
首页 > 代码库 > 使用DFA实现文字过滤
使用DFA实现文字过滤
Dfa和文字过滤
文字过滤是一般大型网站必不可少的一个功能,而且很多文字类网站更是需要。那么如何设计一个高效的文字过滤系统就是非常重要的了。
文字过滤需求简要描述:判断集合A中哪些子集属于集合B,拿javaeye来说,如果用户发表一篇文章(集合A),我们需要判断这篇文章里是否存在一些关键字是属于集合B,B一般来说就是违禁词列表。
看到这里,没有接触过的同学可能会想到contains,正则之类的方法,但是很遗憾,这些方法都是行不通的。唯一比较好的算法是DFA。
一,DFA简介:
学过编译原理的同学们一定知道,在词法分析阶段将源代码中的文本变成语法的集合就是通过确定有限自动机实现的。但是DFA并不只是词法分析里用到,DFA的用途非常的广泛,并不局限在计算机领域。
DFA的基本功能是可以通过event和当前的state得到下一个state,即event+state=nextstate,
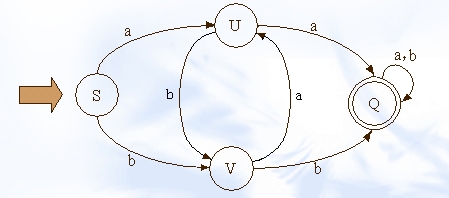
我们来看一张到处都能找到的状态图:
--------------------------------------- 
-------------------------------------
大写字母是状态,小写字母是动作:我们可以看到S+a=U,U+a=Q,S+b=V等等。一般情况下我们可以用矩阵来表示整个状态转移过程:
---------------
状态\字符 a b
S U V
U Q V
V U Q
Q Q Q
但是表示状态图可以有很多数据结构,上面的矩阵只是一个便于理解的简单例子。而接下来在本文提到的文字过滤系统中会使用另外的数据结构来实现自动机模型
二,文字过滤
在文字过滤系统中,为了能够应付较高的并发,有一个目标比较重要,就是尽量的减少计算,而在DFA中,基本没有什么计算,有的只是状态的转移。而要把违禁文字列表构造成一个状态机,用矩阵来实现是比较麻烦的,下面介绍一种比较简单的实现方式,就是树结构。
所有的违禁词其本质来说是有ascii码组成的,而待过滤文本其本质也是ascii码的集合,比如说:
输入是A=[101,102,105,97,98,112,110]
违禁词列表:
[102,105]
[98,112]
那么我们的任务就是把上面两个违禁词构造成一个DFA,这样输入的A就可以通过在这个DFA上的转移来实现违禁词查找的功能。
树结构实现这个DFA的基于的基本方法是数组的index和数组value之间的关系(在双数组trie中同样是基于这一基本方法)
那么102其实可以看作一个数组索引,而105是102这个索引指向的下一个数组中的一个索引,105后面没有值了,那就代表这个违禁词结束了。
通过这样一种方式,就可以构造出一颗DFA的树结构表示。
接着遍历输入文本中的每一个byte,然后在DFA中作状态转移就可以判断出一个违禁词是否出现在输入文本中。
下面贴出ahuaxuan基于以上理论用python写的一段文字过滤脚本:
#encoding:UTF-8
import sys
from time import time
‘‘‘
@author: ahuaxuan
@date: 2009-02-20
‘‘‘
wordTree = [None for x in range(256)]
wordTree.append(0)
nodeTree = [wordTree, 0]
def readInputText():
txt = ‘‘
for line in open(‘text.txt‘, ‘rb‘):
txt = txt + line
return txt
def createWordTree():
awords = []
for b in open(‘words.txt‘, ‘rb‘):
awords.append(b.strip())
for word in awords:
temp = wordTree
for a in range(0,len(word)):
index = ord(word[a])
if a < (len(word) - 1):
if temp[index] == None:
node = [[None for x in range(256)],0]
temp[index] = node
elif temp[index] == 1:
node = [[None for x in range(256)],1]
temp[index] = node
temp = temp[index][0]
else:
temp[index] = 1
def searchWord(str):
temp = nodeTree
words = []
word = []
a = 0
while a < len(str):
index = ord(str[a])
temp = temp[0][index]
if temp == None:
temp = nodeTree
a = a - len(word)
word = []
elif temp == 1 or temp[1] == 1:
word.append(index)
words.append(word)
a = a - len(word) + 1
word = []
temp = nodeTree
else:
word.append(index)
a = a + 1
return words
if __name__ == ‘__main__‘:
#reload(sys)
#sys.setdefaultencoding(‘GBK‘)
input2 = readInputText()
createWordTree();
beign=time()
list2 = searchWord(input2)
print "cost time : ",time()-beign
strLst = []
print ‘I have find some words as ‘, len(list2)
map = {}
for w in list2:
word = "".join([chr(x) for x in w])
if not map.__contains__(word):
map[word] = 1
else:
map[word] = map[word] + 1
for key, value in map.items():
print key, value
输入文本就是本文(不包含下面的示例结果文本)
运行结果示例:
python 5 违禁词 12 DFA 12 ahuaxuan 3
当然用python实现以上算法只是为了便于理解,事实上python的速度实在是太慢了,同样的违禁词列表,同样的输入文本,python写的比用java写的差了40倍左右。理论上来讲在这个功能上,用python调用c写的功能比较合适。
而这种方式比较大的缺点是内存使用虑较大,因为有很多数组上的元素是None,引用的空间会消耗大量的内存,这个和违禁词的长度和个数成正比。比较好的方式还是用双数组实现DFA,这个方式使用内存空间较小,而基本原理还是一样,通过两个数组的index和value之间的数学关系来实现状态机的转移。
附件中附带违禁词和输入文本的测试,大家可以运行一下看看效果。
由于ahuaxuan水平有限,如代码中出现问题,还望不吝指出,谢谢。
使用DFA实现文字过滤