
首页 > 代码库 > Unity加载模块深度解析(Shader)
Unity加载模块深度解析(Shader)
链接:https://zhuanlan.zhihu.com/p/21949663
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
接上一篇 加载模块深度解析(二),我们重点讨论了网格资源的加载性能。今天,我们再来为你揭开Shader资源的加载效率。
这是侑虎科技第59篇原创文章,欢迎转发分享,未经作者授权请勿转载。同时如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。(QQ群465082844)
资源加载性能测试代码
与上篇所提出的测试代码一样,我们对于Shader资源的加载性能分析同样使用该测试代码。同时,我们将Shader文件制作成一定大小的AssetBundle文件,并逐一通过以下代码在不同设备上进行加载,以期得到相应的资源加载性能比较。

测试环境
引擎版本:Unity 5.2版本
测试设备:三台不同档次的移动设备(Android:红米2、红米Note2和三星S6)
Shader资源
Shader资源与之前的网格资源和纹理资源不同,其本身物理Size很小。一般来说,一个Shader资源的物理Size仅几KB,在内存中也不过几十KB。所以,Shader资源的效率加载瓶颈并不在其自身大小的加载上,而是在Shader内容的解析上。因此,我们在本文中选择四种大家项目中最常使用的Shader资源,来让大家更好地了解Shader资源加载的具体开销。
测试1:不同种类的Shader资源加载效率测试
我们选取了四种当前项目中最为常用的Shader资源,它们分别是Mobile-Diffuse,Mobile-VertexLit,Mobile-Bumped Diffuse和Mobile-Particles Additive 。四组网格资源的内存占用分别为93KB、115KB、110KB和6.9KB,其对应AssetBundle大小为10KB、7KB、12KB和3KB(LZMA压缩)。
我们在三种不同档次的机型上加载这些网格资源,为降低偶然性,每台设备上重复进行十次加载操作并将取其平均值作为最终性能开销。具体测试结果如下表所示。

通过上述测试,我们可以得到以下结论:
1、Shader资源的物理体积与内存占用虽然很小,但其加载耗时开销的CPU占用很高,这主要是因为Shader的解析CPU开销很高,成为了Shader资源加载的性能瓶颈;
2、Mobile/Particles Additive在解析方面的耗时远小于Mobile/Diffuse、Mobile/Bumped Diffsue甚至Mobile/VertexLit;
3、除Mobile/Particles Additive外,其他三个主流Shader在加载时均会造成明显的降帧,甚至卡顿。因此,研发团队应尽可能避免在非切换场景时刻进行Shader的加载操作;
4、随着硬件设备性能的提升,其解析效率差异越来越不明显。
测试2:Mobile Shader vs. Normal Shader
在UWA性能测评报告中,我们发现项目中除使用Mobile Shader之外,也在大量使用Diffuse、Bumped Diffuse等Shader。二者之间在渲染方面的差别大家应该早已知道,那么在加载方面是否也存在一定的性能差距呢?
对此,我们进行了以下这组实验。我们在测试1中的Shader资源的基础上加入了与其对应的Normal Shader,并在三种测试设备上重复进行十次加载操作并将取其平均值作为最终性能开销,具体测试结果如下图所示。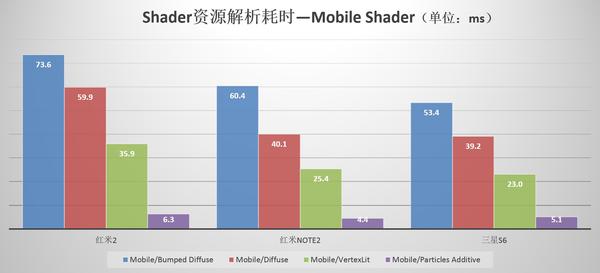

通过上述测试,我们可以得到以下结论:
1、Mobile Shader较之同种Normal Shader在加载方面确实有一定的性能提升;
2、设备性能越低,性能差距越大,比如Mobile/Bumped Diffuse和Bumped Diffuse的加载性能差距在红米2低端机上达到30ms+。
看到这里,想必大多数读者都会产生不小的惊讶,那就是几个小小的Shader,其加载耗时居然要高于几张Atlas纹理或者拥有上万片面的Mesh网格?!是的,没错,Shader的加载开销经常在几百甚至上千毫秒以上。
在UWA性能测评报告中,我们发现大量项目的Shader加载都占据了很大的性能开销。下图则为一款项目在运行过程中的Shader加载耗时情况。可以看出,在切换场景处,Shader加载达到上百毫秒的CPU占用,而在一般副本进行时,也会伴有几十毫秒的CPU耗时。这些对于运行帧率和场景切换效率都会有很大的影响。

那么,问题来了,我们该如何优化它呢?
在优化之前,我们首先要做的是了解Shader解析时的真正耗时原因。一般情况下,Shader加载的CPU耗时与其Keyword数量有关,Keyword数量越多,则加载开销也越大。通过Unity 5.x的Inspector可以看到,Mobile/Bumped Diffuse的Keyword变量数量为39,Mobile/Diffuse的Keyword变量数量为27,Mobile/VertexLit的Keyword变量数量为15,Mobile/Particles Additive的Keyword变量数量为1。类似的,在Unity 4.x中,Mobile/Bumped Diffuse的Keyword变量数量为44,Mobile/Diffuse的Keyword变量数量为25,Mobile/VertexLit的Keyword变量数量为6,Mobile/Particles Additive的Keyword变量数量为0。这也是Mobile/Particles Additive解析开销如此之低的主要原因。

注意:Shader的Keyword数量是会随着场景设置的不同而变化的。在Unity 5.x中,Unity默认会根据场景设置、Shader Pass等来调整Shader的Keyword,比如如果存在Lightmap的使用,则会默认将对应的Keyword打开,而对于没有使用Fog的项目,则会直接将相关Keyword关闭。
在了解了Keyword对于Shader加载效率的重要性之后,我们需要想办法来降低Shader的Keyword数量。对此,我们建议研发团队尝试以下方法:
方法一:
对于Unity 5.x项目,可通过skip_variants操作在Shader中直接去除相关Keyword。
举个例子,在Unity5.2版本中,默认情况下,Mobile/VertexLit的Keyword数量为15,如下图所示。可以看出在Shader片段#1中存在八个Keyword,对此,我们可以在对应的Shader代码中添加skip_variants操作将其去除,则去除后,Mobile/VertexLit的Keyword数量变为8,原来的8个Keyword不再使用,仅留下一个默认的。


由上可以看出,该方法可以有效降低Keyword的数量,但该方法同样有一定的局限,一是目前skip_variants操作仅能在Unity 5.0以上版本中使用,二是该方法需要研发团队对Shader具备一定程度的了解,可根据项目实际情况有针对性对Shader进行修改。
方法二:
直接去除Shader中的Fallback选项。Fallback功能是对于无法使用当前Shader的硬件设备可以使用对硬件设备要求更低的Fallback Shader来进行渲染,以保证渲染的稳定性。但是,就目前的移动市场而言,不支持Mobile/Diffuse和Mobile/Bumped Diffuse的设备已经相当少(或者说,我们目前还没遇到不支持Mobile/Diffuse Shader的设备反馈)。因此,对于使用Mobile Shader的项目,可以尝试直接将其FallBack去掉来大幅降低Keyword的数量。在我们的测试项目中,去掉FallBack功能,Mobile/Bumped Shader的Keyword从原来的39下降到12,Mobile/Diffuse的Keyword从原来的27下降到12。

该方法不会像“方法一”那样完全去除“无用”的Keyword,但该方法简单易用,只需一步操作,因此,性价比很高。同时,该方法完全支持Unity 4.x引擎的项目。
读到这里,你肯定会有一个疑问,即就算Keyword数量可以降下来,Shader的解析效率到底会有多大的提升呢?对此,我们进行了下面的实验:
测试3:开启/关闭Fallback功能的加载效率测试
为简单起见,我们直接关闭Mobile/Bumped Diffuse和Mobile/Diffuse的Fallback功能来制作一组对比数据。关闭Fallback后,这两个Shader的Keyword数量均为12,而原始Shader的Keyword为39和27。
与测试1相同,我们在三种不同档次的Android机型上重复进行十次加载操作并将取其平均值作为最终性能开销。具体测试结果如下图所示。
通过上述测试可以看出,Keyword的降低确实可以大幅降低Shader的解析时间,进而提升加载效率。
加载方式
以上我们通过具体实验展示和分析了Shader的加载性能、耗时成因和优化方法。在真实的项目研发过程中,大家还需要特别关注一点,那就是Shader的加载方式。正如下图看到的Shader加载情况,每次切换场景时,Shader加载均占用大量的CPU耗时,而实际上,这其实是大量相同Shader重复解析造成的。究其原因,是因为Shader被打包到不同的AssetBundle文件中,每次切换场景时,AssetBundle均会被频繁地进行加载和卸载,从而造成了大量相同的Shader被重复加载和卸载。
针对以上问题,如果你正在使用AssetBundle来加载资源,那么我们推荐的加载方式如下:
1、通过依赖关系打包,将项目中的所有Shader抽离并打成一个独立的AssetBundle文件,其他AssetBundle与其建立依赖;
2、Shader的AssetBundle文件在游戏启动后即进行加载并常驻内存,因为一款项目的Shader种类数量一般在50~100不等,且每个均很小,即便全部常驻内存,其内存总占用量也不会超过2MB;
3、后续Prefab加载和实例化后,Unity引擎会通过AssetBundle之间的依赖关系直接找到对应的Shader资源进行使用,而不会再进行加载和解析操作。
注意:对于Unity4.x版本,Shader的AssetBundle加载后只需LoadAll即可完成所有Shader的加载和解析,但对于Unity5.x版本,除执行LoadAllAssets操作外,还需要进行Shader.WarmupAllShaders操作,因为在Unity5.x版本中,Shader的解析和CreateGPUProgram操作是分离的。
对于Unity 5.x版本且正在使用Resources.Load来加载资源的研发团队,可以尝试使用ShaderVariantCollection来对Shader进行Preload,同样也可以达到避免相同Shader重复加载的效果。
注意:对于Unity5.x版本,如果可以通过AssetBundle来加载和解析Shader,则不建议通过ShaderVariantCollection来处理Shader的加载。在目前最新的Unity 5.3.5中,我们经过大量测试,发现ShaderVariantCollection在Shader的加载和管理中仍然存在一定的问题,我们暂时无法确定是否为引擎的问题,这已经不属于本篇文章的讨论范畴,在此不再赘述。
通过以上测试和分析,我们对于Shader资源的管理建议如下:
1、在保证渲染效果和项目需求的情况下,尽可能降低Shader的Keyword数量,以提升Shader的加载效率;
2、对于简单Shader,可尝试去除Fallback操作,该方法非常适合于目前正在大量使用的Mobile/Diffuse、Mobile/Bumped Diffuse等Built-in Shader;
3、尽可能对Shader进行单独、依赖关系打包并对其进行预加载,以降低后续不必要的加载开销。
以上为Shader资源在加载时的性能测试。关于加载模块的性能问题,我们会不断推出音频、动画片段等其他资源的加载性能分析、资源卸载性能分析、资源实例化性能分析、不同加载方式的性能分析等一系列技术文章,并对目前UWA所检测过项目的共性问题进行总结,以期让大家对项目的加载效率有更加深入的认知,并提升对加载模块的掌控能力。
Unity加载模块深度解析(Shader)