
首页 > 代码库 > IKAnalyzer 分词流程粗览
IKAnalyzer 分词流程粗览
没有开头语我会死啊~好的,IK是啥、怎么用相信看这篇文章的人都不需要我过多解释了,我也解释不好。下面开始正文:
IK的官方结构图:

从上至下的来看:
- 最上层是我们不需要过度关心的,它们是一些Adapter供Lucene调用。
- IK Segmentation对应的主类应该是IKSegmenter,是IK工作的核心组件。提供了分词流程的控制。
- 词元处理子单元:多个不同算法的词元分词器,实现了对不同类型词元的识别。
- 词典:主要是给CJKSegmenter提供中文词识别能力的Dictionary封装,词典和词元是如何映射的算法可以认为在这里。
其中IKSegmenter在IK中默认三个实现:
- CJKSegmenter 中日韩识别。
- CN_QuantifierSegmenter:中文量词识别。
- LetterSegmenter:英文字母识别。
IK工作流程
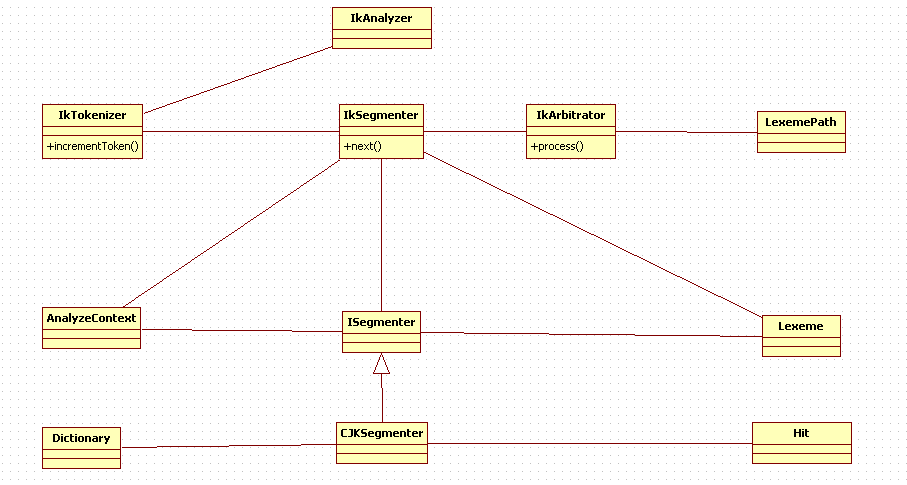
- IKAnalyzer为对外入口,IKTokenizer实现了Lucene的Tokenizer接口,作为和Lucene的结合。
- IKSegmenter是实际的分词主类。
- 在Segmenter中初始化AnalyzeContext给ISegmenter提供识别需要的上下文,Segmenter逐字遍历调用ISegmenter的实现类进行词元识别。——这里大概是最细粒度的来源。
- 在【3】中各个Segmenter是相互独立的,即它们完全可以识别出相同或者相互交叉的词元,甚至同一个Segmenter也可以识别出交叉的词元。(交叉词元是如:【中华、中华人民共和国】这样的词元)。
- 【3】提供的词元(Lexeme)是可能存在交叉和歧义的,所以IKSegmenter在返回词元之前会调用IKArbitrator来消除歧义——除量词、数词之外的useSmart就是通过这里来消除交叉词的。
IK的正向迭代最细粒度切分算法
最细粒度:
已经在3中描述。更具体的说是Segmenter会逐字识别词元,设输入”中华人民共和国“并且”中“单个字也是字典里的一个词,那么过程是这样的:”中“是词元也是前缀(因为有各种中开头的词),加入词元”中“;继续下一个词”华“,由于中是前缀,那么可以识别出”中华“,同时”中华“也是前缀因此加入”中华“词元,并把其作为前缀继续;接下来继续发现“华人”是词元,“中华人”是前缀,以此类推……
迭代:
个人对迭代的理解就应是上述逐个前缀迭代的算法:中、中华、华人、中华人民、人民、中华人民共和国(举例而已,不全)。
正向:
如上就是正向的。
IKAnalyzer 分词流程粗览
声明:以上内容来自用户投稿及互联网公开渠道收集整理发布,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任,若内容有误或涉及侵权可进行投诉: 投诉/举报 工作人员会在5个工作日内联系你,一经查实,本站将立刻删除涉嫌侵权内容。