
首页 > 代码库 > hadoop散记
hadoop散记
不写,默认是下面的转换类
job.setInputFormatClass(TextInputFormat.class)
List<InputSplit> InputFormat.getSplits首先对输入的数据做切分,切分后的split书面决定map的任务数;
RecordReader<K,V> InputFormat.createRecordReader(InputSplit split, ...)传入切分的数据,处理成key、value,然后把keyvalue值送给map执行,每一对key、value对都会调用一次map;
FileInputFormat<K, V> extends InputFormat<K, V>
List<InputSplit> FileInputFormat.getSplits
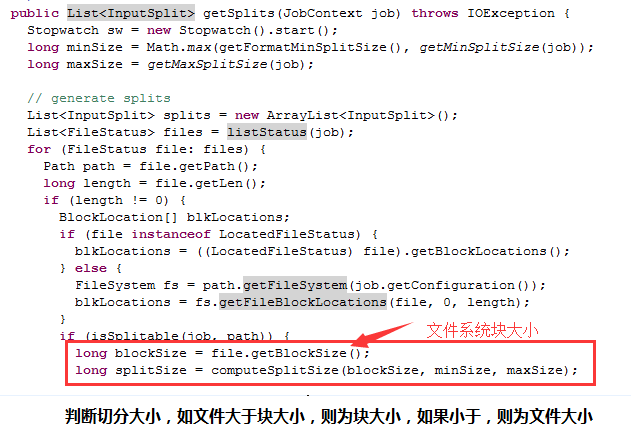
TextInputFormat extends FileInputFormat<LongWritable, Text>

hadoop散记
声明:以上内容来自用户投稿及互联网公开渠道收集整理发布,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任,若内容有误或涉及侵权可进行投诉: 投诉/举报 工作人员会在5个工作日内联系你,一经查实,本站将立刻删除涉嫌侵权内容。