
首页 > 代码库 > 数据挖掘工具软件Weka学习教程
数据挖掘工具软件Weka学习教程
一、数据格式
理解数据格式后,就可以完全控制数据预处理过程。
1.1 ARFF格式
样例 | 说明 |
%整行注释 @relation person @attribute name string %半行注释 @attribute age numeric @attribute sex {male,female} @attribute birthday date "yyyy-MM-dd HH:mm:ss" @data "Zhang San",85,male,‘2011-06-10 00:00:00‘ Lisi,?,male,"2011-06-11 00:00:00" …… | 关系名,在Explorer界面显示 String 类型(文本挖掘使用) 数值类型(integer,real完全同义) 枚举类型(花括号枚举全部值) 日期类型(日期格式默认) 数据开始标志 (逗号分割数据) |
说明:
relation, string, data这些内置关键字无所谓大小写,使用string.equalsIgnoreCase()方法匹配字符串。但数据值严格区分大小写。
weka只解析4中数据类型:字符串、数值、枚举、日期。
数值型标志numeric、integer、real完全同义。
枚举类型无关键字,直接花括号扩住所有枚举值。
日期类型的格式字符串不指定,则默认使用 "yyyy-MM-dd‘T‘HH:mm:ss" (2011-06-10T00:00:00)。
缺失值用半角问号表示 ? ,不认识 NULL。
解析arff过程并非逐行读取数据,而是使用java.io.StreamTokenizer 。所以 string,nominal 如果值内没有空格,则不需要用引号包括。空行随便加。
1.2 CSV格式
weka对待csv格式的文件比较粗暴,对第一行指定的属性,假定是数值型,然后在后续读取对应的数据时,尝试解析数值,如果某一个解析失败,就将该属性重新标记为枚举型(无string、date);如果全部数据都能解析成数值,就认为该属性是数值型。
1.3 Arff Viewer
界面:GUI Chooser > Tools > Arff Viewer
[界面截图略]
作用:以表格形式显示数据。并可对数据初步处理。
点击表头对数据排序(单击正序排列、shift+单击逆序排列),然后处理噪声值。对特别大或特别小的数据,手动改为均值(右键表头> get mean)或缺失值(将值删除为空)。
注:csv格式的解析方式是内置的,属性被认为是数值还是枚举,在这里不能更改。
二、 数据理解
2.1 数据集概览
界面:GUI Chooser > Explorer按钮 > Preprocess面板
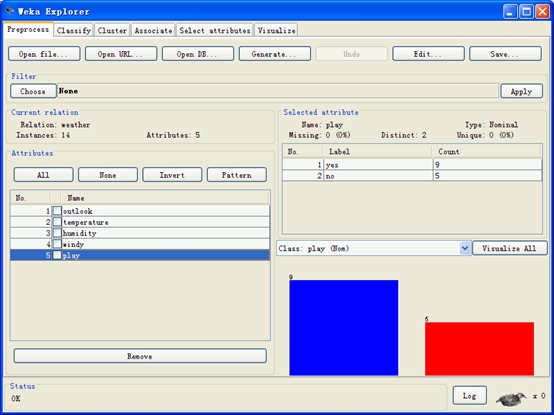
作用:
1、单属性统计信息浏览。
2、属性剔除。
3、对数据集做预处理(归一化、离散化等)。
2.2 单属性直方图
界面:GUI Chooser > Explorer按钮 > Preprocess面板 > Visualize All
[界面截图略]
作用:仅观察了解数据。
2.3 二维散点图
界面:GUI Chooser > Explorer按钮 > Visualize面板
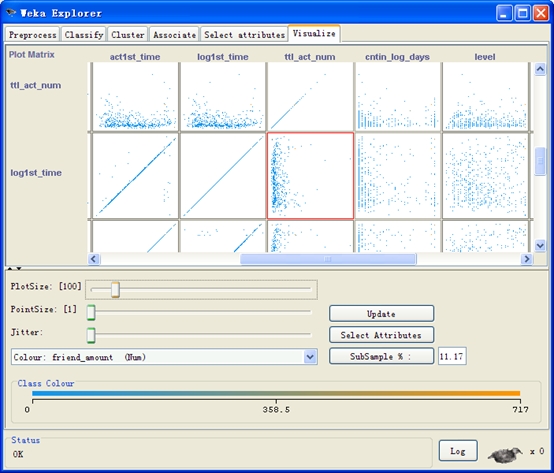
作用:
1、查看各属性之间的关系,深入理解数据集。
2、进行数据选择(放大散点图后进行)。
2.4 属性选择
界面:GUI Chooser > Explorer按钮 > Select attributes 面板
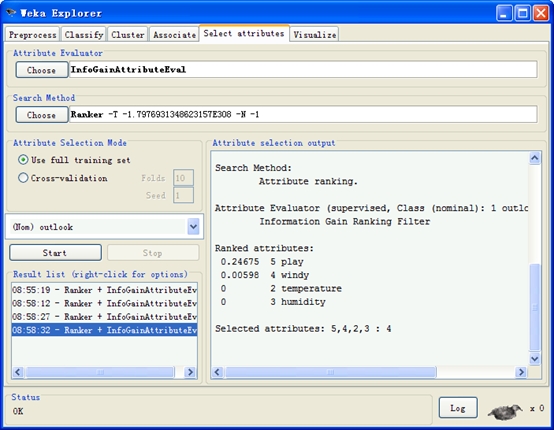
作用:
1、 查看所有属性对于某一个属性的重要程度(最能区分指定属性的,最重要,一般使用Gain指标)。
三、分类
界面:GUI Chooser > Explorer按钮 > Classify 面板
[界面截图略]
作用:分类。
●属性类型和算法选择
●算法参数
●测试集
●结果显示
四、聚类
界面:GUI Chooser > Explorer按钮 > Cluster 面板
[界面截图略]
作用:聚类。
●算法参数
●聚类模式
●结果显示
五、关联规则
界面:GUI Chooser > Explorer按钮 > Associate 面板
[界面截图略]
由于weka arff格式的限制,其关联规则分析挖掘功能很不实用。类似于背包分析的问题,需要自己写apriori算法。Apriori算法比较耗资源,可使用FP-Tree算法。
六、挖掘模型固化
界面:GUI Chooser > KnowledgeFlow按钮
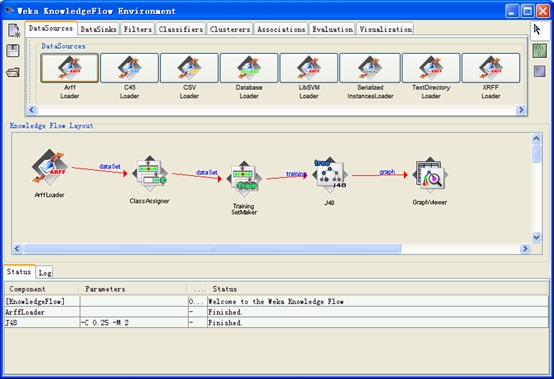
说明:知识流可以认为是weka内核的一个完全图形化接口,挖掘功能方面与Explorer一样。但这里可以将数据挖掘全过程中的操作用一个流程表示,并且可以保存起来,多次使用(每次使用只需要更改数据集)。
当对某一主题探索出合适的挖掘流程后,可以在这里固化一个挖掘模型,以后多次使用。
七、其他
7.1 Weka的实验界面主要用来在同一个训练集上对比不同的分类算法,可以看作是对挖掘探索的一个封装,控制方面的灵活性不佳。
7.2 命令行界面也是weka内核的一个接口。
本文出自 “神威新空间” 博客,请务必保留此出处http://abool.blog.51cto.com/8355508/1580796
数据挖掘工具软件Weka学习教程