
首页 > 代码库 > 深入理解HBase
深入理解HBase
思考:HBase服务器内部由那些主要部件构成?
HBase的内部工作原理是什么?
1. HBase的工作原理:
首先HBase Client端会连接Zookeeper Qurom(从下面的代码也能看出来,例 如:HBASE_CONFIG.set(“hbase.zookeeper.quorum”,”192.168.50.216″) )。通过Zookeeper组件Client能获知哪个Server管理-ROOT-Region。那么Client就去访问管理-ROOT-的 Server,在META中记录了HBase中所有表信息,(你可以使用 scan ‘.META.’ 命令列出你创建的所有表的详细信息),从而获取Region分布的信息。一旦Client获取了这一行的位置信息,比如这一行属于哪个 Region,Client将会缓存这个信息并直接访问HRegionServer。久而久之Client缓存的信息渐渐增多,即使不访问.META.表 也能知道去访问哪个HRegionServer。HBase中包含两种基本类型的文件,一种用于存储WAL的log,另一种用于存储具体的数据,这些数据 都通过DFS Client和分布式的文件系统HDFS进行交互实现存储。
2. Client访问数据过程:
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过client端会做cache缓存。
-ROOT-表、.META都是存放在哪里??
client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问region server),master仅仅维护者table和region的元数据信息,负载很低。
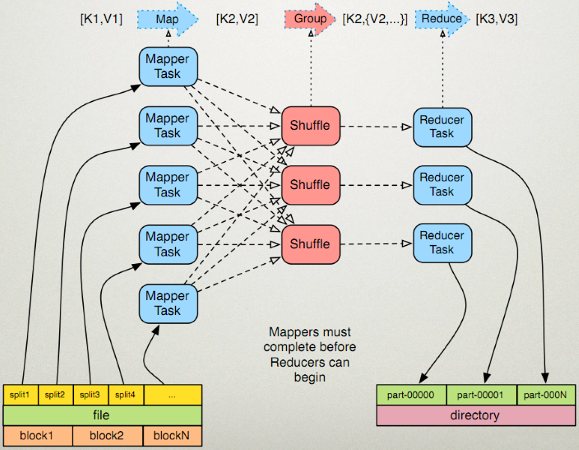
3. 在HBase上进行MapReduce操作:
4. HBase系统架构:
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
5. Zookeeper:
Zookeeper简单说就是协调和服务于分布式应用程序的服务。
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到 Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的 单点问题。
1 保证任何时候,集群中只有一个master
2存贮所有Region的寻址入口。
3 实时监控RegionServer的状态,将Region server的上线和下线信息实时通知给Master
4 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Zookeeper到底为我们干了什么?
1. 集中配置:可以APP1的配置配置到/APP1 znode下的所有机器。
2. 集群管理:同步:维护活机列表(让集群所有机器得到实时更新),
组服务:从集群中选择Master。
6. HMaster:
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的MasterElection机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作:
1. 管理用户对Table的增、删、改、查操作
2. 管理HRegionServer的负载均衡,调整Region分布
3. 在Region Split后,负责新Region的分配
4. 在HRegionServer停机后,负责失效HRegionServer 上的Regions迁移
7. HRegionServer:
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,HRegion中 由多个HStore组成。每个HStore对应了Table中的一个ColumnFamily的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个ColumnFamily中,这样最高效。
8. Hadoop+HBase+Zookeeper三者关系:
1.经过Map、Reduce运算后产生的结果看上去是被写入到HBase了,但是其实HBase中HLog和StoreFile中的文件在进行flush to disk操作时,这两个文件存储到了HDFS的DataNode中,HDFS才是永久存储。
2.ZooKeeper跟HadoopCore、HBase有什么关系呢?ZooKeeper都提供了哪些服务呢?主要有:管理Hadoop集群中 的NameNode,HBase中HBaseMaster的选举,Servers之间状态同步等。具体一点,细一点说,单只HBase中 ZooKeeper实例负责的工作就有:存储HBase的Schema,实时监控HRegionServer,存储所有Region的寻址入口,当然还有 最常见的功能就是保证HBase集群中只有一个Master。
小结
Hadoop、ZooKeeper和HBase之间应该按照顺序启动和关闭:启动Hadoop—>启动ZooKeeper集群—>启动HBase—>停止HBase—>停止ZooKeeper集群—>停止Hadoop。
深入理解HBase