
首页 > 代码库 > CSS选择器的优化
CSS选择器的优化
前面花了几个篇幅着重介绍了CSS的选择器的使用,我将其分成三个部分:CSS3基本选择器、CSS3属性选择器详解以及CSS3伪类选择器详解。那么今天我主要想和大家一起来学习——CSS选择器方面的性能优化。因为对性能这一块一直都是很弱的,所以今天先从选择器开始入手,加强自己。如果你也感兴趣那就跟我一起来吧。
浏览器如何识别你的选择器
首先我们需要清楚,浏览器是如何读取选择器,以识别样式,并将相应的样式附于对应的HTML元素,达到美化页面的效果。Chris Coyier曾在《Efficiently Rendering CSS》一文中说过“浏览器读取你的选择器,遵循的原则是从选择器的右边到左边读取。换句话说,浏览器读取选择器的顺序是由右到左进行”。比如说:
div.nav > ul li a[title]
上面的实例来说,浏览器首先会尝试在你的HTML标签中寻找“a[title]”元素,接着在匹配“li和ul”,最后在去匹配“div.nav”。这就是前成所主的“选择器从右到左的原则”。
选择器的最后一部分,也就是选择器的最右边(在这个例子中就是a[title]部分)部分被称为“关键选择器”,它将决定你的选择器的效率如何?是高还是低。
老版本的浏览器可以过滤掉不匹配的选择器,而直接匹配更高效的选择器。记得David Hyatt在《Writing efficient CSS for use in the Mozilla UI》说过:“这个关键选择器可以大大提高选择器的性能,少检查一个给定的元素规则,就可以更有效的将样式匹配给对应的HTML元素。”那么如何让关键选择器更有效,性能化更高呢?其实很简单,主要把握一点“越具体的关键选择器,其性能越高”
那么什么样类型的选择器,其性能高?什么样的类型的选择器性能低呢?下面我们就针对两个问题来展开具体的学习。
CSS选择器的效率
如果你阅读了本站的有关于选择器类型的介绍的话,你对选择器并不会感到陌生。就算你没读过,我想CSS选择器不会让我们觉得是新东西,比如我们常用的基本选择器“元素标签选择器div”、“id选择器#header”、“类选择器.class”,或者说我们很少见的伪类选择器“:focus”以及更复杂的css3选择器“:nth-child”等等。
选择器有一个固有的效率,我们来看Steve Souders给排的一个顺序:
- id选择器(#myid)
- 类选择器(.myclassname)
- 标签选择器(div,h1,p)
- 相邻选择器(h1+p)
- 子选择器(ul > li)
- 后代选择器(li a)
- 通配符选择器(*)
- 属性选择器(a[rel="external"])
- 伪类选择器(a:hover,li:nth-child)
上面九种选择器的效率是从高到低排下来的,基中ID选择器的效率是最高,而伪类选择器的效率则是最底。详细的介绍大家还可以点击Writing efficient CSS selectors。
综合上面的顺序,我们清楚的知道,id和类名用于关键选择器上效率是最高的,而CSS3的仿伪类和属性选择器,虽然使用方便,但其效率却是最低的。我们下面一起来看几个实例的对比:
div #myid
效率要比下面的高:
#myid div
第一种选择器比第二种选择器效率高,大家或许会问为什么?其实根据前面所介绍的我们就不难理解了,因为第一个选择器的“关键选择器”使用了“ID选择器”,而第二个选择器的“关键选择器”使用的是“标签选择器”,对比下来,“ID选择器”效率高过“标签选择器”,所以说第一个选择器的效率要高于第二个选择器。
在类名或ID名前面加上标签也会致使选择器效率变低的,比如说:
#myid .myclassname
上面两个选择的效率要高于下面的选择器:
p#myid p.myclassname
来自Mozilla的几点建议
David在《Use efficient CSS selectors》中介绍了几种书写高效率的CSS选择器的方法,下面我将他们移到这里来让大家参考:
- 避免普遍规则
- 不要在ID选择器前加标签名或类名
- 不要在类名选择器前加标签名
- 尽可能使用具体的类别
- 避免使用后代选择器
- 标签分类规则中不应该包含一个子选择器
- 子选择器的问题
- 借助相关继承关系
- 使用范围内的样式表
如果你不够清楚上面所讲的是什么,你可以点击这里,他会让你更容易了解这些规则。
我们应该怎么做
前面说“ID选择器”的效率是最高的,那么今天我们写样式,为了提高选择器的效率,是不是我们要在每一个文档的HTML元素中都加入ID名呢?我想这样的做法是没有的。对于一个有语义的代码编写和如何提高性能,以前他们之间如何的平衡?其实这个选择器的效率低一点,对于大多数网站来说并不会有太大的影响,但对于一个大型的网站,产生大量的流量这就会有差别了,也就很值得我们去对他进行优化。那么我们就很有必要的去了解他们是如何工作,比如说,一般情况下哪些选择器的使用效率更高。来看两个简单的例子:
#myid
上面的选择器高于下面的:
p#myid
后者的写法我发现还是有很多朋友这样写,但我不知道你为什么需要在ID前面加一个标签?难道你同一个页面会有多个相同的ID不成?
我们接下来在来看一个实例,用于列表上的,比如说我们制作导航菜单的:
#nav a
高效于:
#nav li a
上面只是介绍了两个常碰到的实例,在这里说这两个实例,主要目的是让你在今后的编写样式时,能注意这方面的的细节,从而加快你的代码效率。
测试你的选择器
Steve Souders给我们提供了一个选择器效率测试,您 可以测试不同的选择器,比较他们之间的效率。
我们一起来看一个Jon Sykes在前几年对后代选择器性能做的测试的对比:
直接类选择器:
.tdxx{ background: red; }与后代选择器:
table tr td.tdxx{ background: red; }上面两个选择器所做的性能测试结果:
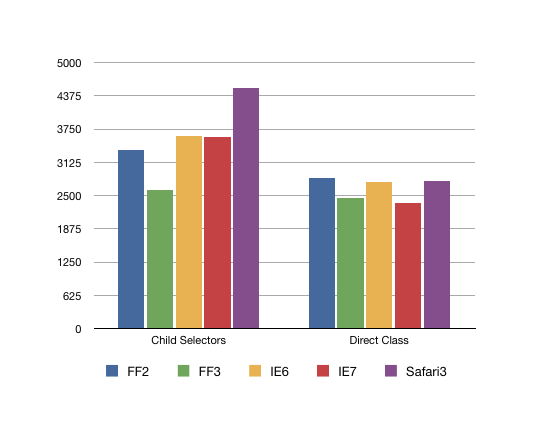
我想上面的图表就能很清楚的说明问题所在了。(注:上面的测试是几年前的数据;纵向是时间ms,模向前面是后代选择器,后面是直接类选择器)。如果你对这个感兴趣可以参阅:
- Testing CSS Performance
- Testing CSS Performance (pt 2)
- More CSS Performance Testing (pt 3)
上面扯了这么多,其实就是想说,CSS的选择器对一个网站的性能也是有关系的,学习之后,希望大家在平时的编写之时能尽量克服一些没必要的错误,从而提高这方面的性能。希望这篇文章对大家有所帮助。如果你有更好的建议,请随时在评论中给我留言。
感谢W3CPLUS提供精彩原文。
欢迎大家加入互联网技术交流群:62329335