
首页 > 代码库 > 验证码识别 ——知乎网友2
验证码识别 ——知乎网友2
推荐Programming Computer Vision with Python, 这位作者用python重写很多基本的Computer Vision算法,书的final draft在首页,代码也在Github上边。类似于验证码识别的问题呢,大家可以直接refer Chapter 8 - Classifying Image Content, 里边不仅有对3种classification approaches的详细解释,而且还有比如手势识别,OCR识别等经典问题,更更重要的是,Github上直接有那些data set,意味着你可以自己做着玩,非常好的书,编码方面对我帮助很好。
哪些验证码不好识别?
个人以为大概2个方面
- 图像的预处理
我们看下面大概知道通常第一步就是需要分割图像成几个小的图像,然后每个笑的图像尽可能的各自独立,这一步应该是比较麻烦的一步啦。
比如上图所示铁道部静态的验证码,这就是非常容易分割的啦。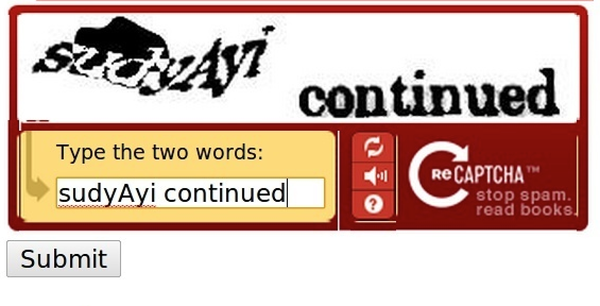
再比如google的这个验证码,我们发现左边的个单词可能就算是人类也需要花些时间来识别,可是右边的这个continued我们一眼就可以看出来。据说,右边的这个词是google扫描书籍后的图像,然后因为很多图像计算机也不好识别,所以就通过这个方式来使用人力进行识别,通常只要右边的词写对啦,就算是正确的好像,而左边的经过扫描之后的词呢就会根据大部分人写出的答案来对其识别,so smart.
- 训练样本
大家看到每个网站可能用的验证码都不太一样哈,所以为了提高准确率,训练样本(training samples)对了classifier的功效起着致命的作用。比如12306的验证码,我们可能就需要花一定的时间去label samples;然后对于腾讯一系列的验证码,可能又需要花些时间去label samples。而且通常来讲,样本越大,准确率会提高。这样带来的结果就是成本高!!
最后,那有没有办法用12306的训练样本来识别腾讯的验证码呢?毕竟他们都是验证码嘛。这样一来就可以节省时间啊,那就是成本的减少啊。学术界很早就想到了这样子的一个方向,叫做 Transfer Learning (or Domain Adaptations)。蛮有趣哒!
--------------------------------------------------------------------------------------------------------------------
2014-1-8
基本是Machine Learning中经典问题啦 - recognition,然后recognition又被应用在很多很多的方面,比如最基本的text classification, image classification,甚至是video classification。对于验证码的处理,基本是以下几步啦,其他问题的framework也基本如此,不一样的大概就是不同的方法去建立model,然后SVM也有很多变形。
- 验证码图像的预处理
- 建立模型
- 识别
接下来一个个的解释吧,亲!
验证码图像的预处理
比如我们拿到以上“2907”这样子的图像,对吧,第一步需要做的就是分割使得每一个字符都很好的独立于各自的图像当中,所以,这样子之后呢,我们都会得到4张小的图像,这些图像分别表示为2,9,0,7,当然我们人眼很容易就知道这是什么,可是计算机不知道呀!
分割之后,在要做的就是图像方面的处理啦,大概是让数字变的更加明显一点,比如灰度方面的处理。
建立模型
这个应该是最为critical的部分,我尽量说清楚些。其实在recognize这个验证码之前,我们会收集很多类似的图像,并且人工进行标注。比如说哈,

这样子的数据被称之为 training data,接下来就是建立各种各样的模型吧。可能会用PCA,LDA...之类的方法对这些training data进行简化描述。接下来会有蛮多recognition approach,根据不一样的approach建立不同的模型。这里讲常用的两种。
1. K-Nearest-Neighbour 被称之为lazy learner,是因为其实不需要建立模型,用PCA,LDA..之类的方法对training data进行描述就好啦。待会讲详细的过程。
2.Support Vector Machine 应该是现在识别系统当最流行的方法啦,这个的的确确建立了个模型。如下图所示,我们会把training data投影到坐标系当中,然后找到一个hyperplane which best separates different samples。 之所以是hyperplane,数据的维度可能很高。SVM有很多变形,这里就不赘述啦。找到这个hyperplane之后,我们就可以进行识别啦。
识别
- K-Nearest-Neighbour (KNN)
我们把需要识别的图像称之为test case, test case经过上边同样的处理之后呢,我们就从training data当中选出离这个test case最近的K的training samples。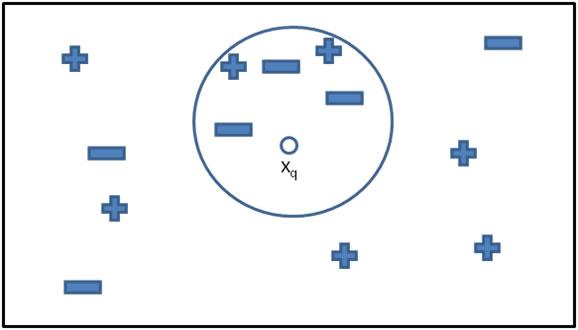
比如上边的这个例子,K = 5, 然后对于 x_q 而言呢,最近的5个samples,其中3个是negative,2个是positive,当然我们就会认为x_q是negative的啦,基本就是按照majority vote来个x_q分类。具体到验证码的话,假如一个图像最近的5个training samples当中有4个是“5”,一个是“6”,那么计算机就直接认为这个图像指向的是“5”。
- Support Vector Machine (SVM)
前边讲到说我们会找到一个hyperplane, 那么接下来需要做的就是计算test case到这一个hyperplane的距离,如果是 距离>0 (距离可以小于 0 哒,这个就看怎么定义方向啦) ,那么这个test case就会被label成positive,否则的话,那句只能是negative啦。具体到验证码,那就是个 multi-class SVM啦,因为会有 10 digits + 26 letters, 总共有36个class,那计算机机会建立好多个不一样的SVM,然后通过一些方法来对test case进行分类。
第一次认真回答这么technical的东西,希望有帮助!想知道更多的话,建议去coursera上听听课。喔,对啦,之前讲过这个framework可以被引申到很多应用哒,其中一个就是沸沸扬扬的面部识别呀,这个有一个当时上课做的project,有兴趣的同学看看呗。wihoho/FaceRecognition · GitHub
验证码识别 ——知乎网友2