
首页 > 代码库 > 【Spark亚太研究院系列丛书】Spark实战高手之路-第3章Spark架构设计与编程模型第3节②
【Spark亚太研究院系列丛书】Spark实战高手之路-第3章Spark架构设计与编程模型第3节②
三,深入RDD
RDD本身是一个抽象类,具有很多具体的实现子类:

RDD都会基于Partition进行计算:

默认的Partitioner如下所示:
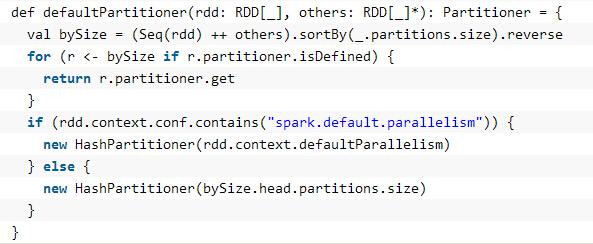
其中HashPartitioner的文档说明如下:

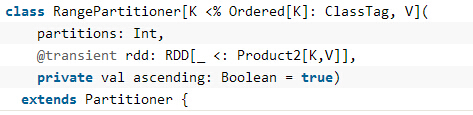
另外一种常用的Partitioner是RangePartitioner:
RDD在持久化的需要考虑内存策略:

Spark提供很多StorageLevel可供选择:

于此同时Spark提供了unpersistRDD:

对RDD本身还有一个非常重要的CheckPoint操作:

其中doCheckpoint的细节如下:

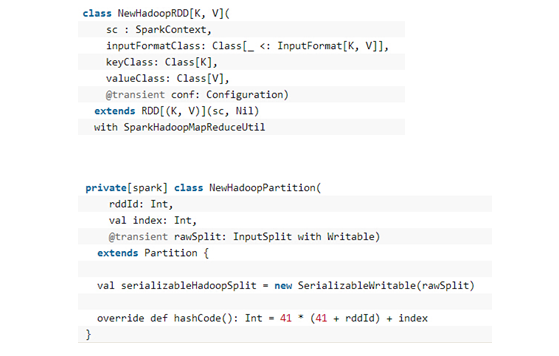
以NewHadoopRDD为例,其内部的信息如下所示:
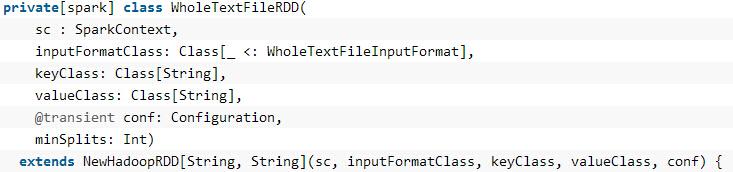
以WholeTextFileRDD为例,其内部的信息如下所示:
RDD在产生作业调用的时候,经典的过程如下所示:

【Spark亚太研究院系列丛书】Spark实战高手之路-第3章Spark架构设计与编程模型第3节②
声明:以上内容来自用户投稿及互联网公开渠道收集整理发布,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任,若内容有误或涉及侵权可进行投诉: 投诉/举报 工作人员会在5个工作日内联系你,一经查实,本站将立刻删除涉嫌侵权内容。