
首页 > 代码库 > Spark教程-构建Spark集群-配置Hadoop伪分布模式并运行Wordcount(2)
Spark教程-构建Spark集群-配置Hadoop伪分布模式并运行Wordcount(2)
执行文件拷贝操作

拷贝后的“input”文件夹的内容如下所示:

和我们的hadoop安装目录下的“conf”文件的内容是一样的。
现在,在我们刚刚构建的伪分布式模式下运行wordcount程序:
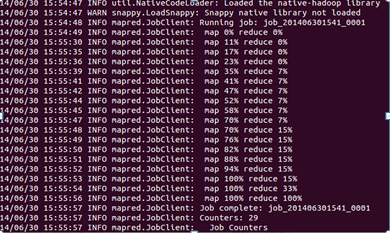
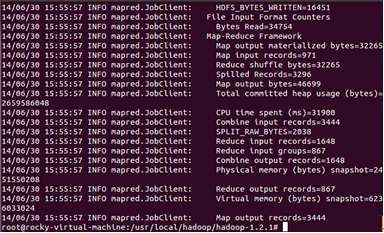
运行完成后我们查看一下输出的结果:

部分统计结果如下:

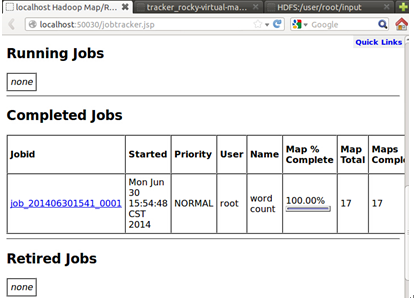
此时我们到达Hadoop的web控制台会发现我们提交并成功的运行了任务:
最后在Hadoop执行完任务后,可以关闭Hadoop后台服务:

至此,Hadoop伪分布式环境的搭建和测试你完全成功!
至此,我们彻底完成了实验。
Spark教程-构建Spark集群-配置Hadoop伪分布模式并运行Wordcount(2)
声明:以上内容来自用户投稿及互联网公开渠道收集整理发布,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任,若内容有误或涉及侵权可进行投诉: 投诉/举报 工作人员会在5个工作日内联系你,一经查实,本站将立刻删除涉嫌侵权内容。