
首页 > 代码库 > --Hadoop相关零散知识点
--Hadoop相关零散知识点
Hadoop学习笔记:
1、Hadoop三种安装模式
本地模式:本地模式是Hadoop默认的模式,只有Hadoop被配置成以非分布式模式运行的一个独立Java进程。默认模式下所有3个XML文件均为空,此时,Hadoop会完全运行在本地。它只负责存储,没有计算功能。
伪分布式模式:伪分布式模式是在一台机器上模拟分布式部署,方便学习和调试。使用多个守护线程模拟分布的伪分布运行模式,此时每个Hadoop守护进程都作为一个独立的Java进程运行。
集群模式:真正多台机器来搭建分布式集群。
2、Hadoop集群--图解
Hadoop集群是在同一地点用网络互连的一组通用机器。数据存储和处理都发生在这个机器“云“中。不同的用户可以从独立的客户端提交计算“作业“到Hadoop,这些客户端可以是远离Hadoop集群的个人台式机。
注:虽非绝对必要,但通常在一个Hadoop集群中的机器都是相对同构的X86 Linux服务器。而且它们几乎总是位于同一个数据中心,并通常在同一组机架里。

3、机架结构图—图解
节点: H1、H2、H3、H4 … …
节点H1、H4、H7的机架名对应为:/D1/R1、/D1/R2、/D2/R3 … …
机架:R1、R2、R3 … …
数据中心:D1、D2

4、Hadoop集群架构——两级网络拓扑 P261

5、Hadoop集群节点的拓扑结构图解
这些拓扑结构的特点是:
在主节点上运行NameNode和JobTracker的守护进程,并使用独立的节点运行SecondaryNameNode以防主节点失效。在小型集群中,SecondaryNameNode(SNN)也可以驻留在某一个从节点上,而在大型集群中,连NameNode和JobTracker都会分别驻留在两台机器上。每个从节点均驻留一个DataNode和TaskTracker,从而在存储数据的同一个节点上执行任务。

6、MapReduce数据传输
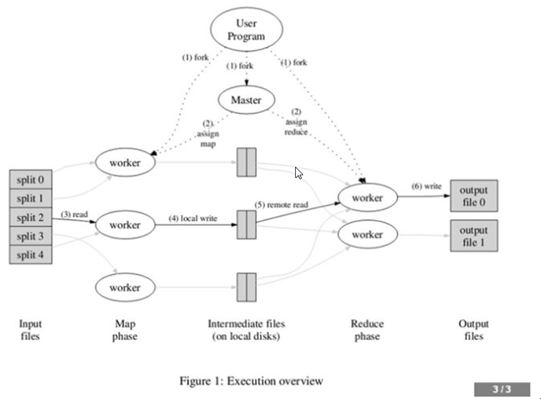
7、jobtracker及一系列tasktracker。
首先定义一些术语:
MapReduce作业(job)是客户端需要执行的一个工作单元。它包括输入数据、MapReduce程序和配置信息。Hadoop将作业分成若干个小任务(task)来执行,其中包括两类任务:map任务和reduce任务。
有两类节点控制着作业执行过程:
Jobtracker通过调度tasktracker上运行的任务,来协调所有运行在系统上的作业。
Tasktracker在运行任务的同时将运行进度报告发送给jobtracker,jobtracker由此记录每项作业任务的整体进度情况,如果其中一个任务失败,jobtracker可以在另外一个tasktracker节点上重新调度该任务。
8、输入分片
Hadoop将MapReduce的输入数据划分成等长的小数据块,成为输入分片(input spit)或简称分片,Hadoop为每个分片构建一个map任务,并由该任务来运行用户自定义的map函数从而处理分片中的每条记录。
拥有许多分片,意味着处理每个分片所需要的时间少于处理整个输入数据所花的时间。因此,如果我们并行处理每个分片,且每个分片数据比较小,那么整个处理过程将获得更好的负载平衡。因为一台较快的计算机能够处理的数据分片比一台较慢的计算机更多,且成一定的比例。即使使用相同的机器,处理失败的作业或其他同时运行的作业也能够实现负载平衡,并且如果分片被切分得更细,负载平衡的质量会更好。
另一方面,如果分片切分得太小,那么管理分片的总时间和构建map任务的总时间将决定着作业的整个执行时间。对于大多数作业来说,一个合理的分片大小趋向于HDFS的一个块的大小,默认是64MB,不过可以针对集群调整这个默认值,在新建所有文件或新建每个文件时具体指定即可。
9、为什么最佳分片的大小应该与块大小相同
因为它是确保可以存储在单个节点上的最大输入块的大小。如果分片跨越两个数据块,那么对于任何一个HDFS节点,基本上都不可能同时存储这两个数据块,因此分片中的部分数据需要通过网络传输到map任务节点。与使用本地数据运行整个map任务相比,这种方法显然效率更低。
10、数据本地优化
Hadoop在存储有输入数据(HDFS中的数据)的节点上运行map任务,可以获得最佳性能。这就是所谓的数据本地化优化(data locality optimization)。
11、剖析MapReduce程序—图解
MapReduce程序通过操作键/值对来处理数据,一般形式为
map: (k1, v1) -> list(k2, v2)
reduce:(k2, list(v2)) -> lsit(k3, v3)

12 我们为什么不能使用数据库来对大量磁盘上的大规模数据进行批量分析呢?我们为什么需要MapReduce?
这些问题的答案来自磁盘的另一个发展趋势:
寻址时间的提高远远慢于传输速率的提高。寻址是将磁头移动到特定磁盘位置进行读写操作的过程。它是导致磁盘操作延迟的主要原因,而传输速率取决于磁盘的带宽。
如果数据的访问模式中包含大量的磁盘寻址,那么读取大量数据集所花的时间势必会更长(相较于流式数据读取模式),流式读取主要取决于传输速率。另一方面,如果数据库系统只更新一小部分记录,那么传统的B树更有优势(关系型数据库中使用的一种数据结构,受限于寻址的比例)。但数据库更新大部分数据时,B树的效率比MapReduce低得多,因为需要使用“排序/合并”来重建数据库。
在许多情况下,可以将MapReduce视为关系型数据库管理系统的补充。两个系统之间的差异如下图所示。
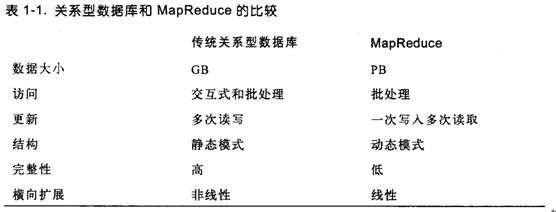
MapReduce比较适合以批处理的方式处理需要分析整个数据集的问题。RDBMS适用于“点查询”和更新,数据集被索引后,数据库系统能够提供低延迟的数据检索和快速的少量数据更新。MapReduce适合一次写入、多次读取数据的应用,而关系型数据库更适合持续更新的数据集。
12、Map任务输出结果存放在哪儿
Map任务将其输出写入本地硬盘,而非HDFS。
因为map的输出是中间结果:该中间结果由reduce任务处理后才产生最终输出结果,而且一旦作业完成,map的输出结果可以被删除。因此,如果把它存储在HDFS中并实现备份,难免有些小题大做。如果该节点上运行的map任务在将map中间结果传送给reduce任务之前失败,Hadoop将在另一个节点上重新运行这个map任务以再次构建map中间结果。
13、Reduce任务不具备数据本地化的优势
在仅有一个reduce任务的情况下,输入通常来自于所有mapper的输出。因此,排过序的map输出需通过网络传输发送到运行reduce任务的节点。数据在reduce端合并,然后由用户定义的reduce函数处理。
如果是多个reduce任务的情况,mapper的输出也要经过一系列的分区操作,将一部分mapper合并,然后分别输入到不同的reducer中。
14、reducer通过什么方式得到输出文件的分区
Reducer通过HTTP方式得到输出文件的分区。因为Map的输出结果是存放在本地的。
15、reduce的输出通常存放在哪儿
Reduce的输出通常存储在HDFS中以实现可靠存储。
16、reduce输出的HDFS块,复本存储在哪儿
对于每个reduce输出的HDFS块,第一个复本存储在本地节点上,其他复本存储在其他机架节点中。
因此,reduce的输出写入HDFS确实需要占用网络带宽,但这与正常的HDFS流水线写入的消耗一样。
HDFS流水线写入:
client把数据Block只传给一个DataNode,这个DataNode收到Block之后,传给下一个DataNode,依次类推,...,最后一个DataNode就不需要下传数据Block了。
17、Map的作用
Map的作用是过滤一些原始数据
18、Reduce的作用
Reduce则是处理这些数据,得到我们想要的结果
19、分布式文件系统
HDFS、NDFS、GFS
20、map任务的数量由谁决定
Map任务的数量由输入分片的的个数决定。
Hadoop将MapReduce的输入数据划分为等长的小数据块,称为输入分片(input split)或简称分片。
Hadoop为每个分片构建一个map任务,并由该任务来运行用户自定义的map函数从而处理分片中的每条数据。
21、reduce任务的数量由谁决定
Reduce任务的数量不由输入数据的大小决定,而是特别指定的。
22、reduce任务最优个数怎么计算
真实应用中,作业都把它设置成一个较大的数字,否则由于所有的中间数据都会放到一个reducer任务中,从而导致作业效率较低。
注意:在本地作业运行器上运行时,只支持0个或1个reducer。
Reduce最优个数与集群中可用的reducer任务槽数相关。总槽数由集群中节点数与每个节点的任务槽数相乘得到。该值由mapred.tasktracker.reduce.task.maximum属性的值决定。
23、map任务对其输出进行分区
如有多个reduce任务,则每个map任务都会对其输出进行分区(partition),即为每个reduce任务建一个分区。每个分区有许多键(及其对应值),但每个键对应的键/值对记录都在同一个分区中。分区由用户定义的分区函数控制,但通常用默认的分区器(partitioner,有时也称“分区函数“)通过哈希函数来分区,这种方法和高效。
24、一个reduce任务的完整数据流—图解
虚线框表示节点,虚线箭头表示节点内部的数据传输,而实线箭头表示节点之间的数据传输。

25、多个reduce任务的MapReduce数据流--图解

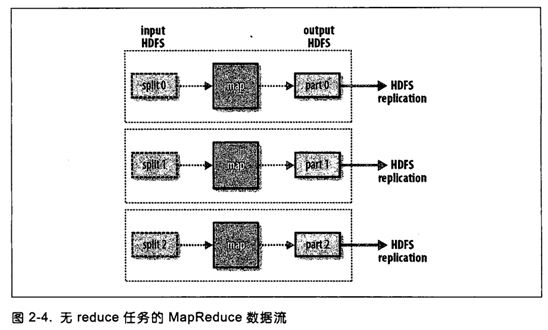
26、无reduce任务的数据流--图解
27、一个TaskTracker可同时运行多个map和reduce任务
每个TaskTracker可以生成多个JVM(JAVA虚拟机)来进行并行地处理许多map或reduce任务。
28、一个tasktracker能够同时运行最多多少个map和reduce任务
一个tasktracker能够同时运行最多多少个map任务:由mapred.tasktracker.map.tasks.maximum属性控制,默认值是2个任务。相应的,一个tasktracker能够同时运行的最多reduce任务数由mapred.tasktracker.reduce.task.maximum属性控制,默认也是2。详见《Hadoop权威指南》第二版P269页。
在一个tasktracker上能够同时运行的任务数取决于一台机器有多少个处理器。由于MapReduce作业通常是I/O-bound,因此将任务数设定为超出处理器数也有一定道理,能够获得更好的利用率。
至于到底需要运行多少个任务,则依赖于相关作业的CPU使用情况。
但经验法则是任务数(包括map和reduce任务)与处理器数的比值最好在1和2之间。
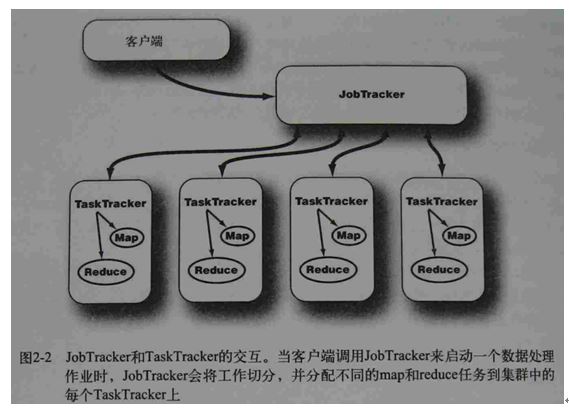
29、TaskTracker职责
1、其中一个职责是持续不断地与JobTracker通信。
30、计算的守护进程遵循主/从架构--图解
JobTracker作为主节点,监测MapReduce作业的整个执行过程,同时,TaskTracker管理各个任务在每个从节点上的执行情况。每个TaskTracker负责执行由JobTracker分配的单项任务。虽然每个从节点上仅有一个TaskTracker,但每个TaskTracker可以生成多个JVM(JAVA虚拟机)来进行并行地处理许多map或reduce任务。
TakTracker的一个职责是持续不断地与JobTracker通信。如果JobTracker在指定时间内没有收到来自TaskTracker的“心跳“,它会假定TaskTracker已经崩溃,进而重新提交相应的任务到集群中的其他任务节点。
31、节点间通信的唯一时间是在哪个阶段
节点间通信的唯一时间是在“洗牌“(shuffle)阶段。这个通信约束对可扩展性有很大的帮助。
集群上的可用带宽限制了MapReduce作业的数量,因此最重要的一点是尽量避免map任务和reduce任务之间的数据传输。Hadoop允许用户针对map任务的输出指定一个合并函数(combiner,就像mapper和reducer一样),合并函数的输出作为reduce函数的输入。由于合并函数是一个优化方案,所以Hadoop无法确定针对map任务输出中任一条记录需要调用多少次合并函数。换言之,不管调用多少次合并函数,reducer的输出结果都应一致。
32、为什么map任务和reduce任务之间的数据流称为shuffle(混洗)
因为每个reduce任务的输入都来自许多map任务。调整混洗参数对作业总执行时间会有非常大的影响。
33、什么是混洗和排序
34、文件分区的工作线程数量由什么属性控制
用于文件分区的工作线程的数量由任务的tasker.http.threads属性控制,此设置针对tasktracker,而不是针对每个map任务槽。默认是40,在运行大型作业的大型集群上,此值可以根据需要而增加。
35、创建检查点的步骤 P361

36、处理和存储的物理分布的Hadoop集群—图解

37、HDFS写数据—图解

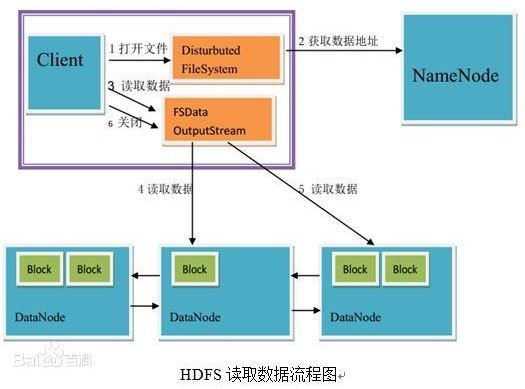
38、HDFS读数据—图解
hadoop与关系型数据库管理系统区别
1 、在合理的时间范围内处理针对整个数据集的即时查询
MapReduce似乎采用的是一种蛮力方法。每个查询需要处理整个数据集——或至少数据集的很大一部分。不过,这也正是它的能力。MapReduce是一个批量查询处理器,并且它能够在合理的时间范围内处理针对整个数据集的即时查询。
2、它们所操作的数据集的结构化程度不同
RDBMS
它操作的数据集是结构化数据。
结构化数据它是具有既定格式的实体化数据,诸如XML文档或满足特定预定义格式的数据表。
MapReduce
MapReduce对于结构化或半结构化数据非常有效,因为在处理数据时才对数据进行解释。换句话说:MapReduce输入的键和值并不是数据固有的属性,而是由分析数据的人员来选择。
半结构化数据
一些常见的半结构化数据比较松散,虽然可能有格式,但经常被忽略,所以它只能用作对数据的一般指导。例如,一张电子表格,其结构由其单元格组成的网格,但是每个单元格自身可保存任何形式的数据。
非结构数据
没有什么特别的内部结构,例如纯文本或图像数据。
讨论
1、节点、机架、数据中心的区别?
我认为,节点即指机器。守护进程例如NameNode、DataNode、JobTracker、TaskTracker、SecondaryNameNode等都驻留在节点中。即,存放守护进程的地方。
--Hadoop相关零散知识点