此映射包含对于指定键的映射关系,则返回 true。 |
| public V put(K key,V value):在此映射中关联指定值与指定键。如果该映射以前包含了一个该键的映射关系,则旧值被替换。 |
| public void putAll(Map<? extendsK,? extends V> m):将指定映射的所有映射关系复制到此映射中,这些映射关系将替换此映射目前针对指定映射中所有键的所有映射关系。 |
| public V get(Object key):返回指定键所映射的值;如果对于该键来说,此映射不包含任何映射关系,则返回null。 |
public Set<K>keySet():返回此映射中所包含的键的 Set 视图。它不支持 add 或 addAll 操作。 |
public Set<Map.Entry<K,V>>entrySet():返回此映射所包含的映射关系的 Set 视图 |
public boolean isEmpty():如果此映射不包含键-值映射关系,则返回 true。 |
put方法详解:(put方法源码,请见3.1)。put()的作用是对外提供接口,让hashMap对象可以通过put()将“key-value”添加到HashMap中。由源码可以看出若要添加到HashMap中的键值对对应的key已经存在HashMap中,则找到该键值对;然后新的value取代旧的value,并退出!若要添加到HashMap中的键值对对应的key不在HashMap中,则将其添加到该哈希值对应的链表中,并调用addEntry()。addEntry的作用是新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。addEntry的代码如下:
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}说到addEntry,就不得不提一下createEntry。createEntry代码如下:
// 创建Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
// 它和addEntry的区别是:
// (01) addEntry()一般用在 新增Entry可能导致“HashMap的实际容量”超过“阈值”的情况下。
// 例如,我们新建一个HashMap,然后不断通过put()向HashMap中添加元素;
// put()是通过addEntry()新增Entry的。
// 在这种情况下,我们不知道何时“HashMap的实际容量”会超过“阈值”;
// 因此,需要调用addEntry()
// (02) createEntry() 一般用在 新增Entry不会导致“HashMap的实际容量”超过“阈值”的情况下。
// 例如,我们调用HashMap“带有Map”的构造函数,它绘将Map的全部元素添加到HashMap中;
// 但在添加之前,我们已经计算好“HashMap的容量和阈值”。也就是,可以确定“即使将Map中
// 的全部元素添加到HashMap中,都不会超过HashMap的阈值”。
// 此时,调用createEntry()即可。
void createEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
size++;
}写不动了……其他的方法,你们自己根据源码和JDKAPI文档研究下吧
3.4 hashMap的遍历方式
3.4.1 遍历hashMap的键值对
【1】根据entrySet()获取HashMap的键值对的Set集合
【2】通过Iterator迭代器遍历Set集合
3.4.2 遍历HashMap的键
【1】根据keySet()获取HashMap的键的Set集合
【2】通过Iterator迭代器遍历Set集合
3.4.3遍历HashMap的值
【1】根据value()获取HashMap的“值”集合
【2】通过Iterator迭代器遍历集合
4 关于hashMap的其他问题
- 为什么String, Interger这样的wrapper类适合作为键?HashMap的键尽量使用String、Integer这样的wrapper类。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
- 我们可以使用自定义的对象作为键吗?我们可以利用自己的对象作为键,只要它遵守了equals()和hashCode()方法的定义规则。
- 我们可以使用CocurrentHashMap来代替Hashtable吗?我们知道Hashtable是synchronized的,但是ConcurrentHashMap同步性能更好,因为它仅仅根据同步级别对map的一部分进行上锁。ConcurrentHashMap当然可以代替HashTable,但是HashTable提供更强的线程安全性。
- 多线程条件下,重调整hashMap大小会出现什么问题?当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
5.总结
HashMap的工作原理
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表(拉链法)来解决hashCode碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。如果两个不同的键对象的hashCode相同,那么它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。由于HashMap的种种好处,我们经常可以利用hashMap作为缓存
HashMap的工作原理