
首页 > 代码库 > Base64编码原理与应用
Base64编码原理与应用
本文内容转自网络,如需详细内容,请参考相关网址。
http://my.oschina.net/goal/blog/201032
代码参考:http://blog.csdn.net/prsniper/article/details/7097643
Base64,它用作把任意序列的8位字节描述为一种不易被人直接识别的形式,常用作开发中用于传递参数、浏览器的img标签通过base64字符串来渲染图片以及电子邮件的正文编码等等。
在计算机中显示的字符,比如英文字母、数字以及英文标点符号就是用一个字节来存储,通常称为ASCII码。而简体中文、繁体中文、日文以及韩文等都是用多字节来存储的,通常称之为多字节字符。因为Base编码的输入是字符串的编码,不同编码的字符串的Base64结果是不同的。所以,先来介绍基本的字符编码知识。
字符编码基本知识
最开始的计算机,只支持ASCII码,不支持中文等其他字符,一个字符采用一个字节(8位)表示,只使用低7位,最高位固定为0,因此总共有128个ASCII码(取值范围:0~127)。
为了支持更多地区的语言,各大组织机构和IT厂商开始推广自己的编码方案,以弥补ASCII编码的不足,如GB2312编码、GBK编码和Big5编码,这些编码只是针对局部地区的文字,往下兼容ASCII码,没办法表达所有的语言,这些不同的编码之间没有任何联系,他们之间的转换需要通过查表来实现。
为了提高计算机的信息处理和交换能力,使得各国文字都能在计算机中处理。国际ISO组织制定了通用多字节编码字符集(ISO 10646),简称UCS,这一标准为世界各种主要语言的字符以及附加符号,编制统一的内码。Unicode是Unicode学术学会机构制定的编码系统,从内容上来看,和UCS是同步一致的。
ANSI不代表具体的编码,而是代指本地编码,比如在简体中文版的Windows上面,它代表GB2312编码,在繁体中文版上面,它代表Big5编码,在日文操作系统上面,代表JIS编码。所以,当用户新建并且保存文件类型为ANSI编码,那么那会根据本地系统的编码来确定具体的编码。
Unicode编码
Unicode编码表和字符表是一一映射的,比如汉字”回“,其Unicode编码为56DE,通过56DE就能在Unicode表中找到汉字”回“。Unicode本身定义了每个字符的数值,是字符和自然数的映射关系,而UTF-8、UTF-16则定义了如何在字节流中断字。现在最为常用的Unicode编码为UTF-8和UTF-16.下图为常用的UTF-8的编码形式。在线汉字编码查询点此进入。

从图中可以看出,UTF-8为变长的编码方式(1~6个字节),向下兼容ASCII编码,通常将UTF-8看做单字节或三字节的实现,其他情况非常罕见。每个字节的开始很有规律,方便处理。
UTF-16
UTF-16编码是最直接的Unicode的实现方式,它采用固定两个字节来存储,因为是多字节,所以有小端存储和大端存储两种方式。UTF-16编码是Windows上默认的Unocode编码方式,两个字节小端存储。
在Windows的文本文档中,当另存为时,在编码类型中,有如下几个选择。
 就同样一个汉字”回“字,其不同的编码内容如下:
就同样一个汉字”回“字,其不同的编码内容如下:

unicode编码结果上面,前面的两个字节FF FE是文件头,代表这是一个UTF16编码的文件,DE 56是”回“字的UTF16编码十六进制表示,低位字节为DE,高位字节为56,组合在一起,就是0x56DE。
有了上述的知识积累,就可以很方便的在UTF8和UTF16之间相互转换了,还是以”回“字为例子,UTF16编码值为 0x56DE,它在0x0000_0800~0x0000_FFFF之间,对于的UTF8字节为三字节。所以,这个转换就是将2字节的UTF16转换为3字节的UTF8编码。注意到UTF-8表中的转换图中的x部分,就是对应0x56DE的各个位的数值。转化结果如下:
UTF8转换为UTF16就是上面的逆过程,知道了转换规则,很容易实现其代码。
中国大陆使用的中文标准为GB2312,一共收录了7445个常用简体汉字和中文符号。
Big5是台湾使用的编码标准,大约编码了8千多个繁体汉字。
HKSCS是香港地区使用的编码标准,但和Big5有所不同。
上述这几套中文编码互不兼容,妨碍软件开发,国际上针对此情况,制定了针对中文的统一字符集GBK和GB18030,其中,GBK已经在Windows、Linux等多种操作系统上实现。GBK1.0收录了21886个符号,分为汉字区和图形符号区,2000年的GB18030是取代GBK1.0,成为正式国家标准,该标准收录了27484个汉字,还收录了藏文、蒙文、维吾尔文等主要少数民族汉字。一般设备上,只需要支持GB2312就足够了。
从ASCII、GB2312、GBK到GB18030,这些编码是向下兼容的,其中,区分中文编码的方法是高字节的最高位不为0.
Unicode只与ASCII兼容,与GB系列码不兼容。例如,“汉”字的Unicode码为6C49,GB码为BABA。
上面讲述了最基本的ASCII、UTF-8、UTF-16等编码的基础知识和对于的转化规则,下面开始介绍本文重点内容Base64编码。
Base64编码
Base64用在必须用可打印字符表示二进制内容的场合,将任意字节转为可读字符的编码,这种编码,不是为安全,因为它是可逆的,而是为了显示。比如需要在xml文档中包含一段音频或者数字签名,URL传递参数,电子邮件的传输编码,可打印字符包括大小写字母(A-Z,a-z),数字(0-9),加号(“+”),正斜杠(“/”),外加补全符号(“=”)
Base64编码要求把3个8位字节(3*8=24位)编码成4个6位的字节(4*6=24位),之后在每个6位字节前面,补充两个0,形成4个8位字节的形式(取值范围在0~63),由于2^6次方等于64,所以每6个位组成一个单元,对于某个可打印的字符,当原始数据不是3的整数倍时,
当最后剩下一个输入字节时,在编码后面添加两个”=”
当最后剩下两个输入字节时,在编码后面添加一个“=”
当数据可以被3整除,就不需要添加数据。
下图为Base64转码表:
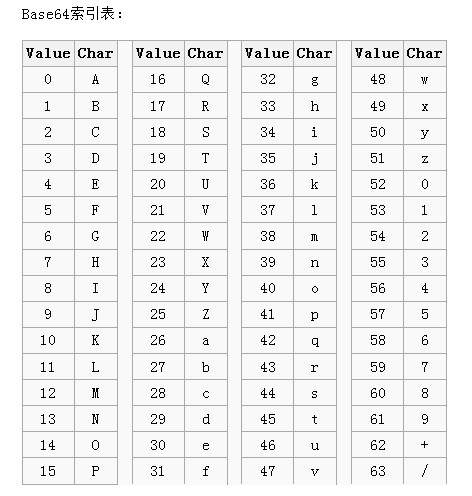
上述为标准的Base64编码,标准的Base64编码不适合直接放在URL里面传输,因为URL编码器会将”/“和”+”字符转变为形如”%XX”的形式,而这些”%”号在存入数据库时,还需要转换,因为ANSI SQL中”%“是通配符。
人们为了解决此问题,提出了用于URL的改进Base64编码,它不在末尾填充”=”,并且将标准Base64中的”+”和”/”分别改成了”-”和“_”,这样就免去URL的编解码和数据存储时的格式转换,长度保持不变,统一了数据库、表单等处理对象的格式。
编码过程,简单下来可以总结为:
1. 先将输入的字节数凑成3的整数倍N,然后申请N*4/3+1这么多的空间内存空间
2. 按照3个字节为一组,转换为4个字节的输出原则转换,特别要注意申请空间的最后一位的处理
3. 解密时,有取值判断和查表两种方法,推荐使用查表法。
4. 在字符串输出的最后,需要加上结束标志符’\0’
下面给出C语言的Base64代码,在网友给出的代码基础上,经过自己认真测试,现在贡献出来,希望能够帮助到其他人。我在这里面,对结束符的处理是映射为0xFF,个人觉的,只要知道这个标志出现了,做适当的处理就可以了。
/************************************************************************************************** Filename: base64.c Revised: 2014-12-09 15.18 Description: this file use to descript the Base64 encode and decode Author: huhao Email: huhao0126@163.com***************************************************************************************************/#include "stdlib.h"#include "base64.h"static const char BASE_CODE[] = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";static const unsigned char base64_dec_map[128] ={ 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, //0 ~ 9 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, //10~19 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, //20~29 127, 127, 127, 127, 127, 127, 127, 127, 127, 127, //30~39 127, 127, 127, 62, 127, 127, 127, 63, 52, 53, //40~49 54, 55, 56, 57, 58, 59, 60, 61, 127, 127, //50~59 127, 0xFF, 0, 0, 0, 0, 1, 2, 3, 4, //60~69 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, //70~79 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, //80~89 25, 127, 127, 127, 127, 127, 127, 26, 27, 28, //90~99 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, //100~109 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, //110~119 49, 50, 51, 127, 127, 127, 127, 127 //120~127};/************************************************************************************************** * @fn base64_encode * * @brief This function encode the bindata into base64 format. * * input parameters * * @param bindata - the input bindata * @param output - the output base64 data. * @param slen - the length of input data. * * output parameters * * None. * * @return the length of encoder output ************************************************************************************************** */int Base64Encode(const unsigned char* bindata, unsigned char* output,int slen){ int vlen = 0; unsigned char* temp_data; temp_data = bindata; while(slen > 0 ) { *output++ = BASE_CODE[ (temp_data[0]>>2) & 0x3F ]; if(slen > 2 ) //长度大于三个字符 处理生成4个字符 { *output++ = BASE_CODE[ ( ( temp_data[0] & 0x03 )<<4) | ( temp_data[1] >>4) ]; *output++ = BASE_CODE[ ( ( temp_data[1] & 0x0F )<<2) | ( temp_data[2] >>6) ]; *output++ = BASE_CODE[ ( temp_data[2] & 0x3F )]; }else if( slen == 2) //恰好为两个字符 { *output++ = BASE_CODE[ ( ( temp_data[0] & 0x03 )<<4) | ( temp_data[1] >>4) ]; *output++ = BASE_CODE[ ( ( temp_data[1] & 0x0F )<<2)]; *output++ = ‘=‘; }else if( slen == 1) //恰好为一个字符 { *output++ = BASE_CODE[ (temp_data[0]&0x03) << 4]; *output++ = ‘=‘; *output++ = ‘=‘; } temp_data += 3; slen -= 3; vlen += 4; } *output = ‘\0‘; //this is very improtant return vlen;}/************************************************************************************************** * @fn GetCharIndex * * @brief This function get the mapping value. * * input parameters * * @param c - Base64 code * * output parameters * none * it has two ways to map from ciphertext to plaintext,one is lookup-table,and the other is value judgements. * @return original value************************************************************************************************** */unsigned char GetCharIndex(unsigned char c){ #if 1 if( ( c >= ‘A‘ ) && ( c <= ‘Z‘)) { return c - ‘A‘; }else if( (c >= ‘a‘) && (c <= ‘z‘ )) { return c-‘a‘+26; }else if( (c >= ‘0‘) && ( c <= ‘9‘)) { return c - ‘0‘ + 52; } else if( c == ‘+‘) { return 62; }else if( c == ‘/‘) { return 63; }else if(c == ‘=‘) { return 0xFF; } #else return base64_dec_map[c]; #endif return 0;}/************************************************************************************************** * @fn BaseDecode * * @brief This function decode the bindata into base64 format. * * input parameters * * @param input - the encoded input data * @param output - the decode output data * @param sLen - the length of encoded input data. * * output parameters * none * * @return vlen - the length of decode data ************************************************************************************************** */int Base64Decode(const unsigned char* input,unsigned char *output,int sLen){ static unsigned char lpCode[4] = {0}; unsigned char* data_temp = input; int vlen = 0; //Base64 length must be a multiple of 4 including ‘=‘ if( sLen % 4 ) { return -1; } while(sLen > 0 ) { lpCode[0] = GetCharIndex(data_temp[0]); lpCode[1] = GetCharIndex(data_temp[1]); lpCode[2] = GetCharIndex(data_temp[2]); lpCode[3] = GetCharIndex(data_temp[3]); if( lpCode[3] == 0xFF ) { if( lpCode[2] == 0xFF ) // if there has two ‘=‘ at the end { *output++ = (lpCode[0] << 2) | (lpCode[1] >>4); vlen +=1; break; }else // if there has one ‘=‘ at the end { *output++ = (lpCode[0] << 2) | (lpCode[1] >>4); *output++ = (lpCode[1] << 4) | (lpCode[2] >>2); vlen +=2; break; } }else { *output++ = (lpCode[0] << 2) | (lpCode[1] >>4); *output++ = (lpCode[1] << 4) | (lpCode[2] >>2); *output++ = (lpCode[2] << 6) | (lpCode[3]); data_temp+=4; sLen -=4; vlen +=3; } } *output = ‘\0‘; //this is very improtant return vlen;}/*main test function*/int test_base64(){ unsigned char* output_buffer = NULL; char input_str[100]={0}; int allocate_len; int input_len; int output_len; printf("Please input string : \n "); scanf("%s",input_str); input_len = strlen(input_str); printf("the length of input is %d \n",strlen(input_str)); //补齐字节数,使得输出缓存为4的倍数,这样来考虑,先把输入长度补齐到3的倍数,然后将其乘以4再除以3 allocate_len = ( input_len % 3 ) ? ( input_len + 3 - input_len%3 ) :( input_len); allocate_len = ( allocate_len * 4 )/3; output_buffer = (unsigned char*)malloc(allocate_len+1); //加1 很重要,用于结束编解码的输出字符串 if(NULL == output_buffer) { printf("allocate memory fail! \n"); return -1; }else { printf("success allocate %d bytes. \n",allocate_len); memset(output_buffer,0,allocate_len); } output_len = Base64Encode(input_str,output_buffer,input_len); printf("Base64ENcode(\" %s \" ,encoding output length is %d \") \n encode content is %s \" \n\n",input_str,output_len,output_buffer); memset(input_str,0,sizeof(input_str)); output_len = Base64Decode(output_buffer,input_str,output_len); printf("Base64Decode(\" %s \" ,decoding output length is %d \") \n decode content is %s \n",output_buffer,output_len,input_str); free(output_buffer); //release the allocated memory output_buffer = NULL;}
执行结果如下:

完成这篇博客,从基础知识的准备到base64原理的了解,再到最终代码的实现和调试,花费了一天的时间,具体原理不难,调试过程中,遇到了很多问题,深知,网上得来终觉浅,绝知此事要躬行。别人给出的代码,自己如果不敲一片,字字斟酌,如果只是匆匆扫过,是怎么样也不会体会别人的思路和方法。现在网络资源异常丰富,我们在别人的基础上,进行自己的改进和优化,博采众长,提升自己。
对代码来说,光说不练假把式,虽说是今天实现的只是一个小小的功能,把小功能步步都想清楚,各种情况都处理好,每天深入了解学习一个知识点,能够解决一个问题,那这一天就很有价值,没有白白度过。
Base64编码原理与应用