
首页 > 代码库 > 跳跃表,字典树(单词查找树,Trie树),后缀树,KMP算法,AC 自动机相关算法原理详细汇总
跳跃表,字典树(单词查找树,Trie树),后缀树,KMP算法,AC 自动机相关算法原理详细汇总
第一部分:跳跃表
本文将总结一种数据结构:跳跃表。前半部分跳跃表性质和操作的介绍直接摘自《让算法的效率跳起来--浅谈“跳跃表”的相关操作及其应用》上海市华东师范大学第二附属中学 魏冉。之后将附上跳跃表的源代码,以及本人对其的了解。难免有错误之处,希望指正,共同进步。谢谢。
跳跃表(Skip List)是1987年才诞生的一种崭新的数据结构,它在进行查找、插入、删除等操作时的期望时间复杂度均为O(logn),有着近乎替代平衡树的本领。而且最重要的一点,就是它的编程复杂度较同类的AVL树,红黑树等要低得多,这使得其无论是在理解还是在推广性上,都有着十分明显的优势。
首先,我们来看一下跳跃表的结构

跳跃表由多条链构成(S0,S1,S2 ……,Sh),且满足如下三个条件:
- 每条链必须包含两个特殊元素:+∞ 和 -∞(其实不需要)
- S0包含所有的元素,并且所有链中的元素按照升序排列。
- 每条链中的元素集合必须包含于序数较小的链的元素集合。
操作
一、查找
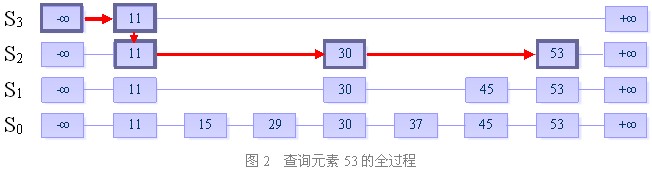
目的:在跳跃表中查找一个元素x
在跳跃表中查找一个元素x,按照如下几个步骤进行:
1. 从最上层的链(Sh)的开头开始
2. 假设当前位置为p,它向右指向的节点为q(p与q不一定相邻),且q的值为y。将y与x作比较
(1) x=y 输出查询成功及相关信息
(2) x>y 从p向右移动到q的位置
(3) x<y 从p向下移动一格
3. 如果当前位置在最底层的链中(S0),且还要往下移动的话,则输出查询失败
二、插入
目的:向跳跃表中插入一个元素x
首先明确,向跳跃表中插入一个元素,相当于在表中插入一列从S0中某一位置出发向上的连续一段元素。有两个参数需要确定,即插入列的位置以及它的“高度”。
关于插入的位置,我们先利用跳跃表的查找功能,找到比x小的最大的数y。根据跳跃表中所有链均是递增序列的原则,x必然就插在y的后面。
而插入列的“高度”较前者来说显得更加重要,也更加难以确定。由于它的不确定性,使得不同的决策可能会导致截然不同的算法效率。为了使插入数据之后,保持该数据结构进行各种操作均为O(logn)复杂度的性质,我们引入随机化算法(Randomized Algorithms)。
我们定义一个随机决策模块,它的大致内容如下:
- 产生一个0到1的随机数r r ← random()
- 如果r小于一个常数p,则执行方案A, if r<p then do A
- 否则,执行方案B else do B
初始时列高为1。插入元素时,不停地执行随机决策模块。如果要求执行的是A操作,则将列的高度加1,并且继续反复执行随机决策模块。直到第i次,模块要求执行的是B操作,我们结束决策,并向跳跃表中插入一个高度为i的列。
我们来看一个例子:
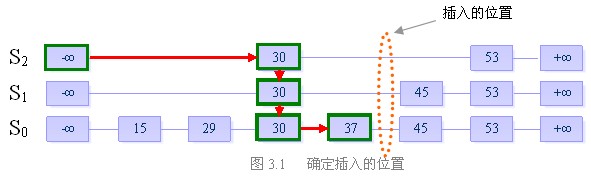
假设当前我们要插入元素“40”,且在执行了随机决策模块后得到高度为4
步骤一:找到表中比40小的最大的数,确定插入位置
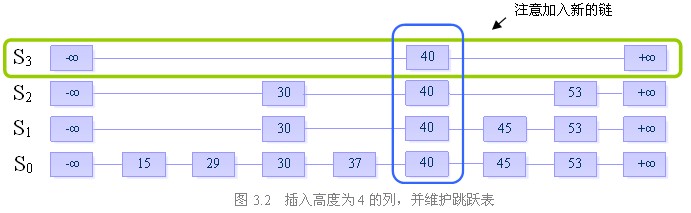
步骤二:插入高度为4的列,并维护跳跃表的结构
三、删除
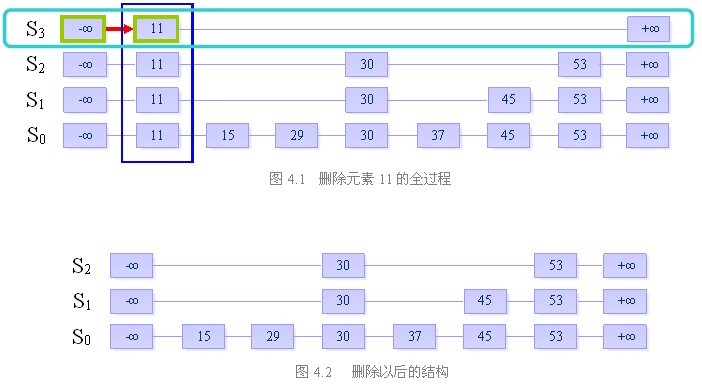
目的:从跳跃表中删除一个元素x
删除操作分为以下三个步骤:
- 在跳跃表中查找到这个元素的位置,如果未找到,则退出
- 将该元素所在整列从表中删除
- 将多余的“空链”删除
我们来看一下跳跃表的相关复杂度:
空间复杂度: O(n) (期望)
跳跃表高度: O(logn) (期望)
相关操作的时间复杂度:
查找: O(logn) (期望)
插入: O(logn) (期望)
删除: O(logn) (期望)
之所以在每一项后面都加一个“期望”,是因为跳跃表的复杂度分析是基于概率论的。有可能会产生最坏情况,不过这种概率极其微小。
以下是自己学习时碰到的一些问题
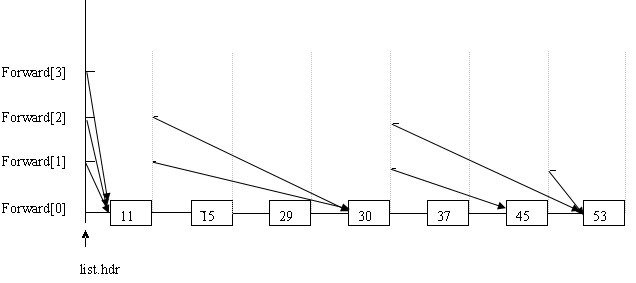
首先分配一个链表,用list.hdr指向,长度为跳跃表规定的最高层,说是链表,在以下代码中只是分配了一段连续的空间,用来指向每一层的开始位置。我们看到结构体nodeType中,有一个key,一个rec(用户数据),还有一个指向结构体的指针数组。
一开始的那些图容易给人误解。如上图所示,例如每个节点的forward[2],就认为是跳跃表的第3层。List.hdr的forward[2]指向11,11的forward[2]指向30,30的forward[2]指向53。这就是跳跃表的第3层:11---30-----53。(准确的说每个forward都指向新节点,新节点的同层forward又指向另一个节点,从而构成一个链表,而数据只有一个,并不是像开始途中所画的那样有N个副本)。
第二部分:字典树(单词查找树,Trie树)
它有三个基本性质,根节点不包含字符,除根节点外每一个节点都只包含一个字符,从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串,每个节点的所有子节点包含的字符都不相同。
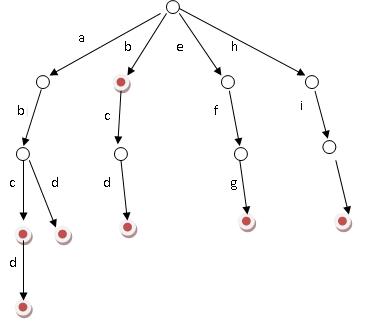
1. 从根节点开始一次搜索
2. 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索
3. 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索
4. 迭代过程...
5. 在某个节点处,关键词的所有字母已被取出,则读取附在该节点上的信息,即完成查找
字典树的应用
1.字典树在串的快速检索中的应用。
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
在这道题中,我们可以用数组枚举,用哈希,用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
2. 字典树在“串”排序方面的应用
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出
用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可
3. 字典树在最长公共前缀问题的应用
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为最近公共祖先问题(以后补上)。
第三部分:后缀树
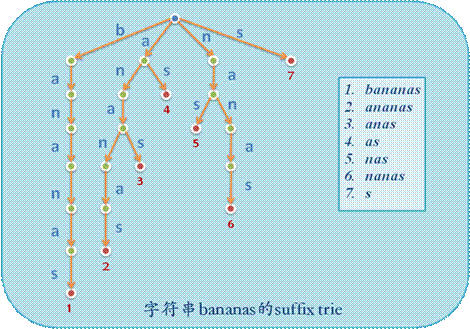
后缀树(Suffix Tree),包含了一个或者多个字符串的所有后缀,空字符串也算是其中一个后缀。字符串 bananas,其所有后缀为bananas ananas nanas anas nas as s $(表示空),我们可以把后缀树看作是所有后缀组成的一棵字典树,关于字典树请参考上一篇文章。
下面的图片引用自http://www.cppblog.com/yuyang7/archive/2009/03/29/78252.html,感谢作者
在图中就不再表示空下了
下图就是把所有的后缀组成一棵下字典树
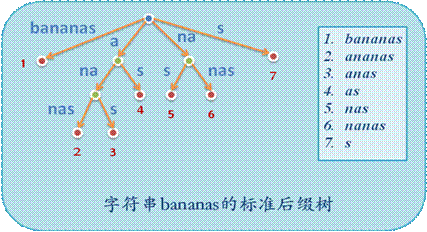
1. 查找一个字符串S是否包含了字符串T
如果S包含T,那么T必定是S的某个后缀的前缀,因为S的后缀包含了所有的后缀,因此只需要对S的后缀树使用和字典树相同的查找方法就行
2. 统计S中出现T的次数
每出现一次T,必定对应着一个不同的后缀,而这所有的后缀又都有着共同的前缀T。所以在这公共前缀下一共有多少个串,就是T的出现次数。
3. 找出S中最长的重复子串,出现了两次以上的串
找到含有两个儿子的最深的节点,根节点到这个节点的串就是最长的重复子串。
第四部分:KMP算法
原文地址 http://www.matrix67.com/blog/archives/115
我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法。KMP算法是拿来处理字符串匹配的。换句话说,给你两个字符串,你需要回答,B串是否是A串的子串(A串是否包含B串)。比如,字符串A="I‘m matrix67",字符串B="matrix",我们就说B是A的子串。你可以委婉地问你的MM:“假如你要向你喜欢的人表白的话,我的名字是你的告白语中的子串吗?”
解决这类问题,通常我们的方法是枚举从A串的什么位置起开始与B匹配,然后验证是否匹配。假如A串长度为n,B串长度为m,那么这种方法的复杂度是O (mn)的。虽然很多时候复杂度达不到mn(验证时只看头一两个字母就发现不匹配了),但我们有许多“最坏情况”,比如,A= "aaaaaaaaaaaaaaaaaaaaaaaaaab",B="aaaaaaaab"。我们将介绍的是一种最坏情况下O(n)的算法(这里假设 m<=n),即传说中的KMP算法。
之所以叫做KMP,是因为这个算法是由Knuth、Morris、Pratt三个提出来的,取了这三个人的名字的头一个字母。这时,或许你突然明白了AVL 树为什么叫AVL,或者Bellman-Ford为什么中间是一杠不是一个点。有时一个东西有七八个人研究过,那怎么命名呢?通常这个东西干脆就不用人名字命名了,免得发生争议,比如“3x+1问题”。扯远了。
个人认为KMP是最没有必要讲的东西,因为这个东西网上能找到很多资料。但网上的讲法基本上都涉及到“移动(shift)”、“Next函数”等概念,这非常容易产生误解(至少一年半前我看这些资料学习KMP时就没搞清楚)。在这里,我换一种方法来解释KMP算法。
假如,A="abababaababacb",B="ababacb",我们来看看KMP是怎么工作的。我们用两个指针i和j分别表示,A[i-j+ 1..i]与B[1..j]完全相等。也就是说,i是不断增加的,随着i的增加j相应地变化,且j满足以A[i]结尾的长度为j的字符串正好匹配B串的前 j个字符(j当然越大越好),现在需要检验A[i+1]和B[j+1]的关系。当A[i+1]=B[j+1]时,i和j各加一;什么时候j=m了,我们就说B是A的子串(B串已经整完了),并且可以根据这时的i值算出匹配的位置。当A[i+1]<>B[j+1],KMP的策略是调整j的位置(减小j值)使得A[i-j+1..i]与B[1..j]保持匹配且新的B[j+1]恰好与A[i+1]匹配(从而使得i和j能继续增加)。我们看一看当 i=j=5时的情况。
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
此时,A[6]<>B[6]。这表明,此时j不能等于5了,我们要把j改成比它小的值j‘。j‘可能是多少呢?仔细想一下,我们发现,j‘必须要使得B[1..j]中的头j‘个字母和末j‘个字母完全相等(这样j变成了j‘后才能继续保持i和j的性质)。这个j‘当然要越大越好。在这里,B [1..5]="ababa",头3个字母和末3个字母都是"aba"。而当新的j为3时,A[6]恰好和B[4]相等。于是,i变成了6,而j则变成了 4:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
从上面的这个例子,我们可以看到,新的j可以取多少与i无关,只与B串有关。我们完全可以预处理出这样一个数组P[j],表示当匹配到B数组的第j个字母而第j+1个字母不能匹配了时,新的j最大是多少。P[j]应该是所有满足B[1..P[j]]=B[j-P[j]+1..j]的最大值。
再后来,A[7]=B[5],i和j又各增加1。这时,又出现了A[i+1]<>B[j+1]的情况:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
由于P[5]=3,因此新的j=3:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
这时,新的j=3仍然不能满足A[i+1]=B[j+1],此时我们再次减小j值,将j再次更新为P[3]:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 1 2 3 4 5 6 7
现在,i还是7,j已经变成1了。而此时A[8]居然仍然不等于B[j+1]。这样,j必须减小到P[1],即0:
i = 1 2 3 4 5 6 7 8 9 ……
A = a b a b a b a a b a b …
B = a b a b a c b
j = 0 1 2 3 4 5 6 7
终于,A[8]=B[1],i变为8,j为1。事实上,有可能j到了0仍然不能满足A[i+1]=B[j+1](比如A[8]="d"时)。因此,准确的说法是,当j=0了时,我们增加i值但忽略j直到出现A[i]=B[1]为止。
这个过程的代码很短(真的很短),我们在这里给出:
j:=0;
for i:=1 to n do
begin
while (j>0) and (B[j+1]<>A[i]) do j:=P[j];
if B[j+1]=A[i] then j:=j+1;
if j=m then
begin
writeln(‘Pattern occurs with shift ‘,i-m);
j:=P[j];
end;
end;
最后的j:=P[j]是为了让程序继续做下去,因为我们有可能找到多处匹配。
这个程序或许比想像中的要简单,因为对于i值的不断增加,代码用的是for循环。因此,这个代码可以这样形象地理解:扫描字符串A,并更新可以匹配到B的什么位置。
现在,我们还遗留了两个重要的问题:一,为什么这个程序是线性的;二,如何快速预处理P数组。
为什么这个程序是O(n)的?其实,主要的争议在于,while循环使得执行次数出现了不确定因素。我们将用到时间复杂度的摊还分析中的主要策略,简单地说就是通过观察某一个变量或函数值的变化来对零散的、杂乱的、不规则的执行次数进行累计。KMP的时间复杂度分析可谓摊还分析的典型。我们从上述程序的j 值入手。每一次执行while循环都会使j减小(但不能减成负的),而另外的改变j值的地方只有第五行。每次执行了这一行,j都只能加1;因此,整个过程中j最多加了n个1。于是,j最多只有n次减小的机会(j值减小的次数当然不能超过n,因为j永远是非负整数)。这告诉我们,while循环总共最多执行了n次。按照摊还分析的说法,平摊到每次for循环中后,一次for循环的复杂度为O(1)。整个过程显然是O(n)的。这样的分析对于后面P数组预处理的过程同样有效,同样可以得到预处理过程的复杂度为O(m)。
预处理不需要按照P的定义写成O(m^2)甚至O(m^3)的。我们可以通过P[1],P[2],...,P[j-1]的值来获得P[j]的值。对于刚才的B="ababacb",假如我们已经求出了P[1],P[2],P[3]和P[4],看看我们应该怎么求出P[5]和P[6]。P[4]=2,那么P [5]显然等于P[4]+1,因为由P[4]可以知道,B[1,2]已经和B[3,4]相等了,现在又有B[3]=B[5],所以P[5]可以由P[4] 后面加一个字符得到。P[6]也等于P[5]+1吗?显然不是,因为B[ P[5]+1 ]<>B[6]。那么,我们要考虑“退一步”了。我们考虑P[6]是否有可能由P[5]的情况所包含的子串得到,即是否P[6]=P[ P[5] ]+1。这里想不通的话可以仔细看一下:
1 2 3 4 5 6 7
B = a b a b a c b
P = 0 0 1 2 3 ?
P[5]=3是因为B[1..3]和B[3..5]都是"aba";而P[3]=1则告诉我们,B[1]、B[3]和B[5]都是"a"。既然P[6]不能由P[5]得到,或许可以由P[3]得到(如果B[2]恰好和B[6]相等的话,P[6]就等于P[3]+1了)。显然,P[6]也不能通过P[3]得到,因为B[2]<>B[6]。事实上,这样一直推到P[1]也不行,最后,我们得到,P[6]=0。
怎么这个预处理过程跟前面的KMP主程序这么像呢?其实,KMP的预处理本身就是一个B串“自我匹配”的过程。它的代码和上面的代码神似:
P[1]:=0;
j:=0;
for i:=2 to m do
begin
while (j>0) and (B[j+1]<>B[i]) do j:=P[j];
if B[j+1]=B[i] then j:=j+1;
P[i]:=j;
end;
最后补充一点:由于KMP算法只预处理B串,因此这种算法很适合这样的问题:给定一个B串和一群不同的A串,问B是哪些A串的子串。
串匹配是一个很有研究价值的问题。事实上,我们还有后缀树,自动机等很多方法,这些算法都巧妙地运用了预处理,从而可以在线性的时间里解决字符串的匹配。我们以后来说。
第五部分:AC 自动机
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一。一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。要搞懂AC自动机,先得有模式树(字典树)Trie和KMP模式匹配算法的基础知识。AC自动机算法分为3步:构造一棵Trie树,构造失败指针和模式匹配过程。
如果你对KMP算法和了解的话,应该知道KMP算法中的next函数(shift函数或者fail函数)是干什么用的。KMP中我们用两个指针i和j分别表示,A[i-j+ 1..i]与B[1..j]完全相等。也就是说,i是不断增加的,随着i的增加j相应地变化,且j满足以A[i]结尾的长度为j的字符串正好匹配B串的前 j个字符,当A[i+1]≠B[j+1],KMP的策略是调整j的位置(减小j值)使得A[i-j+1..i]与B[1..j]保持匹配且新的B[j+1]恰好与A[i+1]匹配,而next函数恰恰记录了这个j应该调整到的位置。同样AC自动机的失败指针具有同样的功能,也就是说当我们的模式串在Tire上进行匹配时,如果与当前节点的关键字不能继续匹配的时候,就应该去当前节点的失败指针所指向的节点继续进行匹配。
看下面这个例子:给定5个单词:say she shr he her,然后给定一个字符串yasherhs。问一共有多少单词在这个字符串中出现过。我们先规定一下AC自动机所需要的一些数据结构,方便接下去的编程。
- const int kind = 26;
- struct node
- {
- node *fail; //失败指针
- node *next[kind]; //Tire每个节点的个子节点(最多个字母)
- int count; //是否为该单词的最后一个节点
- node() //构造函数初始化
- {
- fail = NULL;
- count = 0;
- memset(next,0,sizeof(next));
- }
- }*q[500001]; //队列,方便用于bfs构造失败指针
- char str[1000001]; //模式串
- int head,tail; //队列的头尾指针
有了这些数据结构之后,就可以开始编程了:
首先,将这5个单词构造成一棵Tire,如图-1所示。
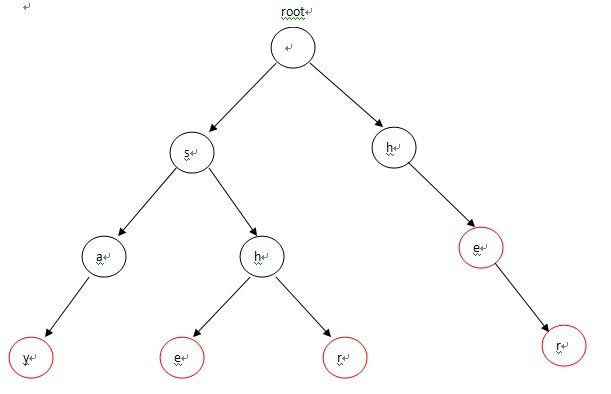
- void insert(char *str,node *root)
- {
- node *p = root;
- int i=0,index;
- while(str[i])
- {
- index = str[i] - ‘a‘;
- if(p->next[index] == NULL)
- p->next[index] = new node();
- p = p->next[index];
- i++;
- }
- p->count++; //在单词的最后一个节点count+1,代表一个单词
- }
在构造完这棵Tire之后,接下去的工作就是构造下失败指针。构造失败指针的过程概括起来就一句话:设这个节点上的字母为C,沿着他父亲的失败指针走,直到走到一个节点,他的儿子中也有字母为C的节点。然后把当前节点的失败指针指向那个字母也为C的儿子。如果一直走到了root都没找到,那就把失败指针指向root。具体操作起来只需要:先把root加入队列(root的失败指针指向自己或者NULL),这以后我们每处理一个点,就把它的所有儿子加入队列,队列为空。
- void build_ac_automation(node *root)
- {
- int i;
- root->fail = NULL;
- q[head++] = root;
- while(head != tail)
- {
- node *temp = q[tail++];
- node *p = NULL;
- for(i=0;i<26;i++)
- {
- if(temp->next[i] != NULL)
- {
- if(temp == root)
- temp->next[i]->fail = root;
- else
- {
- p = temp->fail;
- while(p != NULL)
- {
- if(p->next[i] != NULL)
- {
- temp->next[i]->fail = p->next[i];
- break;
- }
- p = p->fail;
- }
- if(p == NULL)
- temp->next[i]->fail = root;
- }
- q[head++] = temp->next[i];
- }
- }
- }
- }
从代码观察下构造失败指针的流程:对照图-2来看,首先root的fail指针指向NULL,然后root入队,进入循环。第1次循环的时候,我们需要处理2个节点:root->next[‘h’-‘a’](节点h) 和 root->next[‘s’-‘a’](节点s)。把这2个节点的失败指针指向root,并且先后进入队列,失败指针的指向对应图-2中的(1),(2)两条虚线;第2次进入循环后,从队列中先弹出h,接下来p指向h节点的fail指针指向的节点,也就是root;进入第13行的循环后,p=p->fail也就是p=NULL,这时退出循环,并把节点e的fail指针指向root,对应图-2中的(3),然后节点e进入队列;第3次循环时,弹出的第一个节点a的操作与上一步操作的节点e相同,把a的fail指针指向root,对应图-2中的(4),并入队;第4次进入循环时,弹出节点h(图中左边那个),这时操作略有不同。在程序运行到14行时,由于p->next[i]!=NULL(root有h这个儿子节点,图中右边那个),这样便把左边那个h节点的失败指针指向右边那个root的儿子节点h,对应图-2中的(5),然后h入队。以此类推:在循环结束后,所有的失败指针就是图-2中的这种形式。
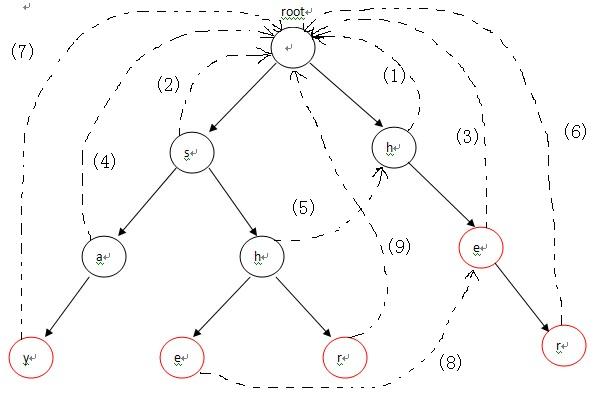
最后,我们便可以在AC自动机上查找模式串中出现过哪些单词了。匹配过程分两种情况:(1)当前字符匹配,表示从当前节点沿着树边有一条路径可以到达目标字符,此时只需沿该路径走向下一个节点继续匹配即可,目标字符串指针移向下个字符继续匹配;(2)当前字符不匹配,则去当前节点失败指针所指向的字符继续匹配,匹配过程随着指针指向root结束。重复这2个过程中的任意一个,直到模式串走到结尾为止。
- int query(node *root)
- {
- int i = 0,cnt = 0,index,len = strlen(str);
- node *p = root;
- while(str[i])
- {
- index = str[i] - ‘a‘;
- while(p->next[index] == NULL && p != root)
- p = p->fail;
- p = p->next[index];
- p = (p == NULL) ? root : p;
- node *temp = p;
- while(temp != root && temp->count != -1)
- {
- cnt += temp->count;
- if(temp->count > 0)
- temp->count = -1;
- temp = temp->fail;
- }
- i++;
- }
- return cnt;
- }
对照图-2,看一下模式匹配这个详细的流程,其中模式串为yasherhs。对于i=0,1。Trie中没有对应的路径,故不做任何操作;i=2,3,4时,指针p走到左下节点e。因为节点e的count信息为1,所以cnt+1,并且讲节点e的count值设置为-1,表示改单词已经出现过了,防止重复计数,最后temp指向e节点的失败指针所指向的节点继续查找,以此类推,最后temp指向root,退出while循环,这个过程中count增加了2。表示找到了2个单词she和he。当i=5时,程序进入第5行,p指向其失败指针的节点,也就是右边那个e节点,随后在第6行指向r节点,r节点的count值为1,从而count+1,循环直到temp指向root为止。最后i=6,7时,找不到任何匹配,匹配过程结束。
到此为止AC自动机算法的详细过程已经全部介绍结束,看一道例题:
http://acm.hdu.edu.cn/showproblem.php?pid=2222
参考文献来自:http://blog.csdn.net/topcoder1234/跳跃表,字典树(单词查找树,Trie树),后缀树,KMP算法,AC 自动机相关算法原理详细汇总