
首页 > 代码库 > HBase介绍 (1)---数据模型
HBase介绍 (1)---数据模型
http://blog.csdn.net/heyutao007/article/details/5766896
BigTable是什么?Google的Paper对其作了充分的说明。字面上看就是一张大表,其实和我们想象的传统数据库的表还是有些差别的。松散数据可以说是介于Map Entry(key & value)和DB Row之间的一种数据。在我使用Memcache的时候,有时候的需求是需要存储的不仅仅是简单的一个key对应一个value,可能我需要类似于数据库表结构中多属性的存储,但是又不会有传统数据库表结构中那么多关联关系的需求,其实这类数据就是所谓的松散数据。BigTable最浅显来看就是一张很大的表,表的属性可以根据需求去动态增加,但是又没有表与表之间关联查询的需求。
互联网应用有一个最大的特点,就是速度,功能再强大,速度慢,还是会被舍弃。因此在大访问量的网站都采取前后的缓存来提升性能和响应时间。对于Map Entry类型的数据,集中式分布式Cache都有很多选择,对于传统的关系型数据,从MySQL到Oracle都给了很好的支持,唯有松散数据这类数据,采用前后两种解决方案都不能最大化它的处理能力。因此BigTable才有了它用武之地。
HBase 是一个针对结构化数据的可伸缩、分布式和面向列的动态模式数据库。它能有效和可靠地管理分布在数千个商品服务器上的大规模数据(千兆兆字节或更多)。 HBase 根据 Google 的 Bigtable 数据库建模,是 Apache Software Foundation 的 Hadoop 项目的子项目。
最适合使用Hbase存储的数据是非常稀疏的数据(非结构化或者半结构化的数据)。Hbase之所以擅长存储这类数据,是因为Hbase是column- oriented列导向的存储机制,而我们熟知的RDBMS都是row- oriented行导向的存储机制(郁闷的是我看过N本关于关系数据库的介绍从来没有提到过row- oriented行导向存储这个概念)。在列导向的存储机制下对于Null值得存储是不占用任何空间的。比如,如果某个表 UserTable有10列,但在存储时只有一列有数据,那么其他空值的9列是不占用存储空间的(普通的数据库MySql是如何占用存储空间的呢?)。
Hbase适合存储非结构化的稀疏数据的另一原因是他对列集合 column families 处理机制。 打个比方,ruby和python这样的动态语言和c++、java类的编译语言有什么不同? 对于我来说,最显然的不同就是你不需要为变量预先指定一个类型。Ok ,现在Hbase为未来的DBA也带来了这个激动人心的特性,你只需要告诉你的数据存储到Hbase的那个column families 就可以了,不需要指定它的具体类型:char,varchar,int,tinyint,text等等。
Hbase还有很多特性,比如不支持join查询,但你存储时可以用:parent-child tuple 的方式来变相解决。
注意:在撰写本文时,HBase 的最新版本是 V0.19.3。本文提供的信息适用于这个版本。
数据模型
HBase 数据被建模为多维映射,其中值(表单元)通过 4 个键索引:
value = http://www.mamicode.com/Map(TableName, RowKey, ColumnKey, Timestamp)> |
其中:
TableName是一个字符串。RowKey和ColumnKey是二进制值(Java 类型byte[])。Timestamp是一个 64 位整数(Java 类型long)。value是一个未解释的字节数组(Java™ 类型byte[])。
二进制数据被编码为 Base64,以便通过网络传输。
行键是表的主键,通常是一个字符串。行通过行键按字典顺序排序。
存储在表中的信息的结构为列族(column family),您可以将这种结构视为类别。每个列族可以拥有任意数量的成员,它们通过标签(或修饰符)识别。column 键由族名、: 号和标签组成。例如,对于系列 info 和成员 date,列键为 info:date。
一个 HBase 表模式定义多个列族,但当您向表中插入一行时,应用程序能够在运行时创建新成员。对于一个列族,表中的不同行可以拥有不同数量的成员。换句话说,HBase 支持一个动态模式 模型。
表 1 展示了一个名为 Persons 的 HBase 表的简单示例,该表有两个列族:name 和 contact。
| 行键 | 时间戳 | 列族 | |
|---|---|---|---|
| name | contact | ||
| 000001 | t3 | contact:http research.google.com/people/jeff/ | |
| t2 | name:first Jeffrey | ||
| t1 | name:last Dean | ||
| 000002 | t5 | name:first Gabriel | |
| t4 | name:last Mateescu | ||
一个空单元没有与单元的键相关联的值。在表 1 中,与键 (000002, contact:http, t4) 关联的单元为空。空单元不存储在 HBase 中,读取空单元类似于根据不存在的键从映射提取值。HBase 表以这种方法适应稀疏的 行。
对于任意行,一次只能访问一个列族的一个成员(这与关系数据库不同,在关系数据库中,一个查询可以访问来自一个行中的多个列的单元)。您可以将一个行中的一个列族的成员视为子行。
表被分解为多个表区域,等同于 Bigtable 片(tablet)。一个区域包含某个范围中的行。将一个表分解为多个区域是高效处理大型表的关键机制。
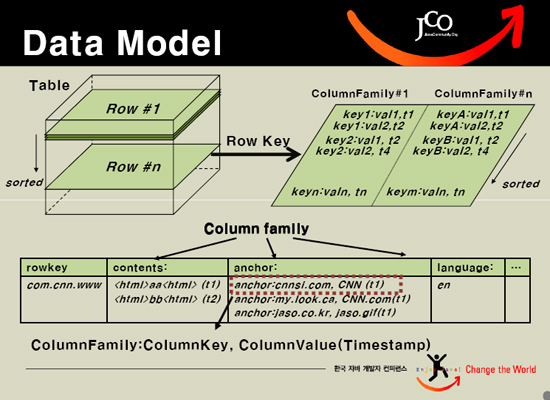
HBASE中的每一张表,就是所谓的BigTable。BigTable会存储一系列的行记录,行记录有三个基本类型的定义:Row Key,Time Stamp,Column。Row Key是行在BigTable中的唯一标识,Time Stamp是每次数据操作对应关联的时间戳,可以看作类似于SVN的版本,Column定义为:<family>:<label>,通过这两部分可以唯一的指定一个数据的存储列,family的定义和修改需要对HBASE作类似于DB的DDL操作,而对于label的使用,则不需要定义直接可以使用,这也为动态定制列提供了一种手段。family另一个作用其实在于物理存储优化读写操作,同family的数据物理上保存的会比较临近,因此在业务设计的过程中可以利用这个特性。
看一下逻辑数据模型:
Row Key | Time Stamp | Column "contents:" | Column "anchor:" | Column "mime:" | |
"com.cnn.www" | t9 | "anchor:cnnsi.com" | "CNN" | ||
t8 | "anchor:my.look.ca" | "CNN.com" | |||
t6 | "<html>..." | "text/html" | |||
t5 | "<html>..." | ||||
t3 | "<html>..." |
| |||
上表中有一列,列的唯一标识为com.cnn.www,每一次逻辑修改都有一个timestamp关联对应,一共有四个列定义:<contents:>,<anchor:cnnsi.com>,<anchor:my.look.ca>,<mime:>。如果用传统的概念来将BigTable作解释,那么BigTable可以看作一个DB Schema,每一个Row就是一个表,Row key就是表名,这个表根据列的不同可以划分为多个版本,同时每个版本的操作都会有时间戳关联到操作的行。
再看一下HBASE的物理数据模型:
Row Key | Time Stamp | Column "contents:" |
"com.cnn.www" | t6 | "<html>..." |
t5 | "<html>..." | |
t3 | "<html>..." |
Row Key | Time Stamp | Column "anchor:" | |
"com.cnn.www" | t9 | "anchor:cnnsi.com" | "CNN" |
t8 | "anchor:my.look.ca" | "CNN.com" | |
Row Key | Time Stamp | Column "mime:" |
"com.cnn.www" | t6 | "text/html" |
物理数据模型其实就是将逻辑模型中的一个Row分割成为根据Column family存储的物理模型。
对于BigTable的数据模型操作的时候,会锁定Row,并保证Row的原子操作。
HBase介绍 (1)---数据模型