
首页 > 代码库 > Dom4j解析XML
Dom4j解析XML
1、Dom4j概述
dom4j is an easy to use, open source library for working with XML, XPath and XSLT on the Java platform using the Java Collections Framework and with full support for DOM, SAX and JAXP.
dom4j官方网址:dom4j
dom4j源码下载:dom4j download
本示例中,需要导入dom4j.jar包,才能引用dom4j相关类,dom4j源码和jar包,请见本示例【源码下载】或访问 dom4j
org.dom4j包,不仅包含创建xml的构建器类DocumentHelper、Element,而且还包含解析xml的解析器SAXReader、Element,包含类如下:
org.dom4j
org.dom4j.DocumentHelper;
org.dom4j.Element;
org.dom4j.io.SAXReader;
org.dom4j.io.XMLWriter;
org.dom4j.DocumentException;
sdk源码查看路径(google code)
创建和解析xml的效果图:
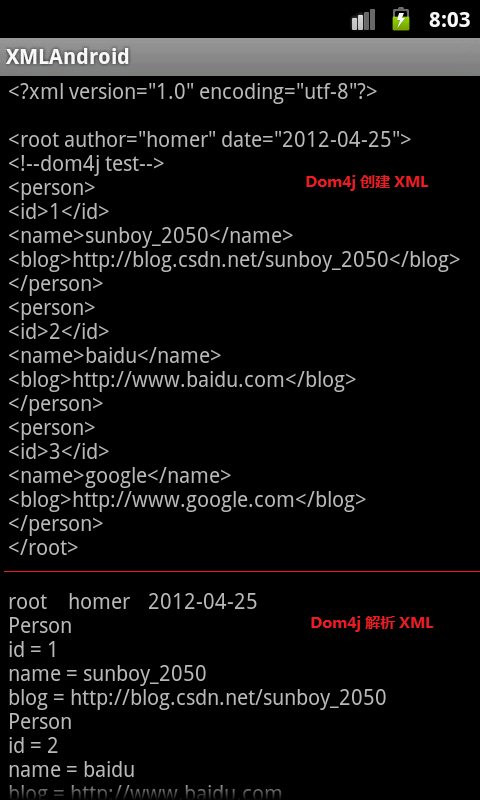
2、Dom4j 创建 XML
Dom4j,创建xml主要用到了org.dom4j.DocumentHelper、org.dom4j.Document、org.dom4j.io.OutputFormat、org.dom4j.io.XMLWriter
首先,DocumentHelper.createDocument(),创建 org.dom4j.Document 的实例 doc
接着,通过doc,设置xml属性doc.setXMLEncoding("utf-8")、doc.addElement("root")根节点,以及子节点等
然后,定义xml格式并输出,new XMLWriter(xmlWriter, outputFormat)
Code
- /** Dom4j方式,创建 XML */
- public String dom4jXMLCreate(){
- StringWriter xmlWriter = new StringWriter();
- Person []persons = new Person[3]; // 创建节点Person对象
- persons[0] = new Person(1, "sunboy_2050", "http://blog.csdn.net/sunboy_2050");
- persons[1] = new Person(2, "baidu", "http://www.baidu.com");
- persons[2] = new Person(3, "google", "http://www.google.com");
- try {
- org.dom4j.Document doc = DocumentHelper.createDocument();
- doc.setXMLEncoding("utf-8");
- org.dom4j.Element eleRoot = doc.addElement("root");
- eleRoot.addAttribute("author", "homer");
- eleRoot.addAttribute("date", "2012-04-25");
- eleRoot.addComment("dom4j test");
- int personsLen = persons.length;
- for(int i=0; i<personsLen; i++){
- Element elePerson = eleRoot.addElement("person"); // 创建person节点,引用类为 org.dom4j.Element
- Element eleId = elePerson.addElement("id");
- eleId.addText(persons[i].getId()+"");
- Element eleName = elePerson.addElement("name");
- eleName.addText(persons[i].getName());
- Element eleBlog = elePerson.addElement("blog");
- eleBlog.addText(persons[i].getBlog());
- }
- org.dom4j.io.OutputFormat outputFormat = new org.dom4j.io.OutputFormat(); // 设置xml输出格式
- outputFormat.setEncoding("utf-8");
- outputFormat.setIndent(false);
- outputFormat.setNewlines(true);
- outputFormat.setTrimText(true);
- org.dom4j.io.XMLWriter output = new XMLWriter(xmlWriter, outputFormat); // 保存xml
- output.write(doc);
- output.close();
- } catch (Exception e) {
- e.printStackTrace();
- }
- savedXML(fileName, xmlWriter.toString());
- return xmlWriter.toString();
- }
运行结果:
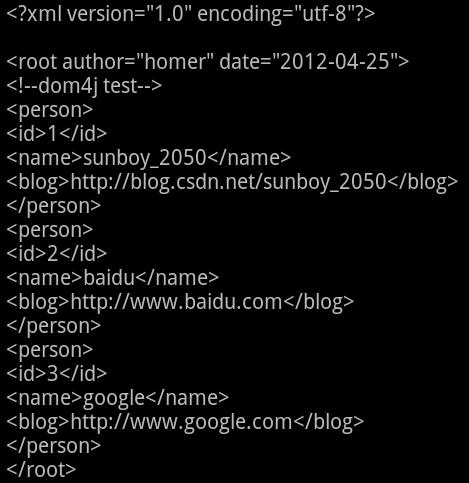
3、Dom4j 解析 XML
Dom4j,解析xml主要用到了org.dom4j.io.SAXReader、org.dom4j.Document、doc.getRootElement(),以及ele.getName()、ele.getText()等
首先,创建SAXReader的实例reader,读入xml字节流 reader.read(is)
接着,通过doc.getRootElement()得到root根节点,利用迭代器取得root下一级的子节点eleRoot.elementIterator()等
然后,得到解析的xml内容xmlWriter.append(xmlHeader)、xmlWriter.append(personsList.get(i).toString())
解析一:标准解析(Iterator 迭代)
Code
- /** Dom4j方式,解析 XML */
- public String dom4jXMLResolve(){
- StringWriter xmlWriter = new StringWriter();
- InputStream is = readXML(fileName);
- try {
- SAXReader reader = new SAXReader();
- org.dom4j.Document doc = reader.read(is);
- List<Person> personsList = null;
- Person person = null;
- StringBuffer xmlHeader = new StringBuffer();
- Element eleRoot = doc.getRootElement(); // 获得root根节点,引用类为 org.dom4j.Element
- String attrAuthor = eleRoot.attributeValue("author");
- String attrDate = eleRoot.attributeValue("date");
- xmlHeader.append("root").append("\t\t");
- xmlHeader.append(attrAuthor).append("\t");
- xmlHeader.append(attrDate).append("\n");
- personsList = new ArrayList<Person>();
- // 获取root子节点,即person
- Iterator<Element> iter = eleRoot.elementIterator();
- for(; iter.hasNext(); ) {
- Element elePerson = (Element)iter.next();
- if("person".equals(elePerson.getName())){
- person = new Person();
- // 获取person子节点,即id、name、blog
- Iterator<Element> innerIter = elePerson.elementIterator();
- for(; innerIter.hasNext();) {
- Element ele = (Element)innerIter.next();
- if("id".equals(ele.getName())) {
- String id = ele.getText();
- person.setId(Integer.parseInt(id));
- } else if("name".equals(ele.getName())) {
- String name = ele.getText();
- person.setName(name);
- } else if("blog".equals(ele.getName())) {
- String blog = ele.getText();
- person.setBlog(blog);
- }
- }
- personsList.add(person);
- person = null;
- }
- }
- xmlWriter.append(xmlHeader);
- int personsLen = personsList.size();
- for(int i=0; i<personsLen; i++) {
- xmlWriter.append(personsList.get(i).toString());
- }
- } catch (DocumentException e) {
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlWriter.toString();
- }
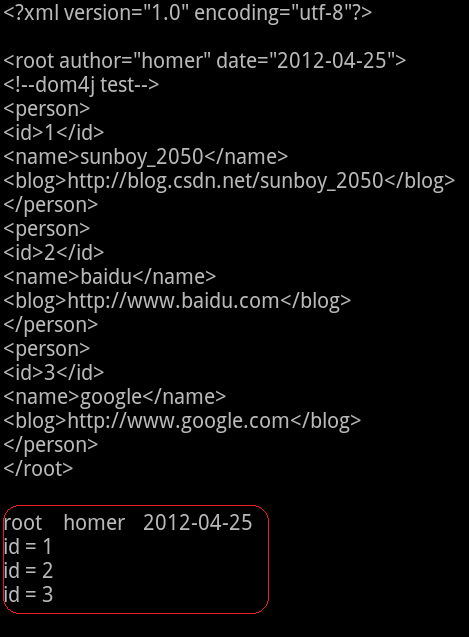
运行结果:

解析二:选择性解析(XPath路径)
Dom4j+XPath,选择性只解析id,doc.selectNodes("//root//person//id")
Code
- /** Dom4j方式,解析 XML(方式二) */
- public String dom4jXMLResolve2(){
- StringWriter xmlWriter = new StringWriter();
- InputStream is = readXML(fileName);
- try {
- org.dom4j.io.SAXReader reader = new org.dom4j.io.SAXReader();
- org.dom4j.Document doc = reader.read(is);
- List<Person> personsList = null;
- Person person = null;
- StringBuffer xmlHeader = new StringBuffer();
- Element eleRoot = doc.getRootElement(); // 获得root根节点,引用类为 org.dom4j.Element
- String attrAuthor = eleRoot.attributeValue("author");
- String attrDate = eleRoot.attributeValue("date");
- xmlHeader.append("root").append("\t\t");
- xmlHeader.append(attrAuthor).append("\t");
- xmlHeader.append(attrDate).append("\n");
- personsList = new ArrayList<Person>();
- @SuppressWarnings("unchecked")
- List<Element> idList = (List<Element>) doc.selectNodes("//root//person//id"); // 选择性获取全部id
- Iterator<Element> idIter = idList.iterator();
- while(idIter.hasNext()){
- person = new Person();
- Element idEle = (Element)idIter.next();
- String id = idEle.getText();
- person.setId(Integer.parseInt(id));
- personsList.add(person);
- }
- xmlWriter.append(xmlHeader);
- int personsLen = personsList.size();
- for(int i=0; i<personsLen; i++) {
- xmlWriter.append("id = ").append(personsList.get(i).getId()+"").append("\n");
- }
- } catch (DocumentException e) {
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlWriter.toString();
- }
注:借助 XPath 解析 XML 时,需要导入 jaxen;本示例需要导入的是最新的jaxen包jaxen-1.1.3.jar,可以下载本示例下面【源码下载】或 访问 jaxen jar
Jaxen is an open source XPath library written in Java. It is adaptable to many different object models, including DOM, XOM, dom4j, and JDOM. Is it also possible to write adapters that treat non-XML trees such as compiled Java byte code or Java beans as XML, thus enabling you to query these trees with XPath too.
jaxen 官方网址:jaxen
jaxen下载jar包:jaxen jar 或 jaxen jar
jaxen源码查看:jaxen src 或 jaxen trunk
运行结果:
4、Person类
请参见前面博客 Android 创建与解析XML(二)—— Dom方式 【4、Person类】
源码下载
参考推荐:
dom4j(官方网站)
dom4j src(源码下载)
dom4j src and jar(google code)
jaxen(jaxen 官方网址)
jaxen jar(jaxen jar包下载)
jaxen src(jaxen在线源码)
dom4j 解析 XML(IBM)
dom4j和XPath解析XML
dom4j 属性值回车换行问题