
首页 > 代码库 > 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第四步)(2)
【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第四步)(2)
第二步:使用Spark的cache机制观察一下效率的提升
基于上面的内容,我们在执行一下以下语句:


发现同样计算结果是15.
此时我们在进入Web控制台:

发现控制台中清晰展示我们执行了两次“count”操作。
现在我们把“sparks”这个变量执行一下“cache”操作:

此时在执行count操作,查看Web控制台:

此时发现我们前后执行的三次count操作耗时分别是0.7s、0.3s、0.5s。
此时我们 第四次执行count操作,看一下Web控制台的效果:

控制台上清晰的第四次操作仅仅花费了17ms,比前三次的操作速度大约快了30倍的样子。这就是缓存带来的巨大速度提升,而基于缓存是Spark的计算的核心之一!
第三步:构建Spark的IDE开发环境
Step 1:目前世界上Spark首选的InteIIiJ IDE开发工具是IDEA,我们下载InteIIiJ IDEA:

这里下载是最新版本Version 13.1.4:

关于版本的选择,官方给出了如下选择依据:
我们在这里选择Linux系统下的”Community Edition FREE”这个版本,这能完全满足我们任意复杂程度的Scala开发需求。
家林下载完成后保存在本地的如下位置:

Step 2:安装IDEA并配置IDEA系统环境变量
创建“/usr/local/idea”目录:

把我们下载的idea压缩包解压到该目录下:
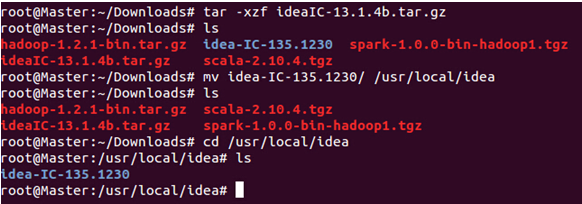
安装完成后,为了方便使用其bin目录下的命令,我们把它配置在“~/.bashrc”:
【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第四步)(2)
声明:以上内容来自用户投稿及互联网公开渠道收集整理发布,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任,若内容有误或涉及侵权可进行投诉: 投诉/举报 工作人员会在5个工作日内联系你,一经查实,本站将立刻删除涉嫌侵权内容。