
首页 > 代码库 > hadoop2.5.0 centOS系列 分布式的安装 部署
hadoop2.5.0 centOS系列 分布式的安装 部署
首先第一步.设置免密码SSH登陆,这是为了以后使用scp 传输文件方便,直接同步文件与文件夹,而且ssh 随时切换到相应的服务器上
先安装好ssh 如果没有安装 那么 按照下面操作 ,这是网上复制的
1.安装启动 ssh
1、检查linux是否已经按openssh
命令:# rpm -qa |grep openssh如果安装了,就可以看到安装的版本号,否则就没有安装。
2、安装# rpm -ivh openssh-3.5p1-6
# rpm -ivh openssh-server-3.5p1-6
# rpm -ivh openssh-askpass-gnome-3.5p1-6
# rpm -ivh openssh-clients-3.5p1-6
# rpm -ivh openssh-askpass-3.5p1-6
3、启动方法方法1:# service sshd start
方法2:使用绝对路径执行以下命令:
# /etc/rc.d/init.d/sshd start
或者# /etc/rc.d/sshd start
4、自动启动方法另外,如果想在系统启动时就自动运行该服务,那么需要使用setup命令,
在system service的选项中,选中sshd守护进程即可。
chkconfig sshd on
通过ntsysv 选中sshd服务
也可以通过chkconfig也设置chkconfig -- level 3 sshd on
5、配置ssh配置文件目录:/etc/ssh/sshd_config
port 22
安装好了 后,我们开始生成ssh的的公钥 与 私钥
我有四台机器 192.168.250.195 192.168.250.197 192.168.250.200 192.168.250.196 最后196作为主master
所以先ssh登陆到196机器 然后执行下面命令
ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys root@192.168.250.195 ~/.ssh/authorized_keys
下面是以前尝试 时候的截图,参考,可以直接脚本scp 加上管道直接一步完成


然后 配置 然后 以后从master 机器使用scp ssh 都不需要输入密码
然后我们修改并同步hosts属性文件
vi /etc/sysconfig/network 分别修改HOSTNAME=master HOSTNAME=slave1 ....slave2 slave3
下面 修改vi /etc/hosts 文件
192.168.250.196 master
192.168.250.195 slave1
192.168.250.197 slave2
192.168.250.200 slave3
下面 scp同步

下面我们 下载hadoop然后 在master上 修改好配置文件 然后scp同步到其他slave上即可
tar -zxf hadoop-2.5.0.tar.gz -C /usr/local/
cd /usr/local
ln -s hadoop-2.5.0 hadoop
配置好环境变量
vi /etc/profile
export HADOOP_PREFIX="/usr/local/hadoop"
export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
当然需要前提安装好java环境
然后进入hadoop目录 cd /usr/local/hadoop 修改
vi /etc/hadoop/yarn-env.sh 还有hadoop-env.sh 导入java环境
export JAVA_HOME=/usr/local/jdk8 如果默认使用 yum 安装的则不需要
然后
修改目录文件夹的core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> <description>The name of the default file system.</description> </property>
修改hdfs-site.xml 记住是///

然后下面修改yarn-site.xml
配置yarn 的resourceManger为master

然后修改mapred-site.xml
默认没有mapred-site.xml文件,copy mapred-site.xml.template 一份为 mapred-site.xml即可
然后配置 告诉hadoop 其他从节点,这样,只要主节点启动,他会自动启动其他机器上的nameNode dataNode 等等
vi /usr/local/hadoop/etc/hadoop/slaves
添加以下内容

OK 基本的全部配置已经完成
下面就是同步该文件夹 到其他各个从主机上即可 因为我们使用ssh免登陆 不需要使用密码
scp -r /usr/local/hadoop root@192.168.250.195:/usr/local/hadoop
scp -r /usr/local/hadoop root@192.168.250.197:/usr/local/hadoop
scp -r /usr/local/hadoop root@192.168.250.200:/usr/local/hadoop
ok
同步好了 后,然后我们开始在主节点 也就是当前的master 的usr/local/hadoop/sbin执行format
hdfs namenode -format
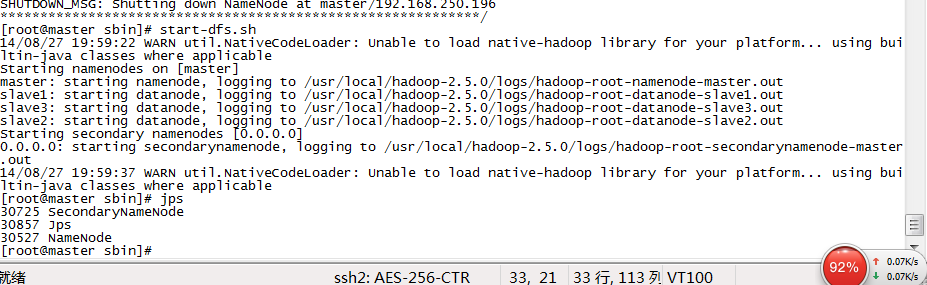
然后依次执行start-dfs.sh
在执行start-yarn.sh
也可以简单粗暴的直接start-all.sh
然后jps命令就可以查看到hadoop的运行状态了

在从节点上

也许一些用户发现ResourceManager没有启动
不过不要担心
只需要在master 下执行
yarn-daemon.sh start nodemanager 即可
ok 我们可以
使用
hadoop dfsadmin -report 查看状态
web界面 master:50070/50030
Ok到此 就完成了
可以使用测试案例 测试一下试试
另外 记住 如果是 出现错误 http://blog.csdn.net/jiedushi/article/details/7496327 可以参考一下这篇博客
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/wordcount/in /user/wordcount/out
下面是几张图



hadoop2.5.0 centOS系列 分布式的安装 部署