
首页 > 代码库 > 搜索引擎-网络爬虫
搜索引擎-网络爬虫
文章转自:http://blog.csdn.net/hguisu/article/details/7949844
通用搜索引擎的处理对象是互联网网页,目前网页数量以百亿计,搜索引擎的网络爬虫能够高效地将海量的网页数据传下载到本地,在本地 形成互联网网页的镜像备份。它是搜索引擎系统中很关键也很基础的构件。
1. 网络爬虫本质就是浏览器http请求。
浏览器和网络爬虫是两种不同的网络客户端,都以相同的方式来获取网页:
1)首先, 客户端程序连接到域名系统(DNS)服务器上,DNS服务器将主机 名转换成ip 地址。
2)接下来,客户端试着连接具有该IP地址的服务器。服务器上可能有多个 不同进程程序在运行,每个进程程序都在监听网络以发现新的选接。.各个进程监听不同的网络端口 (port). 端口是一个l6位的数卞,用来辨识不同的服务。Http请求一般默认都是80端口。
3) 一旦建立连接,客户端向服务器发送一个http请求,服务器接收到请求后,返回响应结果给客户端。
4)客户端关闭该连接。
详细了解http工作原理:网络互联参考模型(详解) 和Apache运行机制剖析
2. 搜索引擎爬虫架构
但是浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成http请求,网络爬虫需要一套整体架构完成工作。
尽管爬虫技术经过几十年的发展,从整体框架上已相对成熟,但随着互联网 的不断发展,也面临着一些有挑战性的新问题。 通用爬虫框架如下图:

通用爬虫框架
通用的爬虫框架流程:
1)首先从互联网页面中精心选择一部分网页,以这 些网页的链接地址作为种子URL;
2)将这些种子URL放入待抓取URL队列中;
3)爬虫从待抓取 URL队列依次读取,并将URL通过DNS解析,把链接地址转换为网站服务器对应的IP地址。
4)然后将IP地址和网页相对路径名称交给网页下载器,
5)网页下载器负责页面内容的下载。
6)对于下载到 本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的 URL放入己抓取URL队列中,这个队列记载了爬虫系统己经下载过的网页URL,以避免网页 的重复抓取。
7)对于刚下载的网页,从中抽取出所包含的所有链接信息,并在已抓取URL队列 中检査,如果发现链接还没有被抓取过,则将这个URL放入待抓取URL队歹!
8,9)末尾,在之后的 抓取调度中会下载这个URL对应的网页,如此这般,形成循环,直到待抓取URL队列为空.
3. 爬虫抓取策略
在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。
3.1 深度优先搜索策略(顺藤摸瓜)
即图的深度优先遍历算法。网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
我们使用图的方式来说明:
我们假设互联网就是张有向图,图中每个顶点代表一个网页。 设初始状态是图中所有顶点未曾被访问,则深度优先搜索可从图中某个顶点发v 出发,访问此顶点,然后依次从v 的未被访问的邻接点出发深度优先遍历图,直至图中所有和v 有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
以如下图的无向图G1为例,进行图的深度优先搜索:

G1
搜索过程:
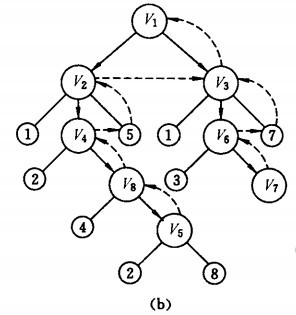
假设从顶点页面v1 出发进行搜索抓取,在访问了页面v1 之后,选择邻接点页面v2。因为v2 未曾访问,则从v2 出发进行搜索。依次类推,接着从v4 、v8 、v5 出发进行搜索。在访问了v5 之后,由于v5 的邻接点都已被访问,则搜索回到v8。由于同样的理由,搜索继续回到v4,v2 直至v1,此时由于v1 的另一个邻接点未被访问,则搜索又从v1 到v3,再继续进行下去由此,得到的顶点访问序列为:

3.2 广度优先搜索策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页, 一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。
还是以上面的图为例,抓取过程如下:
广度搜索过程:

首先访问页面v1 和v1 的邻接点v2 和v3,然后依次访问v2 的邻接点v4 和v5 及v3 的邻接点v6 和v7,最后访问v4 的邻接点v8。由于这些顶点的邻接点均已被访问,并且图中所有顶点都被访问,由些完成了图的遍历。得到的顶点访问序列为:
和深度优先搜索类似,在遍历的过程中也需要一个访问标志数组。并且,为了顺次访问路径长度为2、3、…的顶点,需附设队列以存储已被访问的路径长度为1、2、… 的顶点。
3.2 最佳优先搜索策略
最佳优先搜索策略按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取。
3.3.反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
在真实的网络环境中,由于广告链接、作弊链接的存在,反向链接数不能完全等他我那个也的重要程度。因此,搜索引擎往往考虑一些可靠的反向链接数。
3.4.Partial PageRank策略,即最佳优先搜索策略
Partial PageRank算法借鉴了PageRank算法的思想:按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取,即对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
它只访问经过网页分析算法预测为“有用”的网页。存在的一个问题是,在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种局部最优搜索算法。 因此需要将最佳优先结合具体的应用进行改进,以跳出局部最优点。研究表明,这样的闭环调整可以将无关网页数量降低30%~90%。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
3.5.OPIC策略策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
3. 6.大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
4. 网页更新策略
互联网是实时变化的,具有很强的动态性。网页更新策略主要是决定何时更新之前已经下载过的页面。常见的更新策略又以下三种:
尽管搜索引擎针对于某个查询条件能够返回数量巨大的结果,但是用户往往只关注前几页结果。因此,抓取系统可以优先更新那些现实在查询结果前几页中的网页,而后再更新那些后面的网页。这种更新策略也是需要用到历史信息的。用户体验策略保留网页的多个历史版本,并且根据过去每次内容变化对搜索质量的影响,得出一个平均值,用这个值作为决定何时重新抓取的依据。
3.聚类抽样策略

5. 云存储文档
应用的知识:
1,GFS,使用GFS分布式文件系统存储海量文档。
2,BitTable,在GFS的基础上构建BitTable的数据模型;
3,MegaStore存储模型又建立在BitTable之上的存储和计算模型。
4,Map/Reduce云计算模型和系统计算框架。
4.1 BitTable存储原始的网页信息
如图4-1所示的逻辑模型,示例crawldb table用于存储爬虫抓取的网页信息,
其中:Row Key为网页的URL,出于排序效率考虑,URL中主机域名字符顺序往往被反置,如www.facebook.com被处理为com.facebook.www;
Column Family包括title、content、anchor,其中tile保存网页的标题,content保存网页html内容,anchor保存网页被其它网页引用的链接,qualifier就是其它网页的URL,内容为其它网页中该链接的页面显示字符,同样anchor链接的URL主机域字符串被反置。对于不同时间获取的同一网页的有关内容被打上不同的时间戳Timestampe,如图纵向座标可以看到不同的版本。

图4-1Crawldb Table 逻辑模型
在实际的存储中,图4-1所示的多维逻辑结构会被二维平面化为(Key, Value)对,并且进行排序。在(Key,Value)中,Key由四维键值组成,包括:Row Key, ColumnFamily(处理时使用8比特编码), Column Qualifier和Timestamp,如图4-2所示,为Key的实际结构,在对Key进行排序过程中,有最新Timestamp的Key会被排在最前面,flag项用于标明系统需要对该(Key,Value)记录进行的操作符,如增加、删除、更新等。

图4-2 key结构图
如图4-3是crawldb二维平面化后经过排序的格式。图中Key列中的信息由Row Key(页面的URL)、Column Family、Column Qualifer和Timestamp组成,其中并未显示Key flag项,flag项主要用于表项处理。

图4-3 crawldb表的key/valuye 列表
图4-4显示了crawldb table的CellStore文件格式。CellStore文件中存储了经过排序后的Key,Value对,物理上,这些数据都被压缩后存储,以大约64k大小的块为单位组织;在文件结尾处,保留有三个索引部分:Bloom Filter、块索引(row key + 块在文件内的偏移)、Trailer。

网页去重我们采用简单策略,目标是将网页集合内所有内容相同的网页找出来,采 取对网页内容取哈希值的方法,比如MD5, 如果两个网页的MD5值相同,则可以认为两 页内容完全相同。 在Map/Reduce框架下,输入数据是网页本身,可以用网页的URL作为输入数据的Key, 网页内容是输入数据的value; Map操作则对每个网页的内容利用MD5计算哈希值,以这 个哈希值作为中间数据的Key, 网页的URL作为中间数据的value: Reduce操作则将相同 Key的中间数据对应的URL建立成一个链表结构,这个链表代表了具有相同网页内容哈希 值的都有哪些网页。这样就完成了识别内容相同网页的任务。
对于建立倒排索引这个任务来说,如图4-6所示,输入数据也是网页,以网页的DOCID作为输入数据 的Key, 网页中出现的单词集合是输入数据的 Value; Map 操作将输入数据转化为 (word,DOCID)的形式,即某个单词作为Key, DOCID作为中间数据的value,其含义是单词 word在DOCID这个网页出现过;Reduce操作将中间数据中相同Key的记录融合,得到某 个单词对应的网页ID列表: <word,List(DodD)>。这就是单词word对应的倒排列表。通过 这种方式就可以建立简单的倒排索引,在Reduce阶段也可以做些复杂操作,获得形式更为复杂的倒排索引。

图4-6
参考文献:
《这就是搜索引擎:核心技术详解》
《搜索引擎—信息检索实践》
搜索引擎-网络爬虫