
首页 > 代码库 > 【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第二步)(1)
【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第二步)(1)
在VMWare 中准备第二、第三台运行Ubuntu系统的机器;
在VMWare中构建第二、三台运行Ubuntu的机器和构建第一台机器完全一样,再次不在赘述。。
与安装第一台Ubuntu机器不同的几点是:
第一点:我们把第二、三台Ubuntu机器命名为了Slave1、Slave2,如下图所示:
创建完的VMware中就有三台虚拟机了:

第二点:为了简化Hadoop的配置,保持最小化的Hadoop集群,在构建第二、三台机器的时候使用相同的root超级用户的方式登录系统。
2.按照配置伪分布式模式的方式配置新创建运行Ubuntu系统的机器;
按照配置伪分布式模式的方式配置新创建运行Ubuntu系统的机器和配置第一台机器完全相同,
下图是家林完全安装好后的截图:

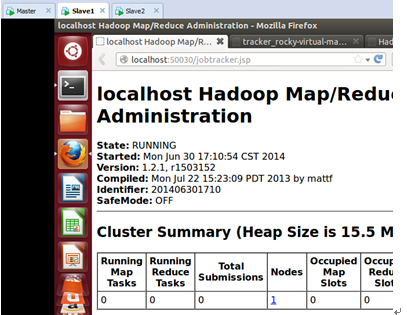
3. 配置Hadoop分布式集群环境;
根据前面的配置,我们现在已经有三台运行在VMware中装有Ubuntu系统的机器,分别是:Master、Slave1、Slave2;
下面开始配置Hadoop分布式集群环境:
Step 1:在/etc/hostname中修改主机名并在/etc/hosts中配置主机名和IP地址的对应关系:
我们把Master这台机器作为Hadoop的主节点,首先看一下Master这台机器的IP地址:

可以看到当前主机的ip地址是“192.168.184.133”.
我们在/etc/hostname中修改主机名:

进入配置文件:

可以看到按照我们装Ubuntu系统时候的默认名称,配置文件中的机器的名称是” rocky-virtual-machine”,我们把” rocky-virtual-machine”改为“Master”作为Hadoop分布式集群环境的主节点:

保存退出。此时使用以下命令查看当前主机的主机名:

发现修改的主机名没有生效,为使得新修改的主机名生效,我们重新启动系统后再次查看主机名:
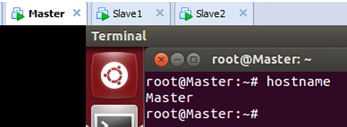
发现我们的主机名成为了修改后的“Master”,表明修改成功。
打开在/etc/hosts 文件:

此时我们发现文件中只有Ubuntu系统的原始ip(127.0.0.1)地址和主机名(localhost)的对应关系:
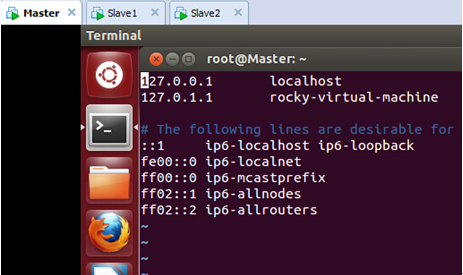
我们在/etc/hosts中配置主机名和IP地址的对应关系:

修改之后保存退出。
接下来我们使用“ping”命令看一下主机名和IP地址只见的转换关系是否正确:

可以看到此时我们的主机“Master”对应的IP地址是“192.168.184.133”,这表明我们的配置和运行都是正确的。
【Spark亚太研究院系列丛书】Spark实战高手之路-第一章 构建Spark集群(第二步)(1)