
首页 > 代码库 > 【转】机器学习和神经科学:你的大脑也在进行深度学习吗?
【转】机器学习和神经科学:你的大脑也在进行深度学习吗?
- 假说一:大脑优化成本函数 The Brain Optimizes Cost Functions
- 假说二:不同脑区在发展的不同时期使用多样化的成本函数 Cost Functions Are Diverse across Areas and Change over Development
- 假说三:大脑中的专门系统高效解决关键计算问题 Specialized System Allow Efficient Solution of Key Computational Problems
链接:https://zhuanlan.zhihu.com/p/23021318
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
导语
深度学习的灵感起源可能是神经科学,但近年来的发展毫无疑问已经自成一派,(几乎)与神经科学无关了。机器学习专家们感兴趣的是如何进一步优化他们的算法;神经科学家们则更想知道人脑,而非深度网络们,是如何工作的。
 这一 “大脑电路” 图像同时被计算机学家们和生物学家们两方面所摈弃——它既不是一副真正的深度网络结构图,也不能描绘大脑的工作原理。
这一 “大脑电路” 图像同时被计算机学家们和生物学家们两方面所摈弃——它既不是一副真正的深度网络结构图,也不能描绘大脑的工作原理。
Konrad Kording 试图改变这一趋势,重启神经科学和机器学习之间的对话。他与 Adam Marblestone (MIT Media Lab) 以及 Greg Wayne (Google Deepmind) 合作的文章《走向深度学习与神经科学的结合》阐述了这一理念,6月存档于bioRxiv,9月发表于《计算神经科学前沿》。
一些读者可能看过 神经科学家能理解微处理器吗?大数据时代神经科学的理论困境,也是介绍 Kording 的作品。如果说上一篇文章提出了一个尖锐的问题——神经科学现有研究手段是否令人满意——这篇文章或许可以被看作是提出了解决问题的可能途径之一:采纳深度学习中发展出的思想来研究大脑。文章很长,涉及的内容较多,在这里先只介绍总体思路,许多分支尽管有趣会暂时略过。十分推荐阅读原文(开放访问)。
现代机器学习的三个趋势
作者首先指出现代机器学习的三个特征:
- 专注于优化成本函数
- 近期工作引入复杂的成本函数
- 这包括空间和时间上不平均的成本函数,以及网络内部产生的成本函数。
- 机器学习的结构本身也变得越来越多元化
- 新发展的结构包括记忆单元,“胶囊”,外部记忆,指针和硬编码的算术指令等。
大脑工作方式的三个假说
指出上面的三个机器学习特征后,作者提出了三个假说:
- 假说一:大脑优化成本函数 The Brain Optimizes Cost Functions
- 假说二:不同脑区在发展的不同时期使用多样化的成本函数 Cost Functions Are Diverse across Areas and Change over Development
- 假说三:大脑中的专门系统高效解决关键计算问题 Specialized System Allow Efficient Solution of Key Computational Problems
跑题一分钟,此小节可以跳过
老实说,我6月份看到这里的感觉是——
好坑爹!
看上去这像是又一篇空洞而无解释力的脑洞文章:成本函数是一个特别宽泛的概念,为神经系统的活动找到成本函数很平凡。假说二明显是个补丁嘛!找不到全局成本函数就说是局部的,又怕时间上不稳定就说是发展的结果。。。假说三什么都没说啊,脑区专业化分工谁不知道?
就这样,我把文章丢到一边。隔了三个月文章居然过了评审,才又下了新版本来看。
这次我先跳到最后看了结论,结果一下子就被吸引住了:
In other words, this framework could be viewed as proposing a kind of “society” of cost functions and trainable networks, permitting internal bootstrapping processes reminiscent of the Society of Mind (Minsky, 1988). In this view, intelligence is enabled by many computationally specialized structures, each trained with its own developmentally regulated cost function, where both the structures and the cost functions are themselves optimized by evolution like the hyperparameters in neural networks.虽然只不过是换了句话来说,不知怎么就觉得很符合直觉了。也许是闵斯基的大名加持,不过更可能的是成本函数用生物学家的话来说就是驱动力 (drive),而驱动力的多元化是我最近恰好在思考的一个问题。
换句话说,这一框架可以被看成是一种由成本函数和可训练网络所构成的“社会”,从而实现类似于闵斯基在《心灵的社会》中提到的内在自举过程。在这一观点中,智能是由许多特别的计算结构所实现的,每一个是由其受控于发展的成本函数所训练,而结构本身和成本函数都像超参数一样由进化所优化 。
跑题结束,欢迎回来
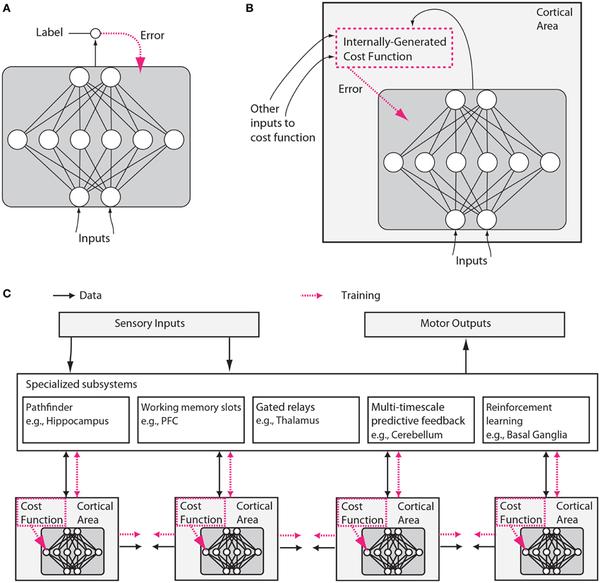 上面是本篇嘴炮文章的唯一一副示意图。图 A 是传统机器学习的典型结构,红色虚线为成本函数(以误差的形式输入网络)。图 B 则是假想的大脑神经网络,成本函数是根据外部输入在系统内部计算而得出的。图 C 中,多个不同脑区分别根据不同的成本函数训练,并彼此互相影响。
上面是本篇嘴炮文章的唯一一副示意图。图 A 是传统机器学习的典型结构,红色虚线为成本函数(以误差的形式输入网络)。图 B 则是假想的大脑神经网络,成本函数是根据外部输入在系统内部计算而得出的。图 C 中,多个不同脑区分别根据不同的成本函数训练,并彼此互相影响。
大脑可以优化成本函数 The brain can optimize cost functions
一个试图统一机器学习与神经系统的理论所遇到的第一个诘难一定是:神经系统怎么可能实现反向传播 (backpropagation)???
这是一个首要的问题,作者一口气写了八页纸。其核心思想为
(a) the brain has powerful mechanisms for credit assignment during learning that allow it to optimize global functions in multi-layer networks by adjusting the properties of each neuron to contribute to the global outcome, and that (b) the brain has mechanisms to specify exactly which cost functions it subjects its networks to, i.e., that the cost functions are highly tunable, shaped by evolution and matched to the animal‘s ethological needs. Thus, the brain uses cost functions as a key driving force of its development, much as modern machine learning systems do.
(a) 大脑有足够强力的机制来解决功劳分配问题。通过改变多层网络中每个神经元的性质,大脑可以优化整体的成本函数。
(b) 大脑有机制为其各网络精确分配不同的成本函数,即,成本函数非常可控,受到进化和动物自身生态需求的调控。
因此,大脑将成本函数作为其发展的决定性驱动力,正如当今的机器学习系统一样。
全文太 luo 长 li 不 luo 翻 suo,在这里只提一些看起来有趣的模型。(过于技术化,暂时放到文章末尾)
机器学习启发的神经科学 Machine Learning Inspired Neuroscience
之所以提出假说,当然是为了指导实践——是否有可能检验“大脑中有多种多样的成本函数来指导神经回路的学习”这一假设呢?
1. 通过猜测成本函数可以预测网络的状态:网络应当处于该成本函数所指定的优化状态。
2. 对成本函数的优化必然涉及到参数空间的梯度下降。或者说,在梯度下降方向的运动应当多于垂直方向的无意义旋转。如果可以观测神经网络中的权重的话(看到这里我真的笑出声哈哈哈哈哈哈),应该可以发现权重在进行梯度下降。
3. 根据1,外界干扰将使系统偏离优化状态。通过改变突触的权重,我们可以产生一个小的干扰,并预测系统将回归到同一个优化状态。这在运动领域已经开始变得可能(通过脑机接口BMI)。
4. 如果我们知道哪些细胞和连接负责传递误差信号,那么可以通过刺激指定的连接来给系统强加一个用户定义的成本函数。这将等同于把相关脑回路当做一个可训练的深度网络,从而研究其学习。在另一端,也可以通过脑机接口输入新的信息来研究其行为是否符合优化原则 (Dadarlat et al., 2015)。
5. 通过假想的候选成本函数来训练人工神经网络,可以和实际脑回路进行对比来测试假说(这一方法已经被多人应用)
神经科学启发的机器学习
作者相信大脑是进化所产生的隐态机器学习机制。那么大脑应该可以高效地优化多种数据下的多种成本函数。事实上,相比于现有的机器学习系统,大脑的硬件十分缓慢(受限于生化反应的速率);而对非线性,不可微分,时间上随机,基于脉冲的拥有大量反馈连接的系统如何进行优化,我们所知甚少。在系统构架层面,大脑可用的刺激展示次数少,作用于多个不同的时间框架,并采用主动学习。如果大脑果然是机器学习的范例(特别地,如果它的确解决了多层网络的功劳分配问题),那么我们将学到很多有用的优化算法。
另一方面,即使大脑并不使用反向传递,我们也将学到一种全新的非反向传递的技巧。
机器学习领域中已经开始研究如何用网络产生成本函数 (Watter et al., 2015)。通过考察大脑如何在发展过程中逐渐产生和适用不同的成本函数将帮助我们在机器学习中更好地设计成本函数以及层级行为。
机器学习正在发生的结构多元化亦可以从大脑结构的多元化中获益。
The brain combines a jumble of specialized structures in a way that works. Solving this problem de novo in machine learning promises to be very difficult, making it attractive to be inspired by observations about how the brain does it.
大脑将一堆特殊结构以一种有效的方式组合在一起。在机器学习中重新解决这一问题将会非常困难——这就是为什么通过观察大脑如何做到这一点如此有吸引力。
进化将成本函数和优化算法分开了吗? Did Evolution Separate Cost Functions from Optimization Algorithms?
深度学习之所以成功,是因为其将机器学习分成了两个部分:1 一个算法,反向传播,用于高效而分布式地进行优化; 2 将任何问题转换成合适的成本函数的技巧。今天的深度学习,大部分的工作都在寻找更合适的成本函数。
大脑在进化中是否也找到了这一方法呢?作者认为是的:不同的皮层区域可能分享相同的优化算法(微结构),但接受不同的数据和成本函数。事实上,针对制定皮层区域的成本函数可能是作为输入与数据本身一同传递的。
另一种可能则是,在皮层微结构(回路)中,一部分连接和学习规则决定了优化算法(固定);另一些则决定成本方程(可变)。这一思路可类比于FPGA (这里不得不吐槽真是脑洞大开)。
结论
文章的结论部分很有共鸣,这里大致翻译如下。
由于大脑的复杂度和多变性,纯粹的自下而上的神经数据分析面临解释的困难。理论框架可以被用于约束假说空间,从而允许研究者先解决高层的原则和系统结构,再“放大”并解决细节。现有的自上而下的理论框架包括熵最大化,有效编码,贝叶斯推测的可靠近似,预测误差的最小化*,吸引子动力学,模块化,符号运算能力,等等 (Pinker, 1999; Marcus, 2001; Bialek, 2002; Knill and Pouget, 2004; Bialek et al., 2006; Friston, 2010)。许多这类自上而下的理论本质上都是对单一计算结构的单一成本函数的优化。我们将这些假说进行扩展,提出多元化和发展中的成本函数群体,以及多个专业化的子系统。
许多神经科学家专注于寻找“神经编码”,即哪些刺激易于产生指定神经元或脑区的活动。但是如果大脑的确对成本函数进行优化,那么我们就要注意到简单的成本函数可以产生复杂的刺激回应。这可能使我们转向另一类问题。神经科学与机器学习间更加深入的对话可以帮助澄清很多问题。机器学习大部分都专注于更快地进行神经网络中从头到尾的梯度下降。神经科学可能为机器学习带来许多层面的启示。大脑所采用的优化算法经过了数百万年的进化。大脑可能找到了使用异质化的在发展中彼此影响的成本函数群体通过引导无监督学习后果来简化学习的方法。大脑中进化出的各种专门化结构可能提示我们如何提高面临多种计算问题和跨越多个时间框架时学习系统的效率。通过寻求神经科学提供的洞见,机器学习可能迈向在一个结构异质化,标记数据有限的世界中进行学习的强人工智能。
在某种意义上我们的假说与流行理论相反。并没有单一的优化机制,单一的成本函数,单一的表现形式,或者同质化的结构。所有这些异质化的元素由优化内部产生的成本函数这一原则统一在一起。许多早期人工智能途径都拒绝单一理论。例如,Minsky 和 Papert 在 《心灵的社会》中的工作,以及更广泛的,连接主义系统中由遗传预备和内部自引导的发展理论,强调智能需要一个由内部检测者和评判者组成的系统,特殊化的交流与存储机制,以及简单控制系统的层级化组织。
在这些早期工作进行时,人们还不知道基于梯度的优化可以带来强大的特征代表和行为政策。这里提出的理论可以被看作是针对流行的从头到尾的优化,重新提出异质化的方法。换句话说,这一框架可以被看成是一种由成本函数和可训练网络所构成的“社会”,从而实现类似于闵斯基在《心灵的社会》中提到的内在自举过程。在这一观点中,智能是由许多特别的计算结构所实现的,每一个是由其受控于发展的成本函数所训练,而结构本身和成本函数都像超参数一样由进化所优化 。
---被放到末尾的一些技术细节---
大脑可以优化成本函数 The brain can optimize cost functions
2.1 局部自组织和优化不需要多层功劳分配 Local Self-organization and Optimization without Multi-layer Credit Assignment
Pehlevan and Chklovskii 2015 提出,一类Hebbian可塑性可被看做是提取输入主成分(PC)的过程,从而最小化重构误差。
2.2. 优化的生物基础 Biological Implementation of Optimization
2.2.1. 多层网络需要高效的梯度下降 The Need for Efficient Gradient Descent in Multi-layer Networks
梯度下降的重要性众所周知,这里不多谈。知乎有一个话题就是专门讲梯度下降的。
2.2.2. 梯度下降的生物学近似 Biologically Plausible Approximations of Gradient Descent
大脑中可能用来实现对梯度下降算法近似的可能机制意外地多。其共同点为利用反馈连接传播误差。一个例子是 O‘Reilly 的 XCAL 算法 (O‘Reilly et al., 2012),通过本地的 Hebbian 学习法则实现了误差的反向传播。
实现反向传播的另一个可能途径是基于脉冲时间的可塑性 (STDP)。Hinton 就将此阐释为神经元可以通过脉冲速率的时间导数来编码反向传播所需的误差导数 (Hinton, 2007, 2016)。
还有一种可能的机制则涉及到独立于前馈连接强度的随机反馈连接。被称为“反馈对齐”的模型中,通过突触正规化和前馈与反馈连接的符号一致性,可以实现几乎和反向传播一样好的误差计算 (Liao et al., 2015)。
2.2.2.1. 时间功劳分配 Temporal credit assignment:
以上讨论中一个重要的未解决问题是时间功劳分配:在反复网络 (recurrent nets) 中,为了实现“时域反向传播 (BPTT)”,机器学习使用的方法是把网络在时间中展开 (unroll)。神经系统似乎显然无法将自己在时间中的活动展开来进行反向传播。
作者给出了几个解决思路。其一为通过记忆体来把时间上的功劳分配问题空间化 (例如 Weston et al., 2014)。
另一种方案来自于对反复网络监督式学习的研究。在 Sussilo and Abbott, 2009 所提出的FORCE 模型中,网络的输出被钳在指定目标,同时由网络内部产生的随机涨落提供反馈信号来更新权重。
2.2.2.2. 脉冲网络 Spiking networks
2.3. 生物学习的其他原则 Other Principles for Biological Learning
很明显,即使大脑确实采用了近似于反向传播的优化算法,也不能排除其他完全不同的算法。
2.3.1. 利用生物神经基础 Exploiting Biological Neural Mechanisms
特别地,当我们考察单个神经元的结构就会发现(这些都是老生常谈):神经元的树突可以进行局部运算;神经元包含多个部分 (compartments),每个神经元可以视作一个局部网络;神经元产生动作电位时,反向(向树突)传播的电信号更加强烈地传向最近活动的分支,可能简化了功劳分配问题(K?rding and K?nig, 2000);等等。
生物神经网络一个重要的特征是神经调节剂:同一个神经网络根据神经调节状态的不同,可以被看作是在多个重合的回路之间进行切换 (Bargmann, 2012; Bargmann and Marder, 2013)。这可能允许不同回路之间分享习得的权重。
2.3.2. 皮层中的学习 Learning in the Cortical Sheet
皮层的6层结构非常引人注目,有多个学习理论试图解释这一不断重复的结构。通常都认为皮层通过预测进行无监督学习(O‘Reilly et al., 2014b; Brea et al., 2016)。这其中包括了直接将皮层结构对应到贝叶斯推理中信息传递的努力(Lee and Mumford, 2003; Dean, 2005; George and Hawkins, 2009),而另一些工作则试图用学习理论来解释观测到的皮层活动。
这些和其他一些关于皮层运作的初步理论都超越了反向传播。
---
* 这一理论可以参考赵思家的文章:大脑无时无刻不在「预测」世界
原文
Marblestone, A. H., Wayne, G. & Kording, K. P. Toward an Integration of Deep Learning and Neuroscience. Front. Comput. Neurosci.10, 1–61 (2016).
Frontiers | Toward an Integration of Deep Learning and Neuroscience
其他参考文献
Bargmann, C. I. (2012). Beyond the connectome: how neuromodulators shape neural circuits. Bioessays 34, 458–465. doi: 10.1002/bies.201100185.
Bargmann, C. I., and Marder, E. (2013). From the connectome to brain function. Nat. Methods 10, 483–490. doi: 10.1038/nmeth.2451
Bialek, W. (2002). “Thinking about the brain,” in Physics of Bio-Molecules and Cells, Vol. 75, eds F. Flyvbjerg, F. Jülicher, P. Ormos, and F. David (Berlin; Heidelberg: Springer), 485–578.
Bialek, W., De Ruyter Van Steveninck, R., and Tishby, N. (2006). “Efficient representation as a design principle for neural coding and computation,” in 2006 IEEE International Symposium on Information Theory, (Los Alamitos: IEEE), 659–663.
Brea, J., Gaál, A. T., Urbanczik, R., and Senn, W. (2016). Prospective coding by spiking neurons. PLoS Comput. Biol. 12:e1005003. doi: 10.1371/journal.pcbi.1005003
Dadarlat, M. C., O‘Doherty, J. E., and Sabes, P. N. (2015). A learning-based approach to artificial sensory feedback leads to optimal integration.Nat. Neurosci. 18, 138–144. doi: 10.1038/nn.3883
Dean, T. (2005). “A computational model of the cerebral cortex,” in Proceedings of the 20th National Conference on Artificial Intelligence(Pittsburg, PA).
Enel, P., Procyk, E., Quilodran, R., and Dominey, P. F. (2016). Reservoir computing properties of neural dynamics in prefrontal cortex. PLoS Comput. Biol. 12:e1004967. doi: 10.1371/journal.pcbi.1004967
Friston, K. (2010). The free-energy principle: a unified brain theory? Nat. Rev. Neurosci. 11, 127–138. doi: 10.1038/nrn2787
George, D., and Hawkins, J. (2009). Towards a mathematical theory of cortical micro-circuits. PLoS Comput. Biol. 5:e1000532. doi: 10.1371/journal.pcbi.1000532
Hinton, G. (2007). “How to do backpropagation in a brain,” in Invited Talk at the NIPS‘2007 Deep Learning Workshop (Vancouver, BC).
Hinton, G. (2016). “Can the brain do back-propagation?,” in Invited talk at Stanford University Colloquium on Computer Systems (Stanford, CA).
Knill, D., and Pouget, A. (2004). The Bayesian brain: the role of uncertainty in neural coding and computation. Trends Neurosci. 27, 712–719. doi: 10.1016/j.tins.2004.10.007
K?rding, K., and K?nig, P. (2000). A learning rule for dynamic recruitment and decorrelation. Neural Netw. 13, 1–9. doi: 10.1016/S0893-6080(99)00088-X
Lee, T. S., and Mumford, D. (2003). Hierarchical Bayesian inference in the visual cortex. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 20, 1434–1448. doi: 10.1364/JOSAA.20.001434
Liao, Q., Leibo, J. Z., and Poggio, T. (2015). How important is weight symmetry in backpropagation? arXiv:1510.05067.
Marcus, G. (2001). The Algebraic Mind: Integrating Connectionism and Cognitive Science. Cambridge, MA: MIT Press.
O‘Reilly, R. C., Wyatte, D., and Rohrlich, J. (2014b). Learning through time in the thalamocortical loops. arXiv:1407.3432, 37.
Pehlevan, C., and Chklovskii, D. B. (2015). “Optimization theory of hebbian/anti-hebbian networks for pca and whitening,” in 53rd Annual Allerton Conference on Communication, Control, and Computing (Monticello, IL), 1458–1465.
Pinker, S. (1999). How the mind works. Ann. N.Y. Acad. Sci. 882, 119–127.
Sussillo, D., and Abbott, L. (2009). Generating coherent patterns of activity from chaotic neural networks. Neuron 63, 544–557. doi: 10.1016/j.neuron.2009.07.018.
Watter, M., Springenberg, J., Boedecker, J., and Riedmiller, M. (2015). “Embed to control: a locally linear latent dynamics model for control from raw images,” in Advances in Neural Information Processing Systems (Montreal, QC), 2728–2736.
Weston, J., Chopra, S., and Bordes, A. (2014). Memory networks. arXiv:1410.3916
【转】机器学习和神经科学:你的大脑也在进行深度学习吗?