
首页 > 代码库 > Android帧缓冲区(Frame Buffer)硬件抽象层(HAL)模块Gralloc的实现原理分析
Android帧缓冲区(Frame Buffer)硬件抽象层(HAL)模块Gralloc的实现原理分析
前面在介绍Android系统的开机画面时提到,Android设备的显示屏被抽象为一个帧缓冲区,而Android系统中的SurfaceFlinger服务就是通过向这个帧缓冲区写入内容来绘制应用程序的用户界面的。Android系统在硬件抽象层中提供了一个Gralloc模块,封装了对帧缓冲区的所有访问操作。本文将详细分析Gralloc模块的实现,为后续分析SurfaceFlinger服务的实现打下基础。
在前面Android系统的开机画面显示过程分析一文中提到,Linux内核在启动的过程中会创建一个类别和名称分别为“graphics”和“fb0”的设备,用来描述系统中的第一个帧缓冲区,即第一个显示屏,其中,数字0表示从设备号。注意,系统中至少要存在一个显示屏,因此,名称为“fb0”的设备是肯定会存在的,否则的话,就是出错了。Android系统和Linux内核本身的设计都是支持多个显示屏的,不过,在Android目前的实现中,只支持一个显示屏。
在前面Android系统的开机画面显示过程分析一文中还提到,init进程在启动的过程中,会启动另外一个进程ueventd来管理系统的设备文件。当ueventd进程启动起来之后,会通过netlink接口来Linux内核通信,以便可以获得内核中的硬件设备变化通知。而当ueventd进程发现内核中创建了一个类型和名称分别为“graphics”和“fb0”的设备的时候,就会这个设备创建一个/dev/graphics/fb0设备文件。这样,用户空间的应用程序就可以通过设备文件/dev/graphics/fb0来访问内核中的帧缓冲区,即在设备的显示屏中绘制指定的画面。注意,用户空间的应用程序一般是通过内存映射的方式来访问设备文件/dev/graphics/fb0的。
Android系统定义了硬件抽象层模块的编写规范,具体可以参考Android硬件抽象层(HAL)概要介绍和学习计划一文。本文假设读者已经熟悉Android系统的硬件抽象层编写规范,因此,我们将按照帧缓冲区的使用情景以及硬件抽象层编写规范来介绍Gralloc模块的实现。
用户空间的应用程序在使用帧缓冲区之间,首先要加载Gralloc模块,并且获得一个gralloc设备和一个fb设备。有了gralloc设备之后,用户空间中的应用程序就可以申请分配一块图形缓冲区,并且将这块图形缓冲区映射到应用程序的地址空间来,以便可以向里面写入要绘制的画面的内容。最后,用户空间中的应用程序就通过fb设备来将前面已经准备好了的图形缓冲区渲染到帧缓冲区中去,即将图形缓冲区的内容绘制到显示屏中去。相应地,当用户空间中的应用程序不再需要使用一块图形缓冲区的时候,就可以通过gralloc设备来释放它,并且将它从地址空间中解除映射。接下来,我们就按照上述使用情景来分析Gralloc模块的实现。
1. Gralloc模块的加载过程。
每一个HAL模块都有一个ID值,以这些ID值为参数来调用硬件抽象层提供的函数hw_get_module就可以将指定的模块加载到内存来,并且获得一个hw_module_t接口来打开相应的设备。
Gralloc模块的ID值定义在hardware/libhardware/include/hardware/gralloc.h文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- #define GRALLOC_HARDWARE_MODULE_ID "gralloc"
函数hw_get_module实现在hardware/libhardware/hardware.c文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- /** Base path of the hal modules */
- #define HAL_LIBRARY_PATH1 "/system/lib/hw"
- #define HAL_LIBRARY_PATH2 "/vendor/lib/hw"
- /**
- * There are a set of variant filename for modules. The form of the filename
- * is "<MODULE_ID>.variant.so" so for the led module the Dream variants
- * of base "ro.product.board", "ro.board.platform" and "ro.arch" would be:
- *
- * led.trout.so
- * led.msm7k.so
- * led.ARMV6.so
- * led.default.so
- */
- static const char *variant_keys[] = {
- "ro.hardware", /* This goes first so that it can pick up a different
- file on the emulator. */
- "ro.product.board",
- "ro.board.platform",
- "ro.arch"
- };
- static const int HAL_VARIANT_KEYS_COUNT =
- (sizeof(variant_keys)/sizeof(variant_keys[0]));
- ......
- int hw_get_module(const char *id, const struct hw_module_t **module)
- {
- int status;
- int i;
- const struct hw_module_t *hmi = NULL;
- char prop[PATH_MAX];
- char path[PATH_MAX];
- /*
- * Here we rely on the fact that calling dlopen multiple times on
- * the same .so will simply increment a refcount (and not load
- * a new copy of the library).
- * We also assume that dlopen() is thread-safe.
- */
- /* Loop through the configuration variants looking for a module */
- for (i=0 ; i<HAL_VARIANT_KEYS_COUNT+1 ; i++) {
- if (i < HAL_VARIANT_KEYS_COUNT) {
- if (property_get(variant_keys[i], prop, NULL) == 0) {
- continue;
- }
- snprintf(path, sizeof(path), "%s/%s.%s.so",
- HAL_LIBRARY_PATH1, id, prop);
- if (access(path, R_OK) == 0) break;
- snprintf(path, sizeof(path), "%s/%s.%s.so",
- HAL_LIBRARY_PATH2, id, prop);
- if (access(path, R_OK) == 0) break;
- } else {
- snprintf(path, sizeof(path), "%s/%s.default.so",
- HAL_LIBRARY_PATH1, id);
- if (access(path, R_OK) == 0) break;
- }
- }
- status = -ENOENT;
- if (i < HAL_VARIANT_KEYS_COUNT+1) {
- /* load the module, if this fails, we‘re doomed, and we should not try
- * to load a different variant. */
- status = load(id, path, module);
- }
- return status;
- }
函数hw_get_module依次在目录/system/lib/hw和/vendor/lib/hw中查找一个名称为"<MODULE_ID>.variant.so"的文件,其中,<MODULE_ID>是一个模块ID,而variant表示"ro.hardware"、"ro.product.board"、"ro.board.platform"和"ro.arch"四个系统属性值之一。例如,对于Gralloc模块来说,函数hw_get_module依次在目录/system/lib/hw和/vendor/lib/hw中检查是否存在以下四个文件:
gralloc.<ro.hardware>.so
gralloc.<ro.product.board>.so
gralloc.<ro.board.platform>.so
gralloc.<ro.arch>.so
只要其中的一个文件存在, 函数hw_get_module就会停止查找过程,并且调用另外一个函数load来将这个文件加载到内存中来。另一方面,如果在/system/lib/hw和/vendor/lib/hw中均不存这些文件,那么函数hw_get_module就会在目录/system/lib/hw中查找是否存在一个名称为gralloc.default.so的文件。如果存在的话,那么也会调用函数load将它加载到内存中来。
函数load也是实现在文件hardware/libhardware/hardware.c文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- static int load(const char *id,
- const char *path,
- const struct hw_module_t **pHmi)
- {
- int status;
- void *handle;
- struct hw_module_t *hmi;
- /*
- * load the symbols resolving undefined symbols before
- * dlopen returns. Since RTLD_GLOBAL is not or‘d in with
- * RTLD_NOW the external symbols will not be global
- */
- handle = dlopen(path, RTLD_NOW);
- if (handle == NULL) {
- char const *err_str = dlerror();
- LOGE("load: module=%s\n%s", path, err_str?err_str:"unknown");
- status = -EINVAL;
- goto done;
- }
- /* Get the address of the struct hal_module_info. */
- const char *sym = HAL_MODULE_INFO_SYM_AS_STR;
- hmi = (struct hw_module_t *)dlsym(handle, sym);
- if (hmi == NULL) {
- LOGE("load: couldn‘t find symbol %s", sym);
- status = -EINVAL;
- goto done;
- }
- /* Check that the id matches */
- if (strcmp(id, hmi->id) != 0) {
- LOGE("load: id=%s != hmi->id=%s", id, hmi->id);
- status = -EINVAL;
- goto done;
- }
- hmi->dso = handle;
- /* success */
- status = 0;
- done:
- if (status != 0) {
- hmi = NULL;
- if (handle != NULL) {
- dlclose(handle);
- handle = NULL;
- }
- } else {
- LOGV("loaded HAL id=%s path=%s hmi=%p handle=%p",
- id, path, *pHmi, handle);
- }
- *pHmi = hmi;
- return status;
- }
在Linux系统中,后缀名为"so"的文件为动态链接库文件,可能通过函数dlopen来加载到内存中。硬件抽象层模块编写规范规定每一个硬件抽象层模块都必须导出一个符号名称为HAL_MODULE_INFO_SYM_AS_STR的符号,而且这个符号必须是用来描述一个类型为hw_module_t的结构体的。
HAL_MODULE_INFO_SYM_AS_STR是一个宏,定义在文件hardware/libhardware/include/hardware/hardware.h文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- #define HAL_MODULE_INFO_SYM_AS_STR "HMI"
将Gralloc模块加载到内存中来之后,就可以调用函数dlsym来获得它所导出的符号HMI。由于这个符号指向的是一个hw_module_t结构体,因此,最后函数load就可以强制地将这个符号转换为一个hw_module_t结构体指针,并且保存在输出参数pHmi中返回给调用者。调用者获得了这个hw_module_t结构体指针之后,就可以创建一个gralloc设备或者一个fb设备。
模块Gralloc实现在目录hardware/libhardware/modules/gralloc中,它导出的符号HMI定义在文件hardware/libhardware/modules/gralloc/gralloc.cpp文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- static struct hw_module_methods_t gralloc_module_methods = {
- open: gralloc_device_open
- };
- struct private_module_t HAL_MODULE_INFO_SYM = {
- base: {
- common: {
- tag: HARDWARE_MODULE_TAG,
- version_major: 1,
- version_minor: 0,
- id: GRALLOC_HARDWARE_MODULE_ID,
- name: "Graphics Memory Allocator Module",
- author: "The Android Open Source Project",
- methods: &gralloc_module_methods
- },
- registerBuffer: gralloc_register_buffer,
- unregisterBuffer: gralloc_unregister_buffer,
- lock: gralloc_lock,
- unlock: gralloc_unlock,
- },
- framebuffer: 0,
- flags: 0,
- numBuffers: 0,
- bufferMask: 0,
- lock: PTHREAD_MUTEX_INITIALIZER,
- currentBuffer: 0,
- };
HAL_MODULE_INFO_SYM也是一个宏,它的值是与宏HAL_MODULE_INFO_SYM_AS_STR对应的,它也是定义在文件hardware/libhardware/include/hardware/hardware.h文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- #define HAL_MODULE_INFO_SYM HMI
符号HAL_MODULE_INFO_SYM的类型为private_module_t。前面提到,符号HAL_MODULE_INFO_SYM必须指向一个hw_module_t结构体,但是这里它指向的却是一个private_module_t结构体,是不是有问题呢?为了弄清楚这个问题,我们首先了解一下结构体private_module_t的定义,如图1所示:
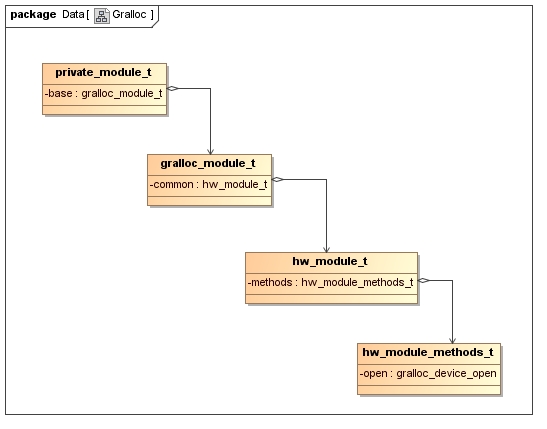
图1 private_module_t结构体定义
结构体private_module_t的第一个成员变量base指向一个gralloc_module_t结构体,而gralloc_module_t结构体的第一个成员变量common又指向了一个hw_module_t结构体,这意味着,指向一个private_module_t结构体的指针同时可以用作一个gralloc_module_t或者hw_module_t结构体提针来使用。事实上,这是使用C语言来实现的一种继承关系,等价于结构体private_module_t继承结构体gralloc_module_t,而结构体gralloc_module_t继承hw_module_t结构体。这样,我们就可以把在Gralloc模块中定义的符号HAL_MODULE_INFO_SYM看作是一个hw_module_t结构体。
hw_module_t结构体有一个重要的成员变量methods,它的类型为hw_module_methods_t,它用来描述一个HAL模块的操作方法列表。结构体hw_module_methods_t只定义有一个操作方法open,用来打开一个指定的设备。在Gralloc模块中,用来打开指定设备的函数被指定为gralloc_device_open,通过这个函数就可以打开Gralloc模块中的gralloc或者fb设备,后面我们再详细分析。
结构体gralloc_module_t定义在文件hardware/libhardware/include/hardware/gralloc.h中,它主要是定义了四个用来操作图形缓冲区的成员函数,如下所示:
[cpp] view plaincopy![]()
![]()
- typedef struct gralloc_module_t {
- ......
- int (*registerBuffer)(struct gralloc_module_t const* module,
- buffer_handle_t handle);
- int (*unregisterBuffer)(struct gralloc_module_t const* module,
- buffer_handle_t handle);
- int (*lock)(struct gralloc_module_t const* module,
- buffer_handle_t handle, int usage,
- int l, int t, int w, int h,
- void** vaddr);
- int (*unlock)(struct gralloc_module_t const* module,
- buffer_handle_t handle);
- ......
- }
成员函数registerBuffer和unregisterBuffer分别用来注册和注销一个指定的图形缓冲区,这个指定的图形缓冲区使用一个buffer_handle_t句柄来描述。所谓注册图形缓冲区,实际上就是将一块图形缓冲区映射到一个进程的地址空间去,而注销图形缓冲区就是执行相反的操作。
成员函数lock和unlock分别用来锁定和解锁一个指定的图形缓冲区,这个指定的图形缓冲区同样是使用一个buffer_handle_t句柄来描述。在访问一块图形缓冲区的时候,例如,向一块图形缓冲写入内容的时候,需要将该图形缓冲区锁定,用来避免访问冲突。在锁定一块图形缓冲区的时候,可以指定要锁定的图形绘冲区的位置以及大小,这是通过参数l、t、w和h来指定的,其中,参数l和t指定的是要访问的图形缓冲区的左上角位置,而参数w和h指定的是要访问的图形缓冲区的宽度和长度。锁定之后,就可以获得由参数参数l、t、w和h所圈定的一块缓冲区的起始地址,保存在输出参数vaddr中。另一方面,在访问完成一块图形缓冲区之后,需要解除这块图形缓冲区的锁定。
在Gralloc模块中,符号HAL_MODULE_INFO_SYM指向的gralloc结构体的成员函数registerBuffer、unregisterBuffer、lock和unlock分别被指定为函数gralloc_register_buffer、gralloc_unregister_buffer、gralloc_lock和gralloc_unlock,后面我们再详细分析它们的实现。
结构体private_module_t定义在文件hardware/libhardware/modules/gralloc/gralloc_priv.h中,它主要是用来描述帧缓冲区的属性,如下所示:
[cpp] view plaincopy![]()
![]()
- struct private_module_t {
- gralloc_module_t base;
- private_handle_t* framebuffer;
- uint32_t flags;
- uint32_t numBuffers;
- uint32_t bufferMask;
- pthread_mutex_t lock;
- buffer_handle_t currentBuffer;
- int pmem_master;
- void* pmem_master_base;
- struct fb_var_screeninfo info;
- struct fb_fix_screeninfo finfo;
- float xdpi;
- float ydpi;
- float fps;
- };
成员变量framebuffer的类型为private_handle_t,它是一个指向系统帧缓冲区的句柄,后面我们再分析结构体private_handle_t的定义。
成员变量flags用来标志系统帧缓冲区是否支持双缓冲。如果支持的话,那么它的PAGE_FLIP位就等于1,否则的话,就等于0。
成员变量numBuffers表示系统帧缓冲区包含有多少个图形缓冲区。一个帧缓冲区包含有多少个图形缓冲区是与它的可视分辨率以及虚拟分辨率的大小有关的。例如,如果一个帧缓冲区的可视分辨率为800 x 600,而虚拟分辨率为1600 x 600,那么这个帧缓冲区就可以包含有两个图形缓冲区。
成员变量bufferMask用来记录系统帧缓冲区中的图形缓冲区的使用情况。例如,假设系统帧缓冲区有两个图形缓冲区,这时候成员变量bufferMask就有四种取值,分别是二进制的00、01、10和11,其中,00分别表示两个图缓冲区都是空闲的,01表示第1个图形缓冲区已经分配出去,而第2个图形缓冲区是空闲的,10表示第1个图形缓冲区是空闲的,而第2个图形缓冲区已经分配出去,11表示两个图缓冲区都已经分配出去。
成员变量lock是一个互斥锁,用来保护结构体private_module_t的并行访问。
成员变量currentBuffer的类型为buffer_handle_t,用来描述当前正在被渲染的图形缓冲区,后面我们再分析它的定义。
成员变量pmem_master和pmem_master_base目前没有使用。
成员变量info和finfo的类型分别为fb_var_screeninfo和fb_fix_screeninfo,它们用来保存设备显示屏的属性信息,其中,成员变量info保存的属性信息是可以动态设置的,而成员变量finfo保存的属性信息是只读的。这两个成员变量的值可以通过IO控制命令FBIOGET_VSCREENINFO和FBIOGET_FSCREENINFO来从帧缓冲区驱动模块中获得。
成员变量xdpi和ydpi分别用来描述设备显示屏在宽度和高度上的密度,即每英寸有多少个像素点。
成员变量fps用来描述显示屏的刷新频率,它的单位的fps,即每秒帧数。
接下来, 我们再分析结构体buffer_handle_t和private_handle_t的定义。
结构体buffer_handle_t定义在文件hardware/libhardware/include/hardware/gralloc.h文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- typedef const native_handle* buffer_handle_t;
它是一个类型为native_handle_t的指针,而结构体native_handle_t用来描述一个本地句柄值,它定义在系统运行时层的文件system/core/include/cutils/native_handle.h文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- typedef struct
- {
- int version; /* sizeof(native_handle_t) */
- int numFds; /* number of file-descriptors at &data[0] */
- int numInts; /* number of ints at &data[numFds] */
- int data[0]; /* numFds + numInts ints */
- } native_handle_t;
成员变量version的大小被设置为结构体native_handle_t的大小,用来标识结构体native_handle_t的版本。
成员变量numFds和numInts表示结构体native_handle_t所包含的文件描述符以及整数值的个数,这些文件描述符和整数保存在成员变量data所指向的一块缓冲区中。
我们一般不直接使用native_handle_t结构体来描述一个本地句柄值,而是通过它的子类来描述一个具体的本地句柄值。接下来我们就通过结构体private_handle_t的定义来说明native_handle_t结构体的用法。
结构体private_handle_t用来描述一块图形缓冲区,这块图形缓冲区可能是在帧缓冲区中分配的,也可能是在内存中分配的,视具体情况而定,它定义在文件hardware/libhardware/modules/gralloc/gralloc_priv.h文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- #ifdef __cplusplus
- struct private_handle_t : public native_handle {
- #else
- struct private_handle_t {
- struct native_handle nativeHandle;
- #endif
- enum {
- PRIV_FLAGS_FRAMEBUFFER = 0x00000001
- };
- // file-descriptors
- int fd;
- // ints
- int magic;
- int flags;
- int size;
- int offset;
- // FIXME: the attributes below should be out-of-line
- int base;
- int pid;
- #ifdef __cplusplus
- static const int sNumInts = 6;
- static const int sNumFds = 1;
- static const int sMagic = 0x3141592;
- private_handle_t(int fd, int size, int flags) :
- fd(fd), magic(sMagic), flags(flags), size(size), offset(0),
- base(0), pid(getpid())
- {
- version = sizeof(native_handle);
- numInts = sNumInts;
- numFds = sNumFds;
- }
- ~private_handle_t() {
- magic = 0;
- }
- static int validate(const native_handle* h) {
- const private_handle_t* hnd = (const private_handle_t*)h;
- if (!h || h->version != sizeof(native_handle) ||
- h->numInts != sNumInts || h->numFds != sNumFds ||
- hnd->magic != sMagic)
- {
- LOGE("invalid gralloc handle (at %p)", h);
- return -EINVAL;
- }
- return 0;
- }
- #endif
- };
为了方便描述,我们假设我们是在C++环境中编译文件gralloc_priv.h,即编译环境定义有宏__cplusplus。这样,结构体private_handle_t就是从结构体native_handle_t继承下来的,它包含有1个文件描述符以及6个整数,以及三个静态成员变量。
成员变量fd指向一个文件描述符,这个文件描述符要么指向帧缓冲区设备,要么指向一块匿名共享内存,取决于它的宿主结构体private_handle_t描述的一个图形缓冲区是在帧缓冲区分配的,还是在内存中分配的。
成员变量magic指向一个魔数,它的值由静态成员变量sMagic来指定,用来标识一个private_handle_t结构体。
成员变量flags用来描述一个图形缓冲区的标志,它的值要么等于0,要么等于PRIV_FLAGS_FRAMEBUFFER。当一个图形缓冲区的标志值等于PRIV_FLAGS_FRAMEBUFFER的时候,就表示它是在帧缓冲区中分配的。
成员变量size用来描述一个图形缓冲区的大小。
成员变量offset用来描述一个图形缓冲区的偏移地址。例如,当一个图形缓冲区是在一块内存中分块的时候,假设这块内存的地址为start,那么这个图形缓冲区的起始地址就为start + offset。
成员变量base用来描述一个图形缓冲区的实际地址,它是通过成员变量offset来计算得到的。例如,上面计算得到的start + offset的值就保存在成员变量base中。
成员变量pid用来描述一个图形缓冲区的创建者的PID。例如,如果一个图形缓冲区是在ID值为1000的进程中创建的,那么用来描述这个图形缓冲区的private_handle_t结构体的成员变量pid的值就等于1000。
结构体private_handle_t的静态成员变量sMagic前面已经描述过了,另外两个静态成员变量sNumInts和sNumFds的值分别等于1和6,表示结构体private_handle_t包含有1个文件描述符和6个整数,它们是用来初始化结构体private_handle_t的父类native_handle_t的成员变量numInts和numFds的,如结构体private_handle_t的构造函数所示。从这里就可以看出,结构体private_handle_t的父类native_handle_t的成员变量data所指向的缓冲区就是由结构体private_handle_t的成员变量fds、magic、flags、size、offset、base和pid所占用的连续内存块来组成的,一共包含有7个整数。
结构体private_handle_t还定义了一个静态成员函数validate,用来验证一个native_handle_t指针是否指向了一个private_handle_t结构体。
至此,Gralloc模块的加载过程以及相关的数据结构体就介绍到这里,接下来我们分别分析定义在Gralloc模块中的gralloc和fb设备的打开过程。
2. gralloc设备的打开过程
在Gralloc模块中,gralloc设备的ID值定义为GRALLOC_HARDWARE_GPU0。GRALLOC_HARDWARE_GPU0是一个宏,定义在文件hardware/libhardware/include/hardware/gralloc.h中, 如下所示:
[cpp] view plaincopy![]()
![]()
- #define GRALLOC_HARDWARE_GPU0 "gpu0"
gralloc设备使用结构体alloc_device_t 来描述。结构体alloc_device_t有两个成员函数alloc和free,分别用来分配和释放图形缓冲区。
结构体alloc_device_t 也是定义在文件hardware/libhardware/include/hardware/gralloc.h中, 如下所示:
[cpp] view plaincopy![]()
![]()
- typedef struct alloc_device_t {
- struct hw_device_t common;
- int (*alloc)(struct alloc_device_t* dev,
- int w, int h, int format, int usage,
- buffer_handle_t* handle, int* stride);
- int (*free)(struct alloc_device_t* dev,
- buffer_handle_t handle);
- } alloc_device_t;
Gralloc模块在在文件hardware/libhardware/include/hardware/gralloc.h中定义了一个帮助函数gralloc_open,用来打开gralloc设备,如下所示:
[cpp] view plaincopy![]()
![]()
- static inline int gralloc_open(const struct hw_module_t* module,
- struct alloc_device_t** device) {
- return module->methods->open(module,
- GRALLOC_HARDWARE_GPU0, (struct hw_device_t**)device);
- }
参数module指向的是一个用来描述Gralloc模块的hw_module_t结构体,它的成员变量methods所指向的一个hw_module_methods_t结构体的成员函数open指向了Gralloc模块中的函数gralloc_device_open。
函数gralloc_device_open定义在文件hardware/libhardware/modules/gralloc/gralloc.cpp文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- struct gralloc_context_t {
- alloc_device_t device;
- /* our private data here */
- };
- ......
- int gralloc_device_open(const hw_module_t* module, const char* name,
- hw_device_t** device)
- {
- int status = -EINVAL;
- if (!strcmp(name, GRALLOC_HARDWARE_GPU0)) {
- gralloc_context_t *dev;
- dev = (gralloc_context_t*)malloc(sizeof(*dev));
- /* initialize our state here */
- memset(dev, 0, sizeof(*dev));
- /* initialize the procs */
- dev->device.common.tag = HARDWARE_DEVICE_TAG;
- dev->device.common.version = 0;
- dev->device.common.module = const_cast<hw_module_t*>(module);
- dev->device.common.close = gralloc_close;
- dev->device.alloc = gralloc_alloc;
- dev->device.free = gralloc_free;
- *device = &dev->device.common;
- status = 0;
- }
- ......
- return status;
- }
这个函数主要是用来创建一个gralloc_context_t结构体,并且对它的成员变量device进行初始化。结构体gralloc_context_t的成员变量device的类型为gralloc_device_t,它用来描述一个gralloc设备。前面提到,gralloc设备是用来分配和释放图形缓冲区的,这是通过调用它的成员函数alloc和free来实现的。从这里可以看出,函数gralloc_device_open所打开的gralloc设备的成员函数alloc和free分别被设置为Gralloc模块中的函数gralloc_alloc和gralloc_free,后面我们再详细分析它们的实现。
至此,gralloc设备的打开过程就分析完成了,接下来我们继续分析fb设备的打开过程。
3. fb设备的打开过程
在Gralloc模块中,fb设备的ID值定义为GRALLOC_HARDWARE_FB0。GRALLOC_HARDWARE_FB0是一个宏,定义在文件hardware/libhardware/include/hardware/gralloc.h中, 如下所示:
[cpp] view plaincopy![]()
![]()
- #define GRALLOC_HARDWARE_FB0 "fb0"
fb设备使用结构体framebuffer_device_t 来描述。结构体framebuffer_device_t是用来描述系统帧缓冲区的信息,它定义在文件hardware/libhardware/include/hardware/gralloc.h中, 如下所示:
[cpp] view plaincopy![]()
![]()
- typedef struct framebuffer_device_t {
- struct hw_device_t common;
- /* flags describing some attributes of the framebuffer */
- const uint32_t flags;
- /* dimensions of the framebuffer in pixels */
- const uint32_t width;
- const uint32_t height;
- /* frambuffer stride in pixels */
- const int stride;
- /* framebuffer pixel format */
- const int format;
- /* resolution of the framebuffer‘s display panel in pixel per inch*/
- const float xdpi;
- const float ydpi;
- /* framebuffer‘s display panel refresh rate in frames per second */
- const float fps;
- /* min swap interval supported by this framebuffer */
- const int minSwapInterval;
- /* max swap interval supported by this framebuffer */
- const int maxSwapInterval;
- int reserved[8];
- int (*setSwapInterval)(struct framebuffer_device_t* window,
- int interval);
- int (*setUpdateRect)(struct framebuffer_device_t* window,
- int left, int top, int width, int height);
- int (*post)(struct framebuffer_device_t* dev, buffer_handle_t buffer);
- int (*compositionComplete)(struct framebuffer_device_t* dev);
- void* reserved_proc[8];
- } framebuffer_device_t;
成员变量flags用来记录系统帧缓冲区的标志,目前没有使用这成员变量,它的值被设置为0。
成员变量width和height分别用来描述设备显示屏的宽度和高度,它们是以像素为单位的。
成员变量stride用来描述设备显示屏的一行有多少个像素点。
成员变量format用来描述系统帧缓冲区的像素格式,支持的像素格式主要有HAL_PIXEL_FORMAT_RGBX_8888和HAL_PIXEL_FORMAT_RGB_565两种。HAL_PIXEL_FORMAT_RGBX_8888表示一个像素使用32位来描述,R、G和B分别占8位,另外8位未使用。HAL_PIXEL_FORMAT_RGB_565表示一个像素使用16位来描述,R、G和B分别占5、6和5位。
成员变量xdpi和ydpi分别用来描述设备显示屏在宽度和高度上的密度,即每英寸有多少个像素点。
成员变量fps用来描述设备显示屏的刷新频率,它的单位是帧每秒。
成员变量minSwapInterval和maxSwapInterval用来描述帧缓冲区交换前后两个图形缓冲区的最小和最大时间间隔。
成员变量reserved是保留给将来使用的。
成员函数setSwapInterval用来设置帧缓冲区交换前后两个图形缓冲区的最小和最大时间间隔。
成员函数setUpdateRect用来设置帧缓冲区的更新区域。
成员函数post用来将图形缓冲区buffer的内容渲染到帧缓冲区中去,即显示在设备的显示屏中去。
成员函数compositionComplete用来通知fb设备device,图形缓冲区的组合工作已经完成,目前没有使用这个成员函数。
成员变量reserved是一个函数指针数组,它们是保留给将来使用的。
在结构体framebuffer_device_t的一系列成员函数中,post是最重要的一个成员函数,用户空间的应用程序通过调用这个成员函数就可以在设备的显示屏中渲染指定的画面,后面我们将详细这个函数的实现。
Gralloc模块在在文件hardware/libhardware/include/hardware/gralloc.h中定义了一个帮助函数framebuffer_open,用来打开fb设备,如下所示:
[cpp] view plaincopy![]()
![]()
- static inline int framebuffer_open(const struct hw_module_t* module,
- struct framebuffer_device_t** device) {
- return module->methods->open(module,
- GRALLOC_HARDWARE_FB0, (struct hw_device_t**)device);
- }
参数module指向的是一个用来描述Gralloc模块的hw_module_t结构体,前面提到,它的成员变量methods所指向的一个hw_module_methods_t结构体的成员函数open指向了Gralloc模块中的函数gralloc_device_open,这个函数打开fb设备的代码段如下所示:
[cpp] view plaincopy![]()
![]()
- int gralloc_device_open(const hw_module_t* module, const char* name,
- hw_device_t** device)
- {
- int status = -EINVAL;
- if (!strcmp(name, GRALLOC_HARDWARE_GPU0)) {
- ......
- } else {
- status = fb_device_open(module, name, device);
- }
- return status;
- }
参数name的值等于GRALLOC_HARDWARE_FB0,因此,函数gralloc_device_open接下来会调用另外一个函数fb_device_open来执行打开fb设备的操作。
函数fb_device_open定义在文件hardware/libhardware/modules/gralloc/framebuffer.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- struct fb_context_t {
- framebuffer_device_t device;
- };
- ......
- int fb_device_open(hw_module_t const* module, const char* name,
- hw_device_t** device)
- {
- int status = -EINVAL;
- if (!strcmp(name, GRALLOC_HARDWARE_FB0)) {
- alloc_device_t* gralloc_device;
- status = gralloc_open(module, &gralloc_device);
- if (status < 0)
- return status;
- /* initialize our state here */
- fb_context_t *dev = (fb_context_t*)malloc(sizeof(*dev));
- memset(dev, 0, sizeof(*dev));
- /* initialize the procs */
- dev->device.common.tag = HARDWARE_DEVICE_TAG;
- dev->device.common.version = 0;
- dev->device.common.module = const_cast<hw_module_t*>(module);
- dev->device.common.close = fb_close;
- dev->device.setSwapInterval = fb_setSwapInterval;
- dev->device.post = fb_post;
- dev->device.setUpdateRect = 0;
- private_module_t* m = (private_module_t*)module;
- status = mapFrameBuffer(m);
- if (status >= 0) {
- int stride = m->finfo.line_length / (m->info.bits_per_pixel >> 3);
- int format = (m->info.bits_per_pixel == 32)
- ? HAL_PIXEL_FORMAT_RGBX_8888
- : HAL_PIXEL_FORMAT_RGB_565;
- #ifdef NO_32BPP
- format = HAL_PIXEL_FORMAT_RGB_565;
- #endif
- const_cast<uint32_t&>(dev->device.flags) = 0;
- const_cast<uint32_t&>(dev->device.width) = m->info.xres;
- const_cast<uint32_t&>(dev->device.height) = m->info.yres;
- const_cast<int&>(dev->device.stride) = stride;
- const_cast<int&>(dev->device.format) = format;
- const_cast<float&>(dev->device.xdpi) = m->xdpi;
- const_cast<float&>(dev->device.ydpi) = m->ydpi;
- const_cast<float&>(dev->device.fps) = m->fps;
- const_cast<int&>(dev->device.minSwapInterval) = 1;
- const_cast<int&>(dev->device.maxSwapInterval) = 1;
- *device = &dev->device.common;
- }
- }
- return status;
- }
这个函数主要是用来创建一个fb_context_t结构体,并且对它的成员变量device进行初始化。结构体fb_context_t的成员变量device的类型为framebuffer_device_t,前面提到,它是用来描述fb设备的。fb设备主要是用来渲染图形缓冲区的,这是通过调用它的成员函数post来实现的。从这里可以看出,函数fb_device_open所打开的fb设备的成员函数post被设置为Gralloc模块中的函数fb_post,后面我们再详细分析它的实现。
函数fb_device_open在打开fb设备的过程中,会调用另外一个函数mapFrameBuffer来获得系统帧缓冲区的信息,并且将这些信息保存在参数module所描述的一个private_module_t结构体的各个成员变量中。有了系统帧缓冲区的信息之后,函数fb_device_open接下来就可以对前面所打开的一个fb设备的各个成员变量进行初始化。这些成员变量的含义可以参考前面对结构体framebuffer_device_t的介绍。接下来我们只简单介绍一下结构体framebuffer_device_t的成员变量stride和format的初始化过程。
变量m的成员变量finfo的类型为fb_fix_screeninfo,它是在函数mapFrameBuffer中被始化的。fb_fix_screeninfo是在内核中定义的一个结构体,用来描述设备显示屏的固定属性信息,其中,它的成员变量line_length用来描述显示屏一行像素总共所占用的字节数。
变量m的另外一个成员变量info的类型为fb_var_screeninfo,它也是在函数mapFrameBuffer中被始化的。fb_var_screeninfo也是内核中定义的一个结构体,用来描述可以动态设置的显示屏属性信息,其中,它的成员变量bits_per_pixel用来描述显示屏每一个像素所占用的位数。
这样,我们将m->info.bits_per_pixel的值向右移3位,就可以得到显示屏每一个像素所占用的字节数。用显示屏每一个像素所占用的字节数去除显示屏一行像素总共所占用的字节数m->finfo.line_length,就可以得到显示屏一行有多少个像素点。这个值最终就可以保存在前面所打开的fb设备的成员变量stride中。
当显示屏每一个像素所占用的位数等于32的时候,那么前面所打开的fb设备的像素格式format就会被设置为HAL_PIXEL_FORMAT_RGBX_8888,否则的话,就会被设置为HAL_PIXEL_FORMAT_RGB_565。另一方面,如果在编译的时候定义了NO_32BPP宏,即不要使用32位来描述一个像素,那么函数fb_device_open就会强制将前面所打开的fb设备的像素格式format设置为HAL_PIXEL_FORMAT_RGB_565。
函数mapFrameBuffer除了用来获得系统帧缓冲区的信息之外,还会将系统帧缓冲区映射到当前进程的地址空间来。在Android系统中,Gralloc模块中的fb设备是由SurfaceFlinger服务来负责打开和管理的,而SurfaceFlinger服是运行System进程中的,因此,系统帧缓冲区实际上是映射到System进程的地址空间中的。
函数mapFrameBuffer实现在文件hardware/libhardware/modules/gralloc/framebuffer.cpp,如下所示:
[cpp] view plaincopy![]()
![]()
- static int mapFrameBuffer(struct private_module_t* module)
- {
- pthread_mutex_lock(&module->lock);
- int err = mapFrameBufferLocked(module);
- pthread_mutex_unlock(&module->lock);
- return err;
- }
这个函数调用了同一个文件中的另外一个函数mapFrameBufferLocked来初始化参数module以及将系统帧缓冲区映射到当前进程的地址空间来。
函数mapFrameBufferLocked的实现比较长,我们分段来阅读:
[cpp] view plaincopy![]()
![]()
- int mapFrameBufferLocked(struct private_module_t* module)
- {
- // already initialized...
- if (module->framebuffer) {
- return 0;
- }
- char const * const device_template[] = {
- "/dev/graphics/fb%u",
- "/dev/fb%u",
- 0 };
- int fd = -1;
- int i=0;
- char name[64];
- while ((fd==-1) && device_template[i]) {
- snprintf(name, 64, device_template[i], 0);
- fd = open(name, O_RDWR, 0);
- i++;
- }
- if (fd < 0)
- return -errno;
这段代码在首先在系统中检查是否存在设备文件/dev/graphics/fb0或者/dev/fb0。如果存在的话,那么就调用函数open来打开它,并且将得到的文件描述符保存在变量fd中。这样,接下来函数mapFrameBufferLocked就可以通过文件描述符fd来与内核中的帧缓冲区驱动程序交互。
继续往下看函数mapFrameBufferLocked:
[cpp] view plaincopy![]()
![]()
- struct fb_fix_screeninfo finfo;
- if (ioctl(fd, FBIOGET_FSCREENINFO, &finfo) == -1)
- return -errno;
- struct fb_var_screeninfo info;
- if (ioctl(fd, FBIOGET_VSCREENINFO, &info) == -1)
- return -errno;
这几行代码分别通过IO控制命令FBIOGET_FSCREENINFO和FBIOGET_VSCREENINFO来获得系统帧缓冲区的信息,分别保存在fb_fix_screeninfo结构体finfo和fb_var_screeninfo结构体info中。
再往下看函数mapFrameBufferLocked:
[cpp] view plaincopy![]()
![]()
- info.reserved[0] = 0;
- info.reserved[1] = 0;
- info.reserved[2] = 0;
- info.xoffset = 0;
- info.yoffset = 0;
- info.activate = FB_ACTIVATE_NOW;
- #if defined(NO_32BPP)
- /*
- * Explicitly request 5/6/5
- */
- info.bits_per_pixel = 16;
- info.red.offset = 11;
- info.red.length = 5;
- info.green.offset = 5;
- info.green.length = 6;
- info.blue.offset = 0;
- info.blue.length = 5;
- info.transp.offset = 0;
- info.transp.length = 0;
- #endif
- /*
- * Request NUM_BUFFERS screens (at lest 2 for page flipping)
- */
- info.yres_virtual = info.yres * NUM_BUFFERS;
- uint32_t flags = PAGE_FLIP;
- if (ioctl(fd, FBIOPUT_VSCREENINFO, &info) == -1) {
- info.yres_virtual = info.yres;
- flags &= ~PAGE_FLIP;
- LOGW("FBIOPUT_VSCREENINFO failed, page flipping not supported");
- }
- if (info.yres_virtual < info.yres * 2) {
- // we need at least 2 for page-flipping
- info.yres_virtual = info.yres;
- flags &= ~PAGE_FLIP;
- LOGW("page flipping not supported (yres_virtual=%d, requested=%d)",
- info.yres_virtual, info.yres*2);
- }
这段代码主要是用来设置设备显示屏的虚拟分辨率。在前面Android系统的开机画面显示过程分析一文提到,结构体fb_var_screeninfo的成员变量xres和yres用来描述显示屏的可视分辨率,而成员变量xres_virtual和yres_virtual用来描述显示屏的虚拟分辨率。这里保持可视分辨率以及虚拟分辨率的宽度值不变,而将虚拟分辨率的高度值设置为可视分辨率的高度值的NUM_BUFFERS倍。NUM_BUFFERS是一个宏,它的值被定义为2。这样,我们就可以将系统帧缓冲区划分为两个图形缓冲区来使用,即可以通过硬件来实现双缓冲技术。
在结构体fb_var_screeninfo中,与显示屏的可视分辨率和虚拟分辨率相关的另外两个成员变量是xoffset和yoffset,它们用来告诉帧缓冲区当前要渲染的图形缓冲区是哪一个,它们的使用方法可以参考前面Android系统的开机画面显示过程分析一文。
这段代码在设置设备显示屏的虚拟分辨率之前,还会检查是否定义了宏NO_32BPP。如果定义了的话,那么就说明系统显式地要求将帧缓冲区的像素格式设置为HAL_PIXEL_FORMAT_RGB_565。在这种情况下,这段代码就会通过fb_var_screeninfo结构体info的成员变量bits_per_pixel、red、green、blue和transp来通知帧缓冲区驱动程序使用HAL_PIXEL_FORMAT_RGB_565像素格式来渲染显示屏。
这段代码最终是通过IO控制命令FBIOPUT_VSCREENINFO来设置设备显示屏的虚拟分辨率以及像素格式的。如果设置失败,即调用函数ioctl的返回值等于-1,那么很可能是因为系统帧缓冲区在硬件上不支持双缓冲,因此,接下来的代码就会重新将显示屏的虚拟分辨率的高度值设置为可视分辨率的高度值,并且将变量flags的PAGE_FLIP位置为0。
另一方面,如果调用函数ioctl成功,但是最终获得的显示屏的虚拟分辨率的高度值小于可视分辨率的高度值的2倍,那么也说明系统帧缓冲区在硬件上不支持双缓冲。在这种情况下,接下来的代码也会重新将显示屏的虚拟分辨率的高度值设置为可视分辨率的高度值,并且将变量flags的PAGE_FLIP位置为0。
再继续往下看函数mapFrameBufferLocked:
[cpp] view plaincopy![]()
![]()
- if (ioctl(fd, FBIOGET_VSCREENINFO, &info) == -1)
- return -errno;
- uint64_t refreshQuotient =
- (
- uint64_t( info.upper_margin + info.lower_margin + info.yres )
- * ( info.left_margin + info.right_margin + info.xres )
- * info.pixclock
- );
- /* Beware, info.pixclock might be 0 under emulation, so avoid a
- * division-by-0 here (SIGFPE on ARM) */
- int refreshRate = refreshQuotient > 0 ? (int)(1000000000000000LLU / refreshQuotient) : 0;
- if (refreshRate == 0) {
- // bleagh, bad info from the driver
- refreshRate = 60*1000; // 60 Hz
- }
这段代码再次通过IO控制命令FBIOGET_VSCREENINFO来获得系统帧缓冲区的可变属性信息,并且保存在fb_var_screeninfo结构体info中,接下来再计算设备显示屏的刷新频率。
显示屏的刷新频率与显示屏的扫描时序相关。显示屏的扫描时序可以参考Linux内核源代码目录下的Documentation/fb/framebuffer.txt文件。我们结合图2来简单说明上述代码是如何计算显示屏的刷新频率的。
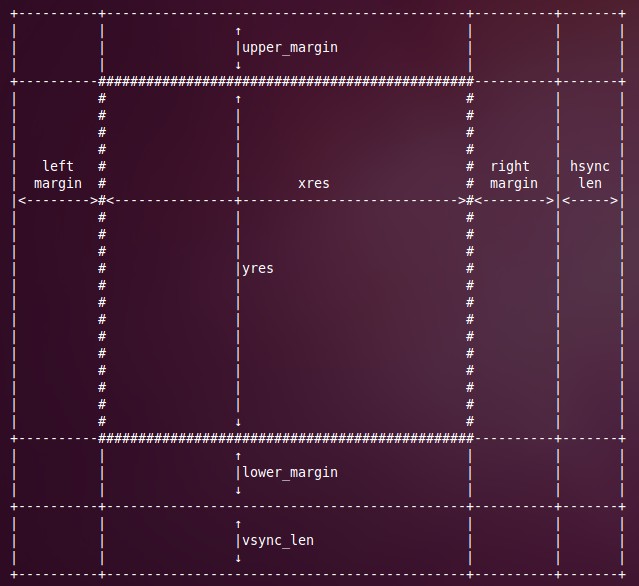
图 2 显示屏扫描时序示意图
中间由xres和yres组成的区域即为显示屏的图形绘制区,在绘制区的上、下、左和右分别有四个边距upper_margin、lower_margin、left_margin和right_margin。此外,在显示屏的最右边以及最下边还有一个水平同步区域hsync_len和一个垂直同步区域vsync_len。电子枪按照从左到右、从上到下的顺序来显示屏中打点,从而可以将要渲染的图形显示在屏幕中。前面所提到的区域信息分别保存在fb_var_screnninfo结构体info的成员变量xres、yres、upper_margin、lower_margin、left_margin、right_margin、hsync_len和vsync_len。
电子枪每在xres和yres所组成的区域中打一个点所花费的时间记录在fb_var_screnninfo结构体info的成员变量pixclock,单位为pico seconds,即10E-12秒。
电子枪从左到右扫描完成一行之后,都会处理关闭状态,并且会重新折回到左边去。由于电子枪在从右到左折回的过程中不需要打点,因此,这个过程会比从左到右扫描屏幕的过程要快,这个折回的时间大概就等于在xres和yres所组成的区域扫描(left_margin+right_margin)个点的时间。这样,我们就可以认为每渲染一行需要的时间为(xres + left_margin + right_margin)* pixclock。
同样,电子枪从上到下扫描完成显示屏之后,需要从右下角折回到左上角去,折回的时间大概等于在xres和yres所组成的区域中扫描(upper_margin + lower_margin)行所需要的时间。这样,我们就可以认为每渲染一屏图形所需要的时间等于在xres和yres所组成的区域中扫描(yres + upper_margin + lower_margin)行所需要的时间。由于在xres和yres所组成的区域中扫描一行所需要的时间为(xres + left_margin + right_margin)* pixclock,因此,每渲染一屏图形所需要的总时间就等于(yres + upper_margin + lower_margin)* (xres + left_margin + right_margin)* pixclock。
每渲染一屏图形需要的总时间经过计算之后,就保存在变量refreshQuotient中。注意,变量refreshQuotient所描述的时间的单位为1E-12秒。这样,将变量refreshQuotient的值倒过来,就可以得到设备显示屏的刷新频率。将这个频率值乘以10E15次方之后,就得到一个单位为10E-3 HZ的刷新频率,保存在变量refreshRate中。
当Android系统在模拟器运行的时候,保存在fb_var_screnninfo结构体info的成员变量pixclock中的值可能等于0。在这种情况下,前面计算得到的变量refreshRate的值就会等于0。在这种情况下,接下来的代码会将变量refreshRate的值设置为60 * 1000 * 10E-3 HZ,即将显示屏的刷新频率设置为60HZ。
再往下看函数mapFrameBufferLocked:
[cpp] view plaincopy![]()
![]()
- if (int(info.width) <= 0 || int(info.height) <= 0) {
- // the driver doesn‘t return that information
- // default to 160 dpi
- info.width = ((info.xres * 25.4f)/160.0f + 0.5f);
- info.height = ((info.yres * 25.4f)/160.0f + 0.5f);
- }
- float xdpi = (info.xres * 25.4f) / info.width;
- float ydpi = (info.yres * 25.4f) / info.height;
- float fps = refreshRate / 1000.0f;
这段代码首先计算显示屏的密度,即每英寸有多少个像素点,分别宽度和高度两个维度,分别保存在变量xdpi和ydpi中。注意,fb_var_screeninfo结构体info的成员变量width和height用来描述显示屏的宽度和高度,它们是以毫米(mm)为单位的。
这段代码接着再将前面计算得到的显示屏刷新频率的单位由10E-3 HZ转换为HZ,即帧每秒,并且保存在变量fps中。
再往下看函数mapFrameBufferLocked:
[cpp] view plaincopy![]()
![]()
- if (ioctl(fd, FBIOGET_FSCREENINFO, &finfo) == -1)
- return -errno;
- if (finfo.smem_len <= 0)
- return -errno;
- module->flags = flags;
- module->info = info;
- module->finfo = finfo;
- module->xdpi = xdpi;
- module->ydpi = ydpi;
- module->fps = fps;
这段代码再次通过IO控制命令FBIOGET_FSCREENINFO来获得系统帧缓冲区的固定信息,并且保存在fb_fix_screeninfo结构体finfo中,接下来再使用fb_fix_screeninfo结构体finfo以及前面得到的系统帧缓冲区的其它信息来初始化参数module所描述的一个private_module_t结构体。
最后,函数mapFrameBufferLocked就将系统帧缓冲区映射到当前进程的地址空间来:
[cpp] view plaincopy![]()
![]()
- /*
- * map the framebuffer
- */
- int err;
- size_t fbSize = roundUpToPageSize(finfo.line_length * info.yres_virtual);
- module->framebuffer = new private_handle_t(dup(fd), fbSize, 0);
- module->numBuffers = info.yres_virtual / info.yres;
- module->bufferMask = 0;
- void* vaddr = mmap(0, fbSize, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
- if (vaddr == MAP_FAILED) {
- LOGE("Error mapping the framebuffer (%s)", strerror(errno));
- return -errno;
- }
- module->framebuffer->base = intptr_t(vaddr);
- memset(vaddr, 0, fbSize);
- return 0;
- }
表达式finfo.line_length * info.yres_virtual计算的是整个系统帧缓冲区的大小,它的值等于显示屏行数(虚拟分辨率的高度值,info.yres_virtual)乘以每一行所占用的字节数(finfo.line_length)。函数roundUpToPageSize用来将整个系统帧缓冲区的大小对齐到页面边界。对齐后的大小保存在变量fbSize中。
表达式finfo.yres_virtual / info.yres计算的是整个系统帧缓冲区可以划分为多少个图形缓冲区来使用,这个数值保存在参数module所描述的一个private_module_t结构体的成员变量nmBuffers中。参数module所描述的一个private_module_t结构体的另外一个成员变量bufferMask的值接着被设置为0,表示系统帧缓冲区中的所有图形缓冲区都是处于空闲状态,即它们可以分配出去给应用程序使用。
系统帧缓冲区是通过调用函数mmap来映射到当前进程的地址空间来的。映射后得到的地址空间使用一个private_handle_t结构体来描述,这个结构体的成员变量base保存的即为系统帧缓冲区在当前进程的地址空间中的起始地址。这样,Gralloc模块以后就可以从这块地址空间中分配图形缓冲区给当前进程使用。
至此,fb设备的打开过程就分析完成了。在打开fb设备的过程中,Gralloc模块还完成了对系统帧缓冲区的初始化工作。接下来我们继续分析Gralloc模块是如何分配图形缓冲区给用户空间的应用程序使用的。
4. 分配图形缓冲区
前面提到,用户空间的应用程序用到的图形缓冲区是由Gralloc模块中的函数gralloc_alloc来分配的,这个函数实现在文件hardware/libhardware/modules/gralloc/gralloc.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- static int gralloc_alloc(alloc_device_t* dev,
- int w, int h, int format, int usage,
- buffer_handle_t* pHandle, int* pStride)
- {
- if (!pHandle || !pStride)
- return -EINVAL;
- size_t size, stride;
- int align = 4;
- int bpp = 0;
- switch (format) {
- case HAL_PIXEL_FORMAT_RGBA_8888:
- case HAL_PIXEL_FORMAT_RGBX_8888:
- case HAL_PIXEL_FORMAT_BGRA_8888:
- bpp = 4;
- break;
- case HAL_PIXEL_FORMAT_RGB_888:
- bpp = 3;
- break;
- case HAL_PIXEL_FORMAT_RGB_565:
- case HAL_PIXEL_FORMAT_RGBA_5551:
- case HAL_PIXEL_FORMAT_RGBA_4444:
- bpp = 2;
- break;
- default:
- return -EINVAL;
- }
- size_t bpr = (w*bpp + (align-1)) & ~(align-1);
- size = bpr * h;
- stride = bpr / bpp;
- int err;
- if (usage & GRALLOC_USAGE_HW_FB) {
- err = gralloc_alloc_framebuffer(dev, size, usage, pHandle);
- } else {
- err = gralloc_alloc_buffer(dev, size, usage, pHandle);
- }
- if (err < 0) {
- return err;
- }
- *pStride = stride;
- return 0;
- }
参数format用来描述要分配的图形缓冲区的颜色格式。当format值等于HAL_PIXEL_FORMAT_RGBA_8888、HAL_PIXEL_FORMAT_RGBX_8888或者HAL_PIXEL_FORMAT_BGRA_8888的时候,一个像素需要使用32位来表示,即4个字节。当format值等于HAL_PIXEL_FORMAT_RGB_888的时候,一个像素需要使用24位来描述,即3个字节。当format值等于HAL_PIXEL_FORMAT_RGB_565、HAL_PIXEL_FORMAT_RGBA_5551或者HAL_PIXEL_FORMAT_RGBA_4444的时候,一个像需要使用16位来描述,即2个字节。最终一个像素需要使用的字节数保存在变量bpp中。
参数w表示要分配的图形缓冲区所保存的图像的宽度,将它乘以bpp,就可以得到保存一行像素所需要使用的字节数。我们需要将这个字节数对齐到4个字节边界,最后得到一行像素所需要的字节数就保存在变量bpr中。
参数h表示要分配的图形缓冲区所保存的图像的高度,将它乘以bpr,就可以得到保存整个图像所需要使用的字节数。
将变量bpr的值除以变量bpp的值,就得到要分配的图形缓冲区一行包含有多少个像素点,这个结果需要保存在输出参数pStride中,以便可以返回给调用者。
参数usage用来描述要分配的图形缓冲区的用途。如果是用来在系统帧缓冲区中渲染的,即参数usage的GRALLOC_USAGE_HW_FB位等于1,那么就必须要系统帧缓冲区中分配,否则的话,就在内存中分配。注意,在内存中分配的图形缓冲区,最终是需要拷贝到系统帧缓冲区去的,以便可以将它所描述的图形渲染出来。
函数gralloc_alloc_framebuffer用来在系统帧缓冲区中分配图形缓冲区,而函数gralloc_alloc_buffer用来在内存在分配图形缓冲区,接下来我们就分别分析这两个函数的实现。
函数gralloc_alloc_framebuffer实现在文件hardware/libhardware/modules/gralloc/gralloc.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- static int gralloc_alloc_framebuffer(alloc_device_t* dev,
- size_t size, int usage, buffer_handle_t* pHandle)
- {
- private_module_t* m = reinterpret_cast<private_module_t*>(
- dev->common.module);
- pthread_mutex_lock(&m->lock);
- int err = gralloc_alloc_framebuffer_locked(dev, size, usage, pHandle);
- pthread_mutex_unlock(&m->lock);
- return err;
- }
这个函数调用了另外一个函数gralloc_alloc_framebuffer_locked来分配图形缓冲区。
函数gralloc_alloc_framebuffer_locked也是实现在文件hardware/libhardware/modules/gralloc/gralloc.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- static int gralloc_alloc_framebuffer_locked(alloc_device_t* dev,
- size_t size, int usage, buffer_handle_t* pHandle)
- {
- private_module_t* m = reinterpret_cast<private_module_t*>(
- dev->common.module);
- // allocate the framebuffer
- if (m->framebuffer == NULL) {
- // initialize the framebuffer, the framebuffer is mapped once
- // and forever.
- int err = mapFrameBufferLocked(m);
- if (err < 0) {
- return err;
- }
- }
- const uint32_t bufferMask = m->bufferMask;
- const uint32_t numBuffers = m->numBuffers;
- const size_t bufferSize = m->finfo.line_length * m->info.yres;
- if (numBuffers == 1) {
- // If we have only one buffer, we never use page-flipping. Instead,
- // we return a regular buffer which will be memcpy‘ed to the main
- // screen when post is called.
- int newUsage = (usage & ~GRALLOC_USAGE_HW_FB) | GRALLOC_USAGE_HW_2D;
- return gralloc_alloc_buffer(dev, bufferSize, newUsage, pHandle);
- }
- if (bufferMask >= ((1LU<<numBuffers)-1)) {
- // We ran out of buffers.
- return -ENOMEM;
- }
- // create a "fake" handles for it
- intptr_t vaddr = intptr_t(m->framebuffer->base);
- private_handle_t* hnd = new private_handle_t(dup(m->framebuffer->fd), size,
- private_handle_t::PRIV_FLAGS_FRAMEBUFFER);
- // find a free slot
- for (uint32_t i=0 ; i<numBuffers ; i++) {
- if ((bufferMask & (1LU<<i)) == 0) {
- m->bufferMask |= (1LU<<i);
- break;
- }
- vaddr += bufferSize;
- }
- hnd->base = vaddr;
- hnd->offset = vaddr - intptr_t(m->framebuffer->base);
- *pHandle = hnd;
- return 0;
- }
在系统帧缓冲区分配图形缓冲区之前,首先要对系统帧缓冲区进行过初始化,即这里的变量m所指向的一个private_module_t结构体的成员变量framebuffer的值不能等于NULL。如果等于NULL的话,那么就必须要调用另外一个函数mapFrameBufferLocked来初始化系统帧缓冲区。初始化系统帧缓冲区的过程可以参考前面第3部分的内容。
变量bufferMask用来描述系统帧缓冲区的使用情况,而变量numBuffers用来描述系统帧缓冲区可以划分为多少个图形缓冲区来使用,另外一个变量bufferSize用来描述设备显示屏一屏内容所占用的内存的大小。
如果系统帧缓冲区只有一个图形缓冲区大小,即变量numBuffers的值等于1,那么这个图形缓冲区就始终用作系统主图形缓冲区来使用。在这种情况下,我们就不能够在系统帧缓冲区中分配图形缓冲区来给用户空间的应用程序使用,因此,这时候就会转向内存中来分配图形缓冲区,即调用函数gralloc_alloc_buffer来分配图形缓冲区。注意,这时候分配的图形缓冲区的大小为一屏内容的大小,即bufferSize。
如果bufferMask的值大于等于((1LU<<numBuffers)-1)的值,那么就说明系统帧缓冲区中的图形缓冲区全部都分配出去了,这时候分配图形缓冲区就失败了。例如,假设图形缓冲区的个数为2,那么((1LU<<numBuffers)-1)的值就等于3,即二制制0x11。如果这时候bufferMask的值也等于0x11,那么就表示第一个和第二个图形缓冲区都已经分配出去了。因此,这时候就不能再在系统帧缓冲区中分配图形缓冲区。
假设此时系统帧缓冲区中尚有空闲的图形缓冲区的,接下来函数就会创建一个private_handle_t结构体hnd来描述这个即将要分配出去的图形缓冲区。注意,这个图形缓冲区的标志值等于PRIV_FLAGS_FRAMEBUFFER,即表示这是一块在系统帧缓冲区中分配的图形缓冲区。
接下来的for循环从低位到高位检查变量bufferMask的值,并且找到第一个值等于0的位,这样就可以知道在系统帧缓冲区中,第几个图形缓冲区的是空闲的。注意,变量vadrr的值开始的时候指向系统帧缓冲区的基地址,在下面的for循环中,每循环一次它的值都会增加bufferSize。从这里就可以看出,每次从系统帧缓冲区中分配出去的图形缓冲区的大小都是刚好等于显示屏一屏内容大小的。
最后分配出去的图形缓冲区的开始地址就保存在前面所创建的private_handle_t结构体hnd的成员变量base中,这样,用户空间的应用程序就可以直接将要渲染的图形内容拷贝到这个地址上去,这就相当于是直接将图形渲染到系统帧缓冲区中去。
在将private_handle_t结构体hnd返回给调用者之前,还需要设置它的成员变量offset,以便可以知道它所描述的图形缓冲区的起始地址相对于系统帧缓冲区的基地址的偏移量。
至此,在系统帧缓冲区中分配图形缓冲区的过程就分析完成了,接下来我们再分析在内存在分析图形缓冲区的过程,即分析函数gralloc_alloc_buffer的实现。
函数gralloc_alloc_buffer也是实现在文件hardware/libhardware/modules/gralloc/gralloc.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- static int gralloc_alloc_buffer(alloc_device_t* dev,
- size_t size, int usage, buffer_handle_t* pHandle)
- {
- int err = 0;
- int fd = -1;
- size = roundUpToPageSize(size);
- fd = ashmem_create_region("gralloc-buffer", size);
- if (fd < 0) {
- LOGE("couldn‘t create ashmem (%s)", strerror(-errno));
- err = -errno;
- }
- if (err == 0) {
- private_handle_t* hnd = new private_handle_t(fd, size, 0);
- gralloc_module_t* module = reinterpret_cast<gralloc_module_t*>(
- dev->common.module);
- err = mapBuffer(module, hnd);
- if (err == 0) {
- *pHandle = hnd;
- }
- }
- LOGE_IF(err, "gralloc failed err=%s", strerror(-err));
- return err;
- }
这个函数的实现很简单,它首先调用函数ashmem_create_region来创建一块匿名共享内存,接着再在这块匿名共享内存上分配一个图形缓冲区。注意,这个图形缓冲区也是使用一个private_handle_t结构体来描述的,不过这个图形缓冲区的标志值等于0,以区别于在系统帧缓冲区中分配的图形缓冲区。匿名共享内存的相关知识,可以参考前面Android系统匿名共享内存Ashmem(Anonymous Shared Memory)简要介绍和学习计划一文,以及Android系统匿名共享内存(Anonymous Shared Memory)C++调用接口分析这篇文章。
从匿名共享内存中分配的图形缓冲区还需要映射到进程的地址空间来,然后才可以使用,这是通过调用函数mapBuffer来实现的。
函数mapBuffer实现在文件hardware/libhardware/modules/gralloc/mapper.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- int mapBuffer(gralloc_module_t const* module,
- private_handle_t* hnd)
- {
- void* vaddr;
- return gralloc_map(module, hnd, &vaddr);
- }
它通过调用另外一个函数gralloc_map来将参数hnd所描述的一个图形缓冲区映射到当前进程的地址空间来。后面在分析图形缓冲区的注册过程时,我们再分析函数gralloc_map的实现。
注意,在Android系统中,在系统帧缓冲区中分配的图形缓冲区是在SurfaceFlinger服务中使用的,而在内存中分配的图形缓冲区既可以在SurfaceFlinger服务中使用,也可以在其它的应用程序中使用。当其它的应用程序需要使用图形缓冲区的时候,它们就会请求SurfaceFlinger服务为它们分配,因此,对于其它的应用程序来说,它们只需要将SurfaceFlinger服务返回来的图形缓冲区映射到自己的进程地址空间来使用就可以了,这就是后面我们所要分析的图形缓冲区的注册过程。
至此,图形缓冲区的分配过程就分析完成了,接下来我们继续分析图形缓冲区的释放过程。
5. 图形缓冲区的释放过程
前面提到,用户空间的应用程序用到的图形缓冲区是由Gralloc模块中的函数gralloc_free来释放的,这个函数实现在文件hardware/libhardware/modules/gralloc/gralloc.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- static int gralloc_free(alloc_device_t* dev,
- buffer_handle_t handle)
- {
- if (private_handle_t::validate(handle) < 0)
- return -EINVAL;
- private_handle_t const* hnd = reinterpret_cast<private_handle_t const*>(handle);
- if (hnd->flags & private_handle_t::PRIV_FLAGS_FRAMEBUFFER) {
- // free this buffer
- private_module_t* m = reinterpret_cast<private_module_t*>(
- dev->common.module);
- const size_t bufferSize = m->finfo.line_length * m->info.yres;
- int index = (hnd->base - m->framebuffer->base) / bufferSize;
- m->bufferMask &= ~(1<<index);
- } else {
- gralloc_module_t* module = reinterpret_cast<gralloc_module_t*>(
- dev->common.module);
- terminateBuffer(module, const_cast<private_handle_t*>(hnd));
- }
- close(hnd->fd);
- delete hnd;
- return 0;
- }
要释放的图形缓冲区使用参数handle来描述。前面提到,从Gralloc模块中分配的图形缓冲区是使用private_handle_t结构体来描述的,因此,这里的参数handle应该指向一个private_handle_t结构体,这是通过调用private_handle_t类的静态成员函数validate来验证的。private_handle_t类的静态成员函数validate的实现可以参考前面第1部分的内容。
要释放的图形缓冲区有可能是在系统帧缓冲区分配的,也有可能是在内存中分配的,这可以通过检查它的标志值flags的PRIV_FLAGS_FRAMEBUFFER位是否等于1来确认。
如果要释放的图形缓冲区是在系统帧缓冲区中分配的,那么首先要知道这个图形缓冲区是系统帧缓冲区的第index个位置,接着再将变量m所描述的一个private_module_t结构体的成员变量bufferMask的第index位重置为0即可。我们只需要将要释放的图形缓冲区的开始地址减去系统帧缓冲区的基地址,再除以一个图形缓冲区的大小,就可以知道要释放的图形缓冲区是系统帧缓冲区的第几个位置。这个过程刚好是在系统帧缓冲区中分配图形缓冲区的逆操作。
如果要释放的图形缓冲区是内存中分配的,那么只需要调用另外一个函数terminateBuffer来解除要释放的图形缓冲区在当前进程的地址空间中的映射。
最后,这个函数还会将用来描述要释放的图形缓冲区的private_handle_t结构体所占用的内存释放掉,并且将要要释放的图形缓冲区所在的系统帧缓冲区或者匿名共享内存的文件描述符关闭掉。
函数terminateBuffer实现在文件hardware/libhardware/modules/gralloc/mapper.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- int terminateBuffer(gralloc_module_t const* module,
- private_handle_t* hnd)
- {
- if (hnd->base) {
- // this buffer was mapped, unmap it now
- gralloc_unmap(module, hnd);
- }
- return 0;
- }
它通过调用另外一个函数gralloc_unmap来解除参数hnd所描述的一个图形缓冲区在当前进程的地址空间中的映射。后面在分析图形缓冲区的注销过程时,我们再详细分析函数gralloc_unmap的实现。
至此,图形缓冲区的释放过程就分析完成了,接下来我们继续分析图形缓冲区的注册过程。
6. 图形缓冲区的注册过程
前面提到,在Android系统中,所有的图形缓冲区都是由SurfaceFlinger服务分配的,而当一个图形缓冲区被分配的时候,它会同时被映射到请求分配的进程的地址空间去,即分配的过程同时也包含了注册的过程。但是对用户空间的其它的应用程序来说,它们所需要的图形缓冲区是在由SurfaceFlinger服务分配的,因此,当它们得到SurfaceFlinger服务分配的图形缓冲区之后,还需要将这块图形缓冲区映射到自己的地址空间来,以便可以使用这块图形缓冲区。这个映射的过程即为我们接下来要分析的图形缓冲区注册过程。
前面还提到,注册图形缓冲区的操作是由Gralloc模块中的函数gralloc_register_buffer来实现的,这个函数实现在文件hardware/libhardware/modules/gralloc/mapper.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- int gralloc_register_buffer(gralloc_module_t const* module,
- buffer_handle_t handle)
- {
- if (private_handle_t::validate(handle) < 0)
- return -EINVAL;
- // if this handle was created in this process, then we keep it as is.
- int err = 0;
- private_handle_t* hnd = (private_handle_t*)handle;
- if (hnd->pid != getpid()) {
- void *vaddr;
- err = gralloc_map(module, handle, &vaddr);
- }
- return err;
- }
这个函数首先验证参数handle指向的一块图形缓冲区的确是由Gralloc模块分配的,方法是调用private_handle_t类的静态成员函数validate来验证,即如果参数handle指向的是一个private_handle_t结构体,那么它所指向的一块图形缓冲区就是由Gralloc模块分配的。
通过了上面的检查之后,函数gralloc_register_buffer还需要检查当前进程是否就是请求Gralloc模块分配图形缓冲区hnd的进程。如果是的话,那么当前进程在请求Gralloc模块分配图形缓冲区hnd的时候,就已经将图形缓冲区hnd映射进自己的地址空间来了,因此,这时候就不需要重复在当前进程中注册这个图形缓冲区。
真正执行注册图形缓冲区的操作是由函数gralloc_map来实现的,这个函数也是实现文件hardware/libhardware/modules/gralloc/mapper.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- static int gralloc_map(gralloc_module_t const* module,
- buffer_handle_t handle,
- void** vaddr)
- {
- private_handle_t* hnd = (private_handle_t*)handle;
- if (!(hnd->flags & private_handle_t::PRIV_FLAGS_FRAMEBUFFER)) {
- size_t size = hnd->size;
- void* mappedAddress = mmap(0, size,
- PROT_READ|PROT_WRITE, MAP_SHARED, hnd->fd, 0);
- if (mappedAddress == MAP_FAILED) {
- LOGE("Could not mmap %s", strerror(errno));
- return -errno;
- }
- hnd->base = intptr_t(mappedAddress) + hnd->offset;
- //LOGD("gralloc_map() succeeded fd=%d, off=%d, size=%d, vaddr=%p",
- // hnd->fd, hnd->offset, hnd->size, mappedAddress);
- }
- *vaddr = (void*)hnd->base;
- return 0;
- }
由于在系统帧缓冲区中分配的图形缓冲区只在SurfaceFlinger服务中使用,而SurfaceFlinger服务在初始化系统帧缓冲区的时候,已经将系统帧缓冲区映射到自己所在的进程中来了,因此,函数gralloc_map如果发现要注册的图形缓冲区是在系统帧缓冲区分配的时候,那么就不需要再执行映射图形缓冲区的操作了。
如果要注册的图形缓冲区是在内存中分配的,即它的标志值flags的PRIV_FLAGS_FRAMEBUFFER位等于1,那么接下来就需要将它映射到当前进程的地址空间来了。由于要注册的图形缓冲区是在文件描述符hnd->fd所描述的一块匿名共享内存中分配的,因此,我们只需要将文件描述符hnd->fd所描述的一块匿名共享内存映射到当前进程的地址空间来,就可以将参数hnd所描述的一个图形缓冲区映射到当前进程的地址空间来。
由于映射文件描述符hnd->fd得到的是一整块匿名共享内存在当前进程地址空间的基地址,而要注册的图形缓冲区可能只占据这块匿名共享内存的某一小部分,因此,我们还需要将要注册的图形缓冲区的在被映射的匿名共享内存中的偏移量hnd->offset加上被映射的匿名共享内存的基地址hnd->base,才可以得到要注册的图形缓冲区在当前进程中的访问地址,这个地址最终又被写入到hnd->base中去。
注册图形缓冲区的过程就是这么简单,接下来我们再分析图形缓冲区的注销过程。
7. 图形缓冲区的注销过程
图形缓冲区使用完成之后,就需要从当前进程中注销。前面提到,注销图形缓冲区是由Gralloc模块中的函数gralloc_unregister_buffer来实现的,这个函数实现在文件hardware/libhardware/modules/gralloc/mapper.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- int gralloc_unregister_buffer(gralloc_module_t const* module,
- buffer_handle_t handle)
- {
- if (private_handle_t::validate(handle) < 0)
- return -EINVAL;
- // never unmap buffers that were created in this process
- private_handle_t* hnd = (private_handle_t*)handle;
- if (hnd->pid != getpid()) {
- if (hnd->base) {
- gralloc_unmap(module, handle);
- }
- }
- return 0;
- }
这个函数同样是首先调用private_handle_t类的静态成员函数validate来验证参数handle指向的一块图形缓冲区的确是由Gralloc模块分配的,接着再将将参数handle指向的一块图形缓冲区转换为一个private_handle_t结构体hnd来访问。
一块图形缓冲区只有被注册过,即被Gralloc模块中的函数gralloc_register_buffer注册过,才需要注销,而由函数gralloc_register_buffer注册的图形缓冲区都不是由当前进程分配的,因此,当前进程在注销一个图形缓冲区的时候,会检查要注销的图形缓冲区是否是由自己分配的。如果是由自己分配的话,那么它什么也不做就返回了。
假设要注销的图形缓冲区hnd不是由当前进程分配的,那么接下来就会调用另外一个函数galloc_unmap来注销图形缓冲区hnd。
函数galloc_unmap也是实现在文件hardware/libhardware/modules/gralloc/mapper.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- static int gralloc_unmap(gralloc_module_t const* module,
- buffer_handle_t handle)
- {
- private_handle_t* hnd = (private_handle_t*)handle;
- if (!(hnd->flags & private_handle_t::PRIV_FLAGS_FRAMEBUFFER)) {
- void* base = (void*)hnd->base;
- size_t size = hnd->size;
- //LOGD("unmapping from %p, size=%d", base, size);
- if (munmap(base, size) < 0) {
- LOGE("Could not unmap %s", strerror(errno));
- }
- }
- hnd->base = 0;
- return 0;
- }
这个函数的实现与前面所分析的函数gralloc_map的实现是类似的,只不过它执行的是相反的操作,即将解除一个指定的图形缓冲区在当前进程的地址空间中的映射,从而完成对这个图形缓冲区的注销工作。
这样,图形缓冲区的注销过程就分析完成了,接下来我们再继续分析一个图形缓冲区是如何被渲染到系统帧缓冲区去的,即它的内容是如何绘制在设备显示屏中的。
8. 图形缓冲区的渲染过程
用户空间的应用程序将画面内容写入到图形缓冲区中去之后,还需要将图形缓冲区渲染到系统帧缓冲区中去,这样才可以把画面绘制到设备显示屏中去。前面提到,渲染图形缓冲区是由Gralloc模块中的函数fb_post来实现的,这个函数实现在文件hardware/libhardware/modules/gralloc/framebuffer.cpp中,如下所示:
[cpp] view plaincopy![]()
![]()
- static int fb_post(struct framebuffer_device_t* dev, buffer_handle_t buffer)
- {
- if (private_handle_t::validate(buffer) < 0)
- return -EINVAL;
- fb_context_t* ctx = (fb_context_t*)dev;
- private_handle_t const* hnd = reinterpret_cast<private_handle_t const*>(buffer);
- private_module_t* m = reinterpret_cast<private_module_t*>(
- dev->common.module);
- if (hnd->flags & private_handle_t::PRIV_FLAGS_FRAMEBUFFER) {
- const size_t offset = hnd->base - m->framebuffer->base;
- m->info.activate = FB_ACTIVATE_VBL;
- m->info.yoffset = offset / m->finfo.line_length;
- if (ioctl(m->framebuffer->fd, FBIOPUT_VSCREENINFO, &m->info) == -1) {
- LOGE("FBIOPUT_VSCREENINFO failed");
- m->base.unlock(&m->base, buffer);
- return -errno;
- }
- m->currentBuffer = buffer;
- } else {
- // If we can‘t do the page_flip, just copy the buffer to the front
- // FIXME: use copybit HAL instead of memcpy
- void* fb_vaddr;
- void* buffer_vaddr;
- m->base.lock(&m->base, m->framebuffer,
- GRALLOC_USAGE_SW_WRITE_RARELY,
- 0, 0, m->info.xres, m->info.yres,
- &fb_vaddr);
- m->base.lock(&m->base, buffer,
- GRALLOC_USAGE_SW_READ_RARELY,
- 0, 0, m->info.xres, m->info.yres,
- &buffer_vaddr);
- memcpy(fb_vaddr, buffer_vaddr, m->finfo.line_length * m->info.yres);
- m->base.unlock(&m->base, buffer);
- m->base.unlock(&m->base, m->framebuffer);
- }
- return 0;
- }
参数buffer用来描述要渲染的图形缓冲区,它指向的必须要是一个private_handle_t结构体,这是通过调用private_handle_t类的静态成员函数validate来验证的。验证通过之后,就可以将参数buffer所描述的一个buffer_handle_t结构体转换成一个private_handle_t结构体hnd。
参数dev用来描述在Gralloc模块中的一个fb设备。从前面第3部分的内容可以知道,在打开fb设备的时候,Gralloc模块返回给调用者的实际上是一个fb_context_t结构体,因此,这里就可以将参数dev所描述的一个framebuffer_device_t结构体转换成一个fb_context_t结构体ctx。
参数dev的成员变量common指向了一个hw_device_t结构体,这个结构体的成员变量module指向了一个Gralloc模块。从前面第1部分的内容可以知道,一个Gralloc模块是使用一个private_module_t结构体来描述的,因此,我们可以将dev->common.moudle转换成一个private_module_t结构体m。
由于private_handle_t结构体hnd所描述的图形缓冲区可能是在系统帧缓冲区分配的,也有可能是内存中分配的,因此,我们分两种情况来讨论图形缓冲区渲染过程。
当private_handle_t结构体hnd所描述的图形缓冲区是在系统帧缓冲区中分配的时候,即这个图形缓冲区的标志值flags的PRIV_FLAGS_FRAMEBUFFER位等于1的时候,我们是不需要将图形缓冲区的内容拷贝到系统帧缓冲区去的,因为我们将内容写入到图形缓冲区的时候,已经相当于是将内容写入到了系统帧缓冲区中去了。虽然在这种情况下,我们不需要将图形缓冲区的内容拷贝到系统帧缓冲区去,但是我们需要告诉系统帧缓冲区设备将要渲染的图形缓冲区作为系统当前的输出图形缓冲区,这样才可以将要渲染的图形缓冲区的内容绘制到设备显示屏来。例如,假设系统帧缓冲区有2个图形缓冲区,当前是以第1个图形缓冲区作为输出图形缓冲区的,这时候如果我们需要渲染第2个图形缓冲区,那么就必须告诉系统帧绘冲区设备,将第2个图形缓冲区作为输出图形缓冲区。
设置系统帧缓冲区的当前输出图形缓冲区是通过IO控制命令FBIOPUT_VSCREENINFO来进行的。IO控制命令FBIOPUT_VSCREENINFO需要一个fb_var_screeninfo结构体作为参数。从前面第3部分的内容可以知道,private_module_t结构体m的成员变量info正好保存在我们所需要的这个fb_var_screeninfo结构体。有了个m->info这个fb_var_screeninfo结构体之后,我们只需要设置好它的成员变量yoffset的值(不用设置成员变量xoffset的值是因为所有的图形缓冲区的宽度是相等的),就可以将要渲染的图形缓冲区设置为系统帧缓冲区的当前输出图形缓冲区。fb_var_screeninfo结构体的成员变量yoffset保存的是当前输出图形缓冲区在整个系统帧缓冲区的纵向偏移量,即Y偏移量。我们只需要将要渲染的图形缓冲区的开始地址hnd->base的值减去系统帧缓冲区的基地址m->framebuffer->base的值,再除以图形缓冲区一行所占据的字节数m->finfo.line_length,就可以得到所需要的Y偏移量。
在执行IO控制命令FBIOPUT_VSCREENINFO之前,还会将作为参数的fb_var_screeninfo结构体的成员变量activate的值设置FB_ACTIVATE_VBL,表示要等到下一个垂直同步事件出现时,再将当前要渲染的图形缓冲区的内容绘制出来。这样做的目的是避免出现屏幕闪烁,即避免前后两个图形缓冲区的内容各有一部分同时出现屏幕中。
成功地执行完成IO控制命令FBIOPUT_VSCREENINFO之后,函数还会将当前被渲染的图形缓冲区保存在private_module_t结构体m的成员变量currentBuffer中,以便可以记录当前被渲染的图形缓冲区是哪一个。
当private_handle_t结构体hnd所描述的图形缓冲区是在内存中分配的时候,即这个图形缓冲区的标志值flags的PRIV_FLAGS_FRAMEBUFFER位等于0的时候,我们就需要将它的内容拷贝到系统帧缓冲区中去了。这个拷贝的工作是通过调用函数memcpy来完成的。在拷贝之前,我们需要三个参数。第一个参数是要渲染的图形缓冲区的起址地址,这个地址保存在参数buffer所指向的一个private_handle_t结构体中。第二个参数是要系统帧缓冲区的基地址,这个地址保存在private_module_t结构体m的成员变量framebuffer所指向的一个private_handle_t结构体中。第三个参数是要拷贝的内容的大小,这个大小就刚好是一个屏幕像素所占据的内存的大小。屏幕高度由m->info.yres来描述,而一行屏幕像素所占用的字节数由m->finfo.line_length来描述,将这两者相乘,就可以得到一个屏幕像素所占据的内存的大小。
在将一块内存缓冲区的内容拷贝到系统帧缓冲区中去之前,需要对这两块缓冲区进行锁定,以保证在拷贝的过程中,这两块缓冲区的内容不会被修改。这个锁定的工作是由Gralloc模块中的函数gralloc_lock来实现的。从前面第1部分的内容可以知道,Gralloc模块中的函数gralloc_lock的地址正好就保存在private_module_t结构体m的成员变量base所描述的一个gralloc_module_t结构体的成员函数lock中。
在调用函数gralloc_lock来锁定一块缓冲区之后,还可以通过最后一个输出参数来获得被锁定的缓冲区的开始地址,因此,通过调用函数gralloc_lock来锁定要渲染的图形缓冲区以及系统帧缓冲区,就可以得到前面所需要的第一个和第二个参数。
将要渲染的图形缓冲区的内容拷贝到系统帧缓冲区之后,就可以解除前面对它们的锁定了,这个解锁的工作是由Gralloc模块中的函数gralloc_unlock来实现的。从前面第1部分的内容可以知道,Gralloc模块中的函数gralloc_unlock的地址正好就保存在private_module_t结构体m的成员变量base所描述的一个gralloc_module_t结构体的成员函数unlock中。
这样,一个图形缓冲区的渲染过程就分析完成了。
为了完整性起见,最后我们再简要分析函数gralloc_lock和gralloc_unlock的实现,以便可以了解一个图形缓冲区的锁定和解锁操作是如何实现的。
函数gralloc_lock实现在文件hardware/libhardware/modules/gralloc/mapper.cpp文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- int gralloc_lock(gralloc_module_t const* module,
- buffer_handle_t handle, int usage,
- int l, int t, int w, int h,
- void** vaddr)
- {
- // this is called when a buffer is being locked for software
- // access. in thin implementation we have nothing to do since
- // not synchronization with the h/w is needed.
- // typically this is used to wait for the h/w to finish with
- // this buffer if relevant. the data cache may need to be
- // flushed or invalidated depending on the usage bits and the
- // hardware.
- if (private_handle_t::validate(handle) < 0)
- return -EINVAL;
- private_handle_t* hnd = (private_handle_t*)handle;
- *vaddr = (void*)hnd->base;
- return 0;
- }
从这里可以看出,函数gralloc_lock其实并没有执行锁定参数handle所描述的一个缓冲区的操作,它只简单地将要锁定的缓冲区的开始地址返回给调用者。
理论上来说,函数gralloc_lock应该检查参数handle所描述的一个缓冲区是否正在被其进程或者线程使用。如果是的话,那么函数gralloc_lock就必须要等待,直到要锁定的缓冲区被其它进程或者线程使用结束为止,以便接下来可以独占它。由于函数gralloc_lock实际上并没有作这些操作,因此,就必须要由调用者来保证要锁定的缓冲区当前是没有被其它进程或者线程使用的。
函数gralloc_unlock也是实现在文件hardware/libhardware/modules/gralloc/mapper.cpp文件中,如下所示:
[cpp] view plaincopy![]()
![]()
- int gralloc_unlock(gralloc_module_t const* module,
- buffer_handle_t handle)
- {
- // we‘re done with a software buffer. nothing to do in this
- // implementation. typically this is used to flush the data cache.
- if (private_handle_t::validate(handle) < 0)
- return -EINVAL;
- return 0;
- }
函数gralloc_unlock执行的操作本来是刚好与函数gralloc_lock相反的,但是由于函数gralloc_lock并没有真实地锁定参数handle所描述的一个缓冲区的,因此,函数gralloc_unlock是不需要执行实际的解锁工作的。
至此,我们就分析完成Android帧缓冲区硬件抽象层模块Gralloc的实现原理了。从分析的过程可以知道,为了在屏幕中绘制一个指定的画面,我们需要:
1. 分配一个匹配屏幕大小的图形缓冲区
2. 将分配好的图形缓冲区注册(映射)到当前进程的地址空间来
3. 将要绘制的画面的内容写入到已经注册好的图形缓冲区中去,并且渲染(拷贝)到系统帧缓冲区中去
为了实现以上三个操作,我们还需要:
1. 加载Gralloc模块
2. 打开Gralloc模块中的gralloc设备和fb设备
其中,gralloc设备负责分配图形缓冲区,Gralloc模块负责注册图形缓冲区,而fb设备负责渲染图形缓冲区。
理解了Gralloc模块的实现原理之后,就可以为后续分析SurfaceFlinger服务的实现打下坚实的基础了。
摘自:http://blog.csdn.net/luoshengyang/article/details/7747932
Android帧缓冲区(Frame Buffer)硬件抽象层(HAL)模块Gralloc的实现原理分析