
首页 > 代码库 > 腾讯云数据库团队:MySQL5.7 JSON实现简单介绍
腾讯云数据库团队:MySQL5.7 JSON实现简单介绍
作者介绍:吴双桥 腾讯云project师
阅读原文。很多其它技术干货。请訪问
fromSource=gwzcw.57435.57435.57435">腾云阁。
本文主要介绍在MySQL 5.7.7開始引入的非结构化数据类型JSON的特性以及详细的实现方式(包含存储方式)。首先介绍为什么要引入JSON的原生数据类型的支持;接着介绍MySQL给用户提供的JSON操作函数,以及JSON路径表达式语法。结合两者,用户能够在数据库级别操作JSON的随意键值和数据;之后。重点介绍JSON在server側的存储结构,这也是深入理解很多其它JSON特性的根基;在最后介绍JSON作为新数据类型的比較与排序规则之前,介绍了对JSON类型数据建立索引的原理。
为什么JSON的原生支持
文档合法性
在MySQL5.7.7对JSON提供原生类型的支持之前,用户能够用TEXT或者BLOB类型来存储JSON文档。但对于MySQL来说,用户插入的数据仅仅是序列化后的一个普通的字符串,不会对JSON文档本身的语法合法性做检查,文档的合法性须要用户自己保证。在引入新的JSON类型之后。插入语法错误的JSON文档,MySQL会提示错误,并在插入之后做归一化处理,保证每一个键相应一个值。
更有效的訪问
MySQL 5.7.7+本身提供了很多原生的函数以及路径表达式来方便用户訪问JSON数据。比如对于以下的JSON文档:
{ "a": [ [ 3, 2 ], [ { "c" : "d" }, 1 ] ], "b": { "c" : 6 }, "one potato": 7, "b.c" : 8 }用户能够使用
$.a[1][0]获取{ "c" : "d" },
$.a[1]获取[ { "c" : "d" }, 1 ]
还能够使用通配符*和**来进行模糊匹配。详见下一段。性能优化
在MySQL提供JSON原生支持之前,假设用户须要获取或者改动某个JSON文档的键值。须要把TEXT或者BLOB整个字符串读出来反序列化成JSON对象,然后通过各种库函数訪问JSON数据。显然这样是很没有效率的,特别是对较大的文档。而原生JSON的性能,特别是读性能很好。依据Oracle公司针对200K+数据文档做的性能測试表明,同样的数据用TEXT和JSON类型的查询性能差异达到两个数量级以上。并且用户还能够对常常訪问的JSON键值做索引,进一步提升性能。JSON数据操作性能的提升是基于JSON数据本身的存储结构的。下文会进一步介绍。
JSON的操作接口及路径表达式
JSON的操作接口
依据MySQL官方文档的介绍,server端JSON函数的实现须要满足以下条件:Requirements:
- Lets users construct JSON data values from other relational data.
- Lets users extract relational data from JSON data values.
- Lets users minimally introspect the structure of JSON values and text (validity, length, depth, keys).
- Works on strings which are utf8mb4 encoded.
- Performance should be suitable for read-intensive applications.
Non-requirements:
- May produce surprising results on strings which are not utf8mb4 encoded.
- There is limited support for decimal values nested inside JSON documents.
- Performance may not be suitable for write-intensive applications.
提供的函数列表详细为:
JSON_APPEND() JSON_ARRAY_INSERT() JSON_UNQUOTE() JSON_ARRAY()
JSON_REPLACE() JSON_CONTAINS() JSON_DEPTH() JSON_EXTRACT()
JSON_INSERT() JSON_KEYS() JSON_LENGTH() JSON_VALID()
JSON_MERGE() JSON_OBJECT() JSON_QUOTE() JSON_REMOVE()
JSON_CONTAINS_PATH() JSON_SEARCH() JSON_SET() JSON_TYPE()以上函数的调用规则大多形如:
JSON_APPEND(json_doc, path, val[, path, val] ...)第一个參数`json_doc`为JSON文档,或者是表里面的某一列,也能够是JSON文档里面的嵌套子文档变量;
第二个參数`path`为路径表达式,用来定位要訪问的键,`path`(即路径表达式)以下紧接着会介绍。
第三个參数`val`有的函数可能没有。若有表示键相应的操作数值。
- JSON路径表达式
为了更方便高速的訪问JSON的键值,MySQL 5.7.7+提供了新的路径表达式语法支持。前文提到的$.a[1][0]就是路径表达式的一个详细的演示样例。完整的路径表达式语法为:
pathExpression> ::= scope [ ( pathLeg )* ]
scope ::= [ columnReference ] dollarSign
columnReference ::= [ [ databaseIdentifier period ] tableIdentifier period ] columnIdentifier
databaseIdentifier ::= sqlIdentifier
tableIdentifier ::= sqlIdentifier
columnIdentifier ::= sqlIdentifier
pathLeg ::= member | arrayLocation | doubleAsterisk
member ::= period ( keyName | asterisk )
arrayLocation ::= leftBracket ( non-negative-integer | asterisk ) rightBracket
keyName ::= ECMAScript-identifier | double-quoted-string-literal
doubleAsterisk ::= **还是以
{ "a": [ [ 3, 2 ], [ { "c" : "d" }, 1 ] ], "b": { "c" : 6 }, "one potato": 7, "b.c" : 8 }为例。再举几个样例说明:
$.a[1] 获取的值为 [ { "c" : "d" }, 1 ]
$.b.c 获取的值为 6
$."b.c" 获取的值为 8
对照上面最后两个样例。能够看到用引號包围的表达式会被当作一个字符串键值。
关于通配符*和**来进行模糊匹配须要做进一步的说明。
两个连着星号**不能作为表达式的结尾,不能出现连续的三个星号***
单个星号*表示匹配某个JSON对象中全部的成员
[*]表示匹配某个JSON数组中的全部元素
prefix**suffix表示全部以prefix開始,以suffix结尾的路径
举个详细的样例,直接在MySQL命令行里面输入:
“`select json_extract(‘{ “a”: [ [ 3, 2 ], [ { “c” : “d” }, 1 ] ], “b”: { “c” : 6 }, “one potato”: 7, “b.c” : 8 }’,’$**.c’);
得到显示结果:`["d", 6]`。
#### JSON的存储结构及详细实现
在处理JSON时,MySQL使用的utf8mb4字符集,utf8mb4是utf8和ascii的超集。由于历史原因,这里utf8并不是是我们常说的UTF-8 Unicode变长编码方案。而是MySQL自身定义的utf8编码方案,最长为三个字节。
详细差别非本文重点。请大家自行Google了解。
MySQL在内存中是以DOM的形式表示JSON文档。并且在MySQL解析某个详细的路径表达式时,仅仅须要反序列化和解析路径上的对象,并且速度极快。要弄清晰MySQL是怎样做到这些的,我们就须要了解JSON在硬盘上的存储结构。
有个有趣的点是,JSON对象是BLOB的子类。在其基础上做了特化。
依据MySQL官方文档的表述:
> On a high level, we will store the contents of the JSON document in three sections:
> - A table of pointers to all the keys and values, in the order in which the keys and values are stored. Each pointer contains information about where the data associated with the key or the value is located, as well as type information about the key or value pointed to.
> *All the keys. The keys are sorted, so that lookup can use binary search to locate the key quickly.
> - All the values, in the same order as their corresponding keys.
>If the document is an array, it has two sections only: the dictionary and the values.
> If the document is a scalar, it has a single section which contains the scalar value
我们来使用示意图更清晰的展示它的结构:
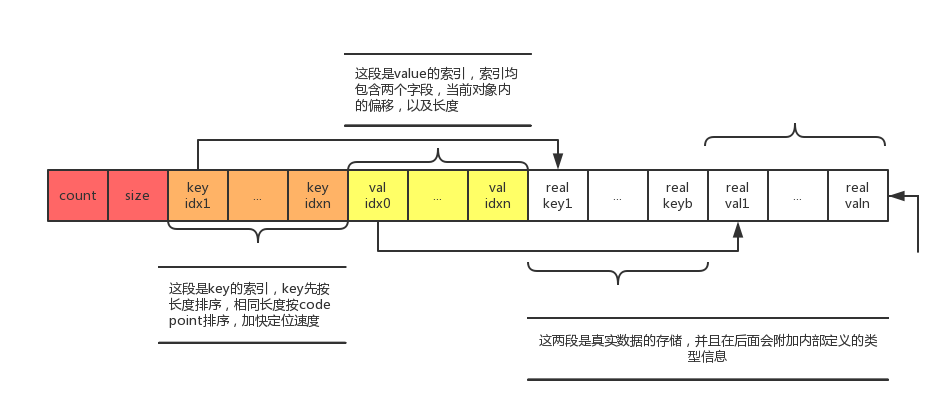
JSON文档本身是层次化的结构,因而MySQL对JSON存储也是层次化的。对于每一级对象,存储的最前面为存放当前对象的元素个数,以及总体占的大小。须要注意的是:
- JSON对象的Key索引(图中橙色部分)都是排序好的,先按长度排序,长度同样的依照code point排序;Value索引(图中黄色部分)依据相应的Key的位置依次排列,最后面真实的数据存储(图中白色部分)也是如此
- Key和Value的索引对存储了对象内的偏移和大小。单个索引的大小固定,能够通过简单的算术跳转到距离为N的索引
- 通过MySQL5.7.16源码能够看到。在序列化JSON文档时,MySQL会动态检測单个对象的大小。假设小于64KB使用两个字节的偏移量。否则使用四个字节的偏移量。以节省空间。同一时候。动态检查单个对象是否是大对象。会造成对大对象进行两次解析,源码中也指出这是以后须要优化的点
- 如今受索引中偏移量和存储大小四个字节大小的限制。单个JSON文档的大小不能超过4G。单个KEY的大小不能超过两个字节,即64K
- 索引存储对象内的偏移是为了方便移动,假设某个键值被改动,仅仅用改动受影响对象总体的偏移量
- 索引的大小如今是冗余信息。由于通过相邻偏移能够简单的得到存储大小,主要是为了应对变长JSON对象值更新。假设长度变小,JSON文档总体都不用移动。仅仅须要当前对象改动大小
- 如今MySQL对于变长大小的值没有预留额外的空间。也就是说假设该值的长度变大,后面的存储都要受到影响
- 结合JSON的路径表达式能够知道。JSON的搜索操作仅仅用反序列化路径上涉及到的元素,速度很快。实现了读操作的高性能
- 只是。MySQL对于大型文档的变长键值的更新操作可能会变慢,可能并不适合写密集的需求
#### JSON的索引
如今MySQL不支持对JSON列进行索引。官网文档的说明是:
>JSON columns cannot be indexed. You can work around this restriction by creating an index on a generated column that extracts a scalar value from the JSON column.
尽管不支持直接在JSON列上建索引,但MySQL规定。能够首先使用路径表达式对JSON文档中的标量值建立虚拟列,然后在虚拟列上建立索引。这样用户能够使用表达式对自己感兴趣的键值建立索引。举个详细的样例来说明:
CREATE TABLE features (
id INT NOT NULL AUTO_INCREMENT,
feature JSON NOT NULL,
PRIMARY KEY (id)
);
插入它的JSON数据的格式为:{
“type”:”Feature”,
“properties”:{
“TO_ST”:”0”,
“BLKLOT”:”0001001”,
“STREET”:”UNKNOWN”,
“FROM_ST”:”0”,
“LOT_NUM”:”001”,
“ST_TYPE”:null,
“ODD_EVEN”:”E”,
“BLOCK_NUM”:”0001”,
“MAPBLKLOT”:”0001001”
}
}
使用:ALTER TABLE features ADD feature_street VARCHAR(30) AS (JSON_UNQUOTE(feature->”$.properties.STREET”));
ALTER TABLE features ADD INDEX (feature_street);
两个步骤。能够对feature列中properties键值下的STREET键(`feature->"$.properties.STREET"`)创建索引。
当中,`feature_street`列就是新加入的虚拟列。
之所以取名虚拟列。是由于与它相应的另一个存储列(stored column)。它们最大的差别为虚拟列仅仅改动数据库的metadata,并不会存储真实的数据在硬盘上,读取过程也是实时计算的方式。而存储列会把表达式的列存储在硬盘上。
两者使用的场景不一样。默认情况下通过表达式生成的列为虚拟列。
这样虚拟列的加入和删除都会很快。而在虚拟列上建立索引跟传统的建立索引的方式并没有差别。会提高虚拟列读取的性能,减慢总体插入的性能。
虚拟列的特性结合JSON的路径表达式。能够方便的为用户提供高效的键值索引功能。
#### JSON比較与排序
JSON值能够使用=, <, <=, >, >=, <>, !=, <=>等操作符。`BETWEEN`, `IN`,`GREATEST`, `LEAST`等操作符如今还不支持。JSON值使用的两级排序规则。第一级基于JSON的类型。类型不同的使用每一个类型特有的排序规则。
JSON类型依照优先级从高到低为
BLOB
BIT
OPAQUE
DATETIME
TIME
DATE
BOOLEAN
ARRAY
OBJECT
STRING
INTEGER, DOUBLE
NULL
“`
优先级高的类型大,不用再进行其它的比較操作;假设类型同样。每一个类型按自己的规则排序。
详细的规则例如以下:
- BLOB/BIT/OPAQUE: 比較两个值前N个字节,假设前N个字节同样。短的值小
- DATETIME/TIME/DATE: 依照所表示的时间点排序
- BOOLEAN: false小于true
- ARRAY: 两个数组假设长度和在每一个位置的值同样时相等。假设不想等,取第一个不同样元素的排序结果,空元素最小
- OBJECT: 假设两个对象有同样的KEY,并且KEY相应的VALUE也都同样。两者相等。否则。两者大小不等。但相对大小未规定。
- STRING: 取两个STRING较短的那个长度为N。比較两个值utf8mb4编码的前N个字节,较短的小,空值最小
- INTEGER/DOUBLE: 包含精确值和近似值的比較,略微有点复杂,可能出现与直觉相悖的结果。详细參见官方文档相关说明。
不论什么JSON值与SQL的NULL常量比較,得到的结果是UNKNOWN。
对于JSON值和非JSON值的比較。依照一定的规则将非JSON值转化为JSON值,然后依照以上的规则进行比較。
小结
本文主要介绍了MySQL在5.7.7之后引入的原生JSON支持的特性,说明了引入JSON类型的优点,并结合详细的演示样例介绍了MySQL在JSON类型上对外的接口以及引入的新语法规则。此外,还重点介绍了JSON在硬盘上的存储结构,简要分析了这样的存储结构的优势和不足。最后还介绍了JSON的索引原理,以及比較和排序规则。
相信理解了本文介绍的内容,关于JSON文中没有提到的部分内容也较easy理解。
相关推荐
MySQL内核深度优化
MySQL数据库的高可用性分析
阅读原文。很多其它技术干货,请訪问腾云阁。
腾讯云数据库团队:MySQL5.7 JSON实现简单介绍