
首页 > 代码库 > Cortex依赖管理
Cortex依赖管理
cortex对模块的依赖基于semantic version进行管理,如果熟悉npm的模块管理方式,大家都了解node的模块是放在node_modules这个目录下,每个模块自己的依赖都放在自己目录下的node_modules里面,这样避免了不同模块之间的共同依赖版本冲突的问题。
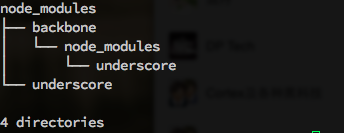
而在前端开发中,套嵌的依赖是不可能的,因为:
1) web开发的载入是异步的,不能像node那样去在运行时检测文件上依赖是否存在,远程检测模块是否存在再载入非常耗时。
2) 文件大小限制,相对于磁盘的廉价,http请求和页面载入重复的js文件的开销都是非常大的,不可能通过文件套嵌的方式来实现。
所以cortex的模块管理是基于一个扁平化的结构:
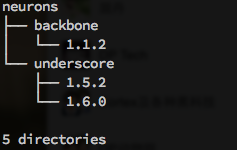
那么一个模块怎么知道他需要载入的第三方模块是什么版本呢?比如store.js, 在代码中使用时都是
require(‘store.js‘)
这个信息只能告诉我们依赖什么模块,而不知道具体版本。通常的loader,比如requirejs,的做法是对模块进行管理, 模块的映射是:
“` store.js =./mod/store.js.1.0.0.js ““
这相当于一个全局变量,所有的store.js都会被固定到某个版本,即使存在第三方依赖不兼容1.0.0的版本.
component和bower也是采用扁平化的方式来储存模块,但只有一层目录。如果在依赖树中存在这两个不同版本,不管是否兼容,最终都会只产生一个版本,而这个版本完全取决于依赖申明的层次,顺序和在执行install时异步任务执行的顺序,可以说,是随机的。
如果一个模块A依赖于jquery的一个低版本, 1.8.3, 而另一个模块B依赖于1.9.1,最终结果在component中是没法控制,取决于jquery在依赖树中的位置,导致一个使用jquery@1.9.1功能的模块最终安装的是jquery@1.8.3而出错。
而这样的错误是只有在代码执行时才会被发现的,对于不熟悉的人也很难意识到是某个模块中依赖问题,需要对component比较熟悉,并且对自己使用的模块中依赖也了解人才能够很快的发现问题所在。
这样模块的开发者和使用者都需要管理代码的兼容问题,使用者需要对使用的模块有什么依赖也有了解,否则他可能会碰到一个很难以发现bug。任何一个不兼容的模块都会破坏这个生态环境,从而使得开发者不敢使用已有的模块而重复的造轮子。
而在cortex中, 正确的版本申明能够使得只有模块的开发者才需要关心自己的模块依赖。而使用者完全不用担心依赖树上的深层次组件会影响到自己的代码。 如果在之前的例子中,模块A的开发者在开发时是依赖着jquery@1.8.3, 他可以根据semantic version申明为:
jquery@^1.8.3
模块B则申明为:
jquery@^1.9.1
这样cortex会发现,存在着jquery@1.9.1在保证兼容的情况下满足两个需求, 最终会载入正确的jquery@1.9.1。而模块A和B的使用者不需要关系A和B到底使用了什么版本的jquery, 他只要管理好A和B就好,cortex会帮他处理深层次依赖的问题。
由于其他的loader基本上都是基于 “name => js file”的映射来载入js文件,从而在执行环境中无法区分在不同的代码中name可能代表的含义不同的需求,这也是cortex目前只支持使用neuron作为loader的原因。
有了版本信息, 如果有两个模块依赖了store.js的相同版本,store.js只会载入一份,而不会每个自带一份。而cortex支持semantic version的range来申明依赖,使得只要两个版本是兼容的,就不会出现两份代码。
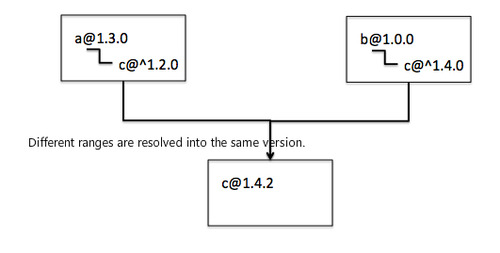
而对于不兼容的代码,用户也不用担心功能性失效或者新版本破坏之前的逻辑,即使在一个页面多层次的引用到一个模块的不同版本的情况下, 不同的代码之间也能够很好的相互兼容。而这样的稳定性,对于大型项目来是非常重要的。
在对性能要求很高的环境中,可以对于特定代码进行优化, 希望排除多余的文件,可以通过命令
cortex ls store.js
会列出在依赖树上的所有的store.js,可以发现是哪个模块依赖了古老的版本,从而去升级或者替换依赖。