
首页 > 代码库 > 【机器学习算法-python实现】协同过滤(cf)的三种方法实现
【机器学习算法-python实现】协同过滤(cf)的三种方法实现
(转载请注明出处:http://blog.csdn.net/buptgshengod)
1.背景
icf指的是item collaborative filtering,是将商品进行分析推荐。同理ucf的u指的是user,他是找出知趣类似的人,进行推荐。
通常来讲icf的准确率可能会高一些。通过这次參加天猫大数据比赛。我认为仅仅有在数据量很庞大的时候才适合用cf,假设数据量很小。cf的准确率会很可怜。
博主在比赛s1阶段,大概仅仅有几万条数据的时候,尝试了icf,准确率不到百分之中的一个。
。。
。。
2.经常用法

(1)欧氏距离法
 。
。数值越小。表示类似的越高。
def OsDistance(vector1, vector2):
sqDiffVector = vector1-vector2
sqDiffVector=sqDiffVector**2
sqDistances = sqDiffVector.sum()
distance = sqDistances**0.5
return distance(2)皮尔逊相关系数
两个变量之间的相关系数越高。从一个变量去预測还有一个变量的准确度就越高,这是由于相关系数越高,就意味着这两个变量的共变部分越多,所以从当中一个变量的变化就可越多地获知还有一个变量的变化。
假设两个变量之间的相关系数为1或-1,那么你全然可由变量X去获知变量Y的值。
· 当相关系数为0时。X和Y两变量无关系。
· 当X的值增大。Y也增大。正相关关系,相关系数在0.00与1.00之间
· 当X的值减小,Y也减小,正相关关系。相关系数在0.00与1.00之间
· 当X的值增大。Y减小,负相关关系。相关系数在-1.00与0.00之间
当X的值减小。Y增大,负相关关系,相关系数在-1.00与0.00之间
相关系数的绝对值越大。相关性越强,相关系数越接近于1和-1,相关度越强,相关系数越接近于0,相关度越弱。

在python中用函数corrcoef实现。详细方法见http://infosec.pku.edu.cn/~dulz/doc/Numpy_Example_List.htm
(3)余弦类似度
0度角的余弦值是1,而其它不论什么角度的
在比較过程中。向量的规模大小不予考虑,仅仅考虑到向量的指向方向。余弦相
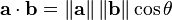
def cosSim(inA,inB):
num = float(inA.T*inB)
denom = la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom)【机器学习算法-python实现】协同过滤(cf)的三种方法实现