
首页 > 代码库 > kafka 文档1
kafka 文档1
Getting Started
入门
1.1 Introduction
简介
Kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a messaging system,
but with a unique design.
kafka 是一种分布式的,可分区,多副本 的log服务,提供了消息系统的很多功能,但是又有自己的独特的设计
What does all that mean?
意味这什么呢?
First let‘s review some basic messaging terminology:
首先,让我们回顾一些基本的通讯术语:
1. Kafka maintains feeds of messages in categories called topics.
kafka 包含topic 的功能
2.We‘ll call processes that publish messages to a Kafka topic producers.
topic消息的产生着称为生产者
3.We‘ll call processes that subscribe to topics and process the feed of published messages consumers..
topic消息的订阅着称为消费者
4.Kafka is run as a cluster comprised of one or more servers each of which is called a broker.
kafka 的运行在一个集群上面So, at a high level, producers send messages over the network to the Kafka cluster which in turn serves them up to consumers like this:
生产者发送消息和消费者消费消息,流程大概是这样的:
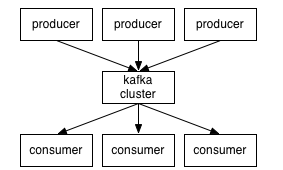
Communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. We provide a Java client for Kafka, but clients are available in many languages.
客户端的链接是tcp协议,我们提供了java客户端,但是我们支持多种语言的客户端
kafka 包含了一个topic的概念,每个procudcer 都有一个topic,每个topic 包含多个分区,每个分区内部是有序的,消息序列不改变的。
kafka 将保存所有的数据,不管数据是否已经被消费掉了,但是一定时间以后消息将被抛弃
对于消费者的数据标石 是在zookeeper中,使用一个偏移量控制,消费者也可以重置偏移量
每个分区都有一台服务器充当“领头羊”和零个或更多的服务器充当“追随者”。领导者处理所有读取和写入该分区的请求,
而被动的追随者复制的领导者。如果失败的领导者,
追随者的人会自动成为新的领导者。每个服务器充当一些分区,一个跟随他人的领导者,以便负载集群中的平衡。
Producers 可以根据数据的关键字选择分区
kafka 的消费者提供了,队列和发布-订阅两种模式
Broker Configs
broker.id 身份的唯一性
log.dirs 消息的目录
port 接受客户端请求的端口
zookeeper.connect zookeeper的地址
message.max.bytes 消息的最大长度
num.network.threads 网络请求的线程数据流
num.io.threads 持久化的线程数量
queued.max.requests 最大的请求队列
host.name:broker 对于 zookeeper的name
advertised.host.name 对于消费者,生产者 name
num.partitions topic 的分区数
num.replica.fetchers 数据复制的多少份,一个分区,跟随者多少,
消费者:
auto.commit.enable 自动提交偏移量
rebalance.max.retries 新的消费者加入,尝试重新负载的次数
生产者:
request.required.acks 确认是否需要集群,确定分区的数据已经到达副本
kafka 文档1