
首页 > 代码库 > Kafka实现细节(三)
Kafka实现细节(三)
如果你第一次看kafka的文章,请先看《分布式消息系统kafka初步》
之前有人问kafka和一般的MQ之间的区别,这个问题挺难回答,我觉得不如从kafka的实现原理来分析更为透彻,这篇将依据官网上给出的design来详细的分析,kafka是如何实现其高性能、高吞吐的。这一段应该会挺长的我想分两篇来写。今天这一篇主要从宏观上说kafka实现的细节,下一篇,在从具体的技术上去分析。
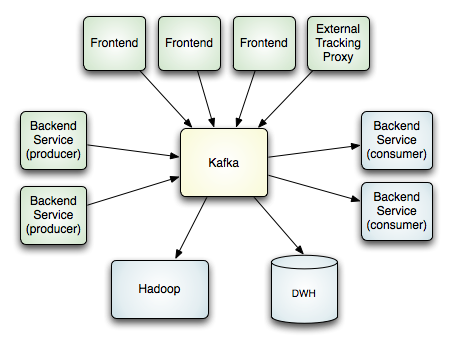
我们先看kafka的设计元素:
1. 通常来说,kafka的使用是为了消息的持久化(persistent messages)
2. 吞吐量是kafka设计的主要目标
3. 关于消费的状态被记录为consumer的一部分,而不是server。这点稍微解释下,这里的server还是只broker,谁消费了多少数据都记录在消费者自己手中,不存在broker中。按理说,消费记录也是一个日志,可以放在broker中,至于为什么要这么设计,我们写下去了再说。
4. Kafka的分布式可以表现在producer、broker、consumer都可以分布在多台机器上。
在讲实现原理之前,我们还得了解几个术语:
l Topic:其实官网上没有单独提这个词,但topic其实才是理解的关键,在kafka中,不同的数据可以按照不同的topic存储。
l Message:消息是kafka处理的对象,在kafka中,消息是被发布到broker的topic中。而consumer也是从相应的topic中拿数据。也就是说,message是按topic存储的。
l Consumer Group:虽然上面的设计元素第四条,我们说三者都可以部署到多台机器上,三者分别并作为一个逻辑的group,但对于consumer来说这样的部署需要特殊的支持。Consumer Group就是让多个(相关的)进程(机器)在逻辑上扮演一个consumer。这个group的定义其实是为了去支持topic这样的语义。在JMS中,大家最熟悉的是队列,我们将所有的consumer放到一个group中,这样就是队列。而topic则是将consumer放置到与它相关的topic中去。所以无论一个topic存在于多少个consumer中, a message is stored only a single time。你可能会有疑问,备份怎么办,接着看下去。
接下来,我们来看kafka的实现究竟依赖了哪些东西。
1. 硬件上,kafka选用了硬盘直接读写,当然这里也有策略。一个67200rpm STAT RAID5的阵列,线性读写速度是300MB/sec,如果是随机读写,速度则是50K/sec。差距很明显,所以kafka选的策略就是利用线性存储,至于怎么存,我们在存储中会说到。
2. 关于缓存,kafka没有使用内存作为缓存。操作系统用个特性,如果不用direct I/O,那些闲置的memory会去做disk caching,如果 a process maintains an in-process cache of the data,这样的情况下可能会产生双份的pagecache,会存储两遍。另外Kafka跑在JVM上,本身JVM垃 圾回收、创建对象都非常的耗内存,所以不再依赖于内存做缓存。All data is immediately written to a persistent log on the filesystem without any call to flush the data. 当然内核自己的flush不算了。温泉做一次32G的内存缓存,需要大概10多分钟。
3. Liner writer/reader:这样做的虽然没有B树那样多样的变化,但却有O(1)的操作,而且读写不会相互影响。同时,线性的读写也解耦了数据规模的问题。用廉价的存储就可以达到很高的性价比。
4. Zero-copy:将数据从硬盘写到socket一般需要经过…你可以自己算一下,这是操作系统里的知识,答案在文章末尾,具体也可以看这里:http://my.oschina.net/ielts0909/blog/85147。一句话,Zero-copy减少了IO的操作步骤。
5. GZIP and Snappy compression:考虑到传输最大的瓶颈就在于网络上,kafka提供了对数据压缩的各种协议。
6. 事务机制:虽然kafka对事务的处理比较薄弱,但是在message的分发上还是做了一定的策略来保证数据递送的准确性:
At most once—this handles the first case described. Messages are immediately marked as consumed, so they can‘t be given out twice, but many failure scenarios may lead to losing messages.
At least once—this is the second case where we guarantee each message will be delivered at least once, but in failure cases may be delivered twice.
Exactly once—this is what people actually want, each message is delivered once and only once.
上述就是关于kafka的实现细节,主要写了关于kafka采用到的技术和使用技术的原因,在后面一篇中,我将主要讲述producer、broker、consumer之间的配合以及kafka的存储问题。
--------------------------------------------------------------------------------
To understand the impact of sendfile, it is important to understand the common data path for transfer of data from file to socket:
- The operating system reads data from the disk into pagecache in kernel space
- The application reads the data from kernel space into a user-space buffer
- The application writes the data back into kernel space into a socket buffer
- The operating system copies the data from the socket buffer to the NIC buffer where it is sent over the network
其实zero-copy这个技术我们已经在使用了,在NIO中的FileChannel中的transferTo就是采用这样的原理的。
在这一篇,我想主要写点儿kafka的存储,以及对前文kafka的分布式一些补充,kafka的应用中,分布式使用是一个很关键的主题,更好的理解producer、broker和consumer的分布式构建有利于提高系统整体的性能。这部分理论其实很简单,所以就不花大精力去写了。
在上一篇中,我们说到了kafka直接使用硬盘作为存储,并且不使用内存缓存。我们还说到,之所以要这么应用,主要是考虑到硬盘在线性读写时候速度完全能满足要求,以及使用内存缓存会带来的一些负面影响。如果你不是很了解,可以先看看之前的那篇。
有关存储方面,我们要引进几个概念:
l Partition:同一个topic下可以设置多个partition,目的是为了提高并行处理的能力。可以将同一个topic下的message存储到不同的partition下。
l Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
l Messages:这里写下message的构成,a fixed-size header和variable length opaque byte array payload组成。Header由version和checksum组成,checksum采用CRC32。
下图就反应了日志都是append的这一个过程:

在写的时候会有两个参数需要注意:The log takes two configuration parameter M which gives the number of messages to write before forcing the OS to flush the file to disk, and S which gives a number of seconds after which a flush is forced.
在分布式方面:
1. broker的部署是一种no central master的概念,并且每个节点都是同等的,节点的增加和减少都不需要改变任何配置。
2. producer和consumer通过zookeeper去发现topic,并且通过zookeeper来协调生产和消费的过程。
3. producer、consumer和broker均采用TCP连接,通信基于NIO实现。Producer和consumer能自动检测broker的增加和减少。
Kafka实现细节(三)