
首页 > 代码库 > 一致性哈希与java实现
一致性哈希与java实现
一致性哈希算法是分布式系统中常用的算法。比如,一个分布式的存储系统,要将数据存储到具体的节点上,如果采用普通的hash方法,将数据映射到具体的节点上,如key%N,key是数据的key,N是机器节点数,如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了。
因此,引入了一致性哈希算法:
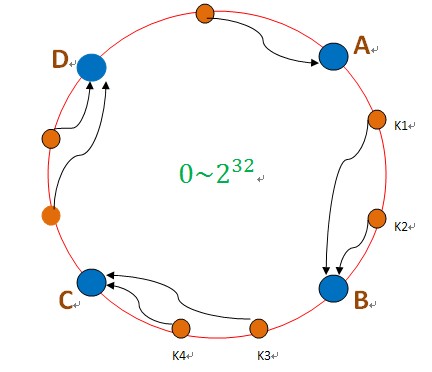
把数据用hash函数(如MD5),映射到一个很大的空间里,如图所示。数据的存储时,先得到一个hash值,对应到这个环中的每个位置,如k1对应到了图中所示的位置,然后沿顺时针找到一个机器节点B,将k1存储到B这个节点中。
如果B节点宕机了,则B上的数据就会落到C节点上,如下图所示:
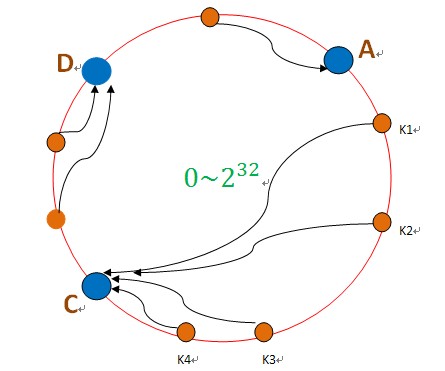
这样,只会影响C节点,对其他的节点A,D的数据不会造成影响。然而,这又会造成一个“雪崩”的情况,即C节点由于承担了B节点的数据,所以C节点的负载会变高,C节点很容易也宕机,这样依次下去,这样造成整个集群都挂了。
为此,引入了“虚拟节点”的概念:即把想象在这个环上有很多“虚拟节点”,数据的存储是沿着环的顺时针方向找一个虚拟节点,每个虚拟节点都会关联到一个真实节点,如下图所使用:
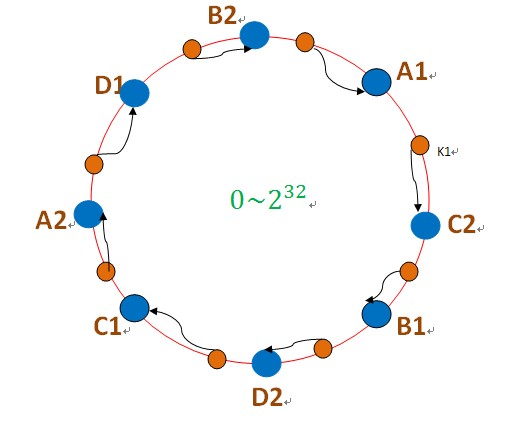
图中的A1、A2、B1、B2、C1、C2、D1、D2都是虚拟节点,机器A负载存储A1、A2的数据,机器B负载存储B1、B2的数据,机器C负载存储C1、C2的数据。由于这些虚拟节点数量很多,均匀分布,因此不会造成“雪崩”现象。
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简 单哈希算法带来的问题,使得分布式哈希(DHT)可以在P2P环境中真正得到应用。
一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
1、平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
2、单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3、分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4、负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
在分布式集群中,对机器的添加删除,或者机器故障后自动脱离集群这些操作是分布式集群管理最基本的功能。如果采用常用的hash(object)%N算法,那么在有机器添加或者删除后,很多原有的数据就无法找到了,这样严重的违反了单调性原则。接下来主要讲解一下一致性哈希算法是如何设计的:
环形Hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图

把数据通过一定的hash算法处理后映射到环上
现在我们将object1、object2、object3、object4四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。如下图:
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;

将机器通过hash算法映射到环上
在采用一致性哈希算法的分布式集群中将新的机器加入,其原理是通过使用与对象存储一样的Hash算法将机器也映射到环中(一般情况下对机器的hash计算是采用机器的IP或者机器唯一的别名作为输入值),然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。
假设现在有NODE1,NODE2,NODE3三台机器,通过Hash算法得到对应的KEY值,映射到环中,其示意图如下:
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;

通过上图可以看出对象与机器处于同一哈希空间中,这样按顺时针转动object1存储到了NODE1中,object3存储到了NODE2中,object2、object4存储到了NODE3中。在这样的部署环境中,hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
机器的删除与添加
普通hash求余算法最为不妥的地方就是在有机器的添加或者删除之后会照成大量的对象存储位置失效,这样就大大的不满足单调性了。下面来分析一下一致性哈希算法是如何处理的。
1. 节点(机器)的删除
以上面的分布为例,如果NODE2出现故障被删除了,那么按照顺时针迁移的方法,object3将会被迁移到NODE3中,这样仅仅是object3的映射位置发生了变化,其它的对象没有任何的改动。如下图:

2. 节点(机器)的添加
如果往集群中添加一个新的节点NODE4,通过对应的哈希算法得到KEY4,并映射到环中,如下图:

通过按顺时针迁移的规则,那么object2被迁移到了NODE4中,其它对象还保持这原有的存储位置。通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
平衡性
根据上面的图解分析,一致性哈希算法满足了单调性和负载均衡的特性以及一般hash算法的分散性,但这还并不能当做其被广泛应用的原由,因为还缺少了平衡性。下面将分析一致性哈希算法是如何满足平衡性的。hash算法是不保证平衡的,如上面只部署了NODE1和NODE3的情况(NODE2被删除的图),object1存储到了NODE1中,而object2、object3、object4都存储到了NODE3中,这样就照成了非常不平衡的状态。在一致性哈希算法中,为了尽可能的满足平衡性,其引入了虚拟节点。
——“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品( replica ),一实际个节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。
以上面只部署了NODE1和NODE3的情况(NODE2被删除的图)为例,之前的对象在机器上的分布很不均衡,现在我们以2个副本(复制个数)为例,这样整个hash环中就存在了4个虚拟节点,最后对象映射的关系图如下:

根据上图可知对象的映射关系:object1->NODE1-1,object2->NODE1-2,object3->NODE3-2,object4->NODE3-1。通过虚拟节点的引入,对象的分布就比较均衡了。那么在实际操作中,正真的对象查询是如何工作的呢?对象从hash到虚拟节点到实际节点的转换如下图:

“虚拟节点”的hash计算可以采用对应节点的IP地址加数字后缀的方式。例如假设NODE1的IP地址为192.168.1.100。引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“192.168.1.100”);
引入“虚拟节点”后,计算“虚拟节”点NODE1-1和NODE1-2的hash值:
Hash(“192.168.1.100#1”); // NODE1-1
Hash(“192.168.1.100#2”); // NODE1-2
Java实现:
- public class Shard<S> { // S类封装了机器节点的信息 ,如name、password、ip、port等
- private TreeMap<Long, S> nodes; // 虚拟节点
- private List<S> shards; // 真实机器节点
- private final int NODE_NUM = 100; // 每个机器节点关联的虚拟节点个数
- public Shard(List<S> shards) {
- super();
- this.shards = shards;
- init();
- }
- private void init() { // 初始化一致性hash环
- nodes = new TreeMap<Long, S>();
- for (int i = 0; i != shards.size(); ++i) { // 每个真实机器节点都需要关联虚拟节点
- final S shardInfo = shards.get(i);
- for (int n = 0; n < NODE_NUM; n++)
- // 一个真实机器节点关联NODE_NUM个虚拟节点
- nodes.put(hash("SHARD-" + i + "-NODE-" + n), shardInfo);
- }
- }
- public S getShardInfo(String key) {
- SortedMap<Long, S> tail = nodes.tailMap(hash(key)); // 沿环的顺时针找到一个虚拟节点
- if (tail.size() == 0) {
- return nodes.get(nodes.firstKey());
- }
- return tail.get(tail.firstKey()); // 返回该虚拟节点对应的真实机器节点的信息
- }
- /**
- * MurMurHash算法,是非加密HASH算法,性能很高,
- * 比传统的CRC32,MD5,SHA-1(这两个算法都是加密HASH算法,复杂度本身就很高,带来的性能上的损害也不可避免)
- * 等HASH算法要快很多,而且据说这个算法的碰撞率很低.
- * http://murmurhash.googlepages.com/
- */
- private Long hash(String key) {
- ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
- int seed = 0x1234ABCD;
- ByteOrder byteOrder = buf.order();
- buf.order(ByteOrder.LITTLE_ENDIAN);
- long m = 0xc6a4a7935bd1e995L;
- int r = 47;
- long h = seed ^ (buf.remaining() * m);
- long k;
- while (buf.remaining() >= 8) {
- k = buf.getLong();
- k *= m;
- k ^= k >>> r;
- k *= m;
- h ^= k;
- h *= m;
- }
- if (buf.remaining() > 0) {
- ByteBuffer finish = ByteBuffer.allocate(8).order(
- ByteOrder.LITTLE_ENDIAN);
- // for big-endian version, do this first:
- // finish.position(8-buf.remaining());
- finish.put(buf).rewind();
- h ^= finish.getLong();
- h *= m;
- }
- h ^= h >>> r;
- h *= m;
- h ^= h >>> r;
- buf.order(byteOrder);
- return h;
- }
- }
一致性哈希与java实现
声明:以上内容来自用户投稿及互联网公开渠道收集整理发布,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任,若内容有误或涉及侵权可进行投诉: 投诉/举报 工作人员会在5个工作日内联系你,一经查实,本站将立刻删除涉嫌侵权内容。