
首页 > 代码库 > Trie树
Trie树
参考博文:http://blog.csdn.net/v_july_v/article/details/6897097
第一部分、Trie树
1.1、什么是Trie树
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
它有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
1.2、树的构建
举个在网上流传颇广的例子,如下:
题目:给你100000个长度不超过10的单词。对于每一个单词,我们要判断他出没出现过,如果出现了,求第一次出现在第几个位置。
分析:这题当然可以用hash来解决,但是本文重点介绍的是trie树,因为在某些方面它的用途更大。比如说对于某一个单词,我们要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单。
现在回到例子中,如果我们用最傻的方法,对于每一个单词,我们都要去查找它前面的单词中是否有它。那么这个算法的复杂度就是O(n^2)。显然对于100000的范围难以接受。现在我们换个思路想。假设我要查询的单词是abcd,那么在他前面的单词中,以b,c,d,f之类开头的我显然不必考虑。而只要找以a开头的中是否存在abcd就可以了。同样的,在以a开头中的单词中,我们只要考虑以b作为第二个字母的,一次次缩小范围和提高针对性,这样一个树的模型就渐渐清晰了。
好比假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,我们构建的树就是如下图这样的:
分析:这题当然可以用hash来解决,但是本文重点介绍的是trie树,因为在某些方面它的用途更大。比如说对于某一个单词,我们要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单。
现在回到例子中,如果我们用最傻的方法,对于每一个单词,我们都要去查找它前面的单词中是否有它。那么这个算法的复杂度就是O(n^2)。显然对于100000的范围难以接受。现在我们换个思路想。假设我要查询的单词是abcd,那么在他前面的单词中,以b,c,d,f之类开头的我显然不必考虑。而只要找以a开头的中是否存在abcd就可以了。同样的,在以a开头中的单词中,我们只要考虑以b作为第二个字母的,一次次缩小范围和提高针对性,这样一个树的模型就渐渐清晰了。
好比假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,我们构建的树就是如下图这样的:

当时第一次看到这幅图的时候,便立马感到此树之不凡构造了。单单从上幅图便可窥知一二,好比大海搜人,立马就能确定东南西北中的到底哪个方位,如此迅速缩小查找的范围和提高查找的针对性,不失为一创举。
ok,如上图所示,对于每一个节点,从根遍历到他的过程就是一个单词,如果这个节点被标记为红色,就表示这个单词存在,否则不存在。
那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了。把这个节点标记为红色,就相当于插入了这个单词。
这样一来我们查询和插入可以一起完成(重点体会这个查询和插入是如何一起完成的,稍后,下文具体解释),所用时间仅仅为单词长度,在这一个样例,便是10。
我们可以看到,trie树每一层的节点数是26^i级别的。所以为了节省空间。我们用动态链表,或者用数组来模拟动态。空间的花费,不会超过单词数×单词长度。
ok,如上图所示,对于每一个节点,从根遍历到他的过程就是一个单词,如果这个节点被标记为红色,就表示这个单词存在,否则不存在。
那么,对于一个单词,我只要顺着他从根走到对应的节点,再看这个节点是否被标记为红色就可以知道它是否出现过了。把这个节点标记为红色,就相当于插入了这个单词。
这样一来我们查询和插入可以一起完成(重点体会这个查询和插入是如何一起完成的,稍后,下文具体解释),所用时间仅仅为单词长度,在这一个样例,便是10。
我们可以看到,trie树每一层的节点数是26^i级别的。所以为了节省空间。我们用动态链表,或者用数组来模拟动态。空间的花费,不会超过单词数×单词长度。
1.3、前缀查询
上文中提到”比如说对于某一个单词,我们要询问它的前缀是否出现过。这样hash就不好搞了,而用trie还是很简单“。下面,咱们来看看这个前缀查询问题:
已知n个由小写字母构成的平均长度为10的单词,判断其中是否存在某个串为另一个串的前缀子串。下面对比3种方法:
- 最容易想到的:即从字符串集中从头往后搜,看每个字符串是否为字符串集中某个字符串的前缀,复杂度为O(n^2)。
- 使用hash:我们用hash存下所有字符串的所有的前缀子串,建立存有子串hash的复杂度为O(n*len),而查询的复杂度为O(n)* O(1)= O(n)。
- 使用trie:因为当查询如字符串abc是否为某个字符串的前缀时,显然以b,c,d....等不是以a开头的字符串就不用查找了。所以建立trie的复杂度为O(n*len),而建立+查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂度也只是O(len)。(说白了,就是Trie树的平均高度h为len,所以Trie树的查询复杂度为O(h)=O(len)。好比一棵二叉平衡树的高度为logN,则其查询,插入的平均时间复杂度亦为O(logN))。
下面解释下上述方法3中所说的为什么hash不能将建立与查询同时执行,而Trie树却可以:
- 在hash中,例如现在要输入两个串911,911456,如果要同时查询这两个串,且查询串的同时若hash中没有则存入。那么,这个查询与建立的过程就是先查询其中一个串911,没有,然后存入9、91、911;而后查询第二个串911456,没有然后存入9、91、911、9114、91145、911456。因为程序没有记忆功能,所以并不知道911在输入数据中出现过,只是照常以例行事,存入9、91、911、9114、911...。也就是说用hash必须先存入所有子串,然后for循环查询。
- 而trie树中,存入911后,已经记录911为出现的字符串,在存入911456的过程中就能发现而输出答案;倒过来亦可以,先存入911456,在存入911时,当指针指向最后一个1时,程序会发现这个1已经存在,说明911必定是某个字符串的前缀。
读者反馈@悠悠长风:关于这点,我有不同的看法。hash也是可以实现边建立边查询的啊。当插入911时,需要一个额外的标志位,表示它是一个完整的单词。在处理911456时,也是按照前面的查询9,91,911,当查询911时,是可以找到前面插入的911,且通过标志位知道911为一个完整单词。那么就可以判断出911为911456的前缀啊。虽然trie树更适合这个问题,但是我认为hash也是可以实现边建立,边查找。
吾答曰:但若反过来呢?比如说是先查询911456,而后查询911呢?你的在hash中做一个完整单词的标志就行不通了。因为,你查询911456时,并不知道后来911会是一个完整的单词。
至于,有关Trie树的查找,插入等操作的实现代码,网上遍地开花且千篇一律,诸君尽可参考,想必不用我再做多余费神。
1.4、查询
Trie树是简单但实用的数据结构,通常用于实现字典查询。我们做即时响应用户输入的AJAX搜索框时,就是Trie开始。本质上,Trie是一颗存储多个字符串的树。相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。下面,再举一个例子。给出一组单词,inn, int, at, age, adv, ant, 我们可以得到下面的Trie:
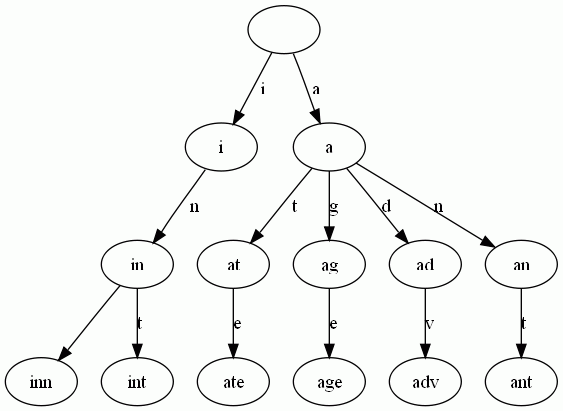
可以看出:
- 每条边对应一个字母。
- 每个节点对应一项前缀。叶节点对应最长前缀,即单词本身。
- 单词inn与单词int有共同的前缀“in”, 因此他们共享左边的一条分支,root->i->in。同理,ate, age, adv, 和ant共享前缀"a",所以他们共享从根节点到节点"a"的边。
查询操纵非常简单。比如要查找int,顺着路径i -> in -> int就找到了。
搭建Trie的基本算法也很简单,无非是逐一把每则单词的每个字母插入Trie。插入前先看前缀是否存在。如果存在,就共享,否则创建对应的节点和边。比如要插入单词add,就有下面几步:
- 考察前缀"a",发现边a已经存在。于是顺着边a走到节点a。
- 考察剩下的字符串"dd"的前缀"d",发现从节点a出发,已经有边d存在。于是顺着边d走到节点ad
- 考察最后一个字符"d",这下从节点ad出发没有边d了,于是创建节点ad的子节点add,并把边ad->add标记为d。
1.5、Trie树的应用
除了本文引言处所述的问题能应用Trie树解决之外,Trie树还能解决下述问题(节选自此文:海量数据处理面试题集锦):
- 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
- 9、1000万字符串,其中有些是重复的,需要把重复的全部去掉,保留没有重复的字符串。请怎么设计和实现?
- 10、 一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前10个词,请给出思想,给出时间复杂度分析。
- 13、 寻找热门查询:搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录,这些查询 串的重复读比较高,虽然总数是1千万,但是如果去除重复和,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就越热门。请你统计最热门 的10个查询串,要求使用的内存不能超过1G。
(1) 请描述你解决这个问题的思路;
(2) 请给出主要的处理流程,算法,以及算法的复杂度。public class TrieST<Value> { private static final int R = 256; // extended ASCII private Node root; // root of trie private int n; // number of keys in trie // R-way trie node private static class Node { private Object val; private Node[] next = new Node[R]; } /** * Initializes an empty string symbol table. */ public TrieST() { } /** * Returns the value associated with the given key. * @param key the key * @return the value associated with the given key if the key is in the symbol table * and {@code null} if the key is not in the symbol table * @throws NullPointerException if {@code key} is {@code null} */ public Value get(String key) { Node x = get(root, key, 0); if (x == null) return null; return (Value) x.val; } /** * Does this symbol table contain the given key? * @param key the key * @return {@code true} if this symbol table contains {@code key} and * {@code false} otherwise * @throws NullPointerException if {@code key} is {@code null} */ public boolean contains(String key) { return get(key) != null; } private Node get(Node x, String key, int d) { if (x == null) return null; if (d == key.length()) return x; char c = key.charAt(d); return get(x.next[c], key, d+1); } /** * Inserts the key-value pair into the symbol table, overwriting the old value * with the new value if the key is already in the symbol table. * If the value is {@code null}, this effectively deletes the key from the symbol table. * @param key the key * @param val the value * @throws NullPointerException if {@code key} is {@code null} */ public void put(String key, Value val) { if (val == null) delete(key); else root = put(root, key, val, 0); } private Node put(Node x, String key, Value val, int d) { if (x == null) x = new Node(); if (d == key.length()) { if (x.val == null) n++; x.val = val; return x; } char c = key.charAt(d); x.next[c] = put(x.next[c], key, val, d+1); return x; } /** * Returns the number of key-value pairs in this symbol table. * @return the number of key-value pairs in this symbol table */ public int size() { return n; } /** * Is this symbol table empty? * @return {@code true} if this symbol table is empty and {@code false} otherwise */ public boolean isEmpty() { return size() == 0; } /** * Returns all keys in the symbol table as an {@code Iterable}. * To iterate over all of the keys in the symbol table named {@code st}, * use the foreach notation: {@code for (Key key : st.keys())}. * @return all keys in the symbol table as an {@code Iterable} */ public Iterable<String> keys() { return keysWithPrefix(""); } /** * Returns all of the keys in the set that start with {@code prefix}. * @param prefix the prefix * @return all of the keys in the set that start with {@code prefix}, * as an iterable */ public Iterable<String> keysWithPrefix(String prefix) { Queue<String> results = new Queue<String>(); Node x = get(root, prefix, 0); collect(x, new StringBuilder(prefix), results); return results; } private void collect(Node x, StringBuilder prefix, Queue<String> results) { if (x == null) return; if (x.val != null) results.enqueue(prefix.toString()); for (char c = 0; c < R; c++) { prefix.append(c); collect(x.next[c], prefix, results); prefix.deleteCharAt(prefix.length() - 1); } } /** * Returns all of the keys in the symbol table that match {@code pattern}, * where . symbol is treated as a wildcard character. * @param pattern the pattern * @return all of the keys in the symbol table that match {@code pattern}, * as an iterable, where . is treated as a wildcard character. */ public Iterable<String> keysThatMatch(String pattern) { Queue<String> results = new Queue<String>(); collect(root, new StringBuilder(), pattern, results); return results; } private void collect(Node x, StringBuilder prefix, String pattern, Queue<String> results) { if (x == null) return; int d = prefix.length(); if (d == pattern.length() && x.val != null) results.enqueue(prefix.toString()); if (d == pattern.length()) return; char c = pattern.charAt(d); if (c == ‘.‘) { for (char ch = 0; ch < R; ch++) { prefix.append(ch); collect(x.next[ch], prefix, pattern, results); prefix.deleteCharAt(prefix.length() - 1); } } else { prefix.append(c); collect(x.next[c], prefix, pattern, results); prefix.deleteCharAt(prefix.length() - 1); } } /** * Returns the string in the symbol table that is the longest prefix of {@code query}, * or {@code null}, if no such string. * @param query the query string * @return the string in the symbol table that is the longest prefix of {@code query}, * or {@code null} if no such string * @throws NullPointerException if {@code query} is {@code null} */ public String longestPrefixOf(String query) { int length = longestPrefixOf(root, query, 0, -1); if (length == -1) return null; else return query.substring(0, length); } // returns the length of the longest string key in the subtrie // rooted at x that is a prefix of the query string, // assuming the first d character match and we have already // found a prefix match of given length (-1 if no such match) private int longestPrefixOf(Node x, String query, int d, int length) { if (x == null) return length; if (x.val != null) length = d; if (d == query.length()) return length; char c = query.charAt(d); return longestPrefixOf(x.next[c], query, d+1, length); } /** * Removes the key from the set if the key is present. * @param key the key * @throws NullPointerException if {@code key} is {@code null} */ public void delete(String key) { root = delete(root, key, 0); } private Node delete(Node x, String key, int d) { if (x == null) return null; if (d == key.length()) { if (x.val != null) n--; x.val = null; } else { char c = key.charAt(d); x.next[c] = delete(x.next[c], key, d+1); } // remove subtrie rooted at x if it is completely empty if (x.val != null) return x; for (int c = 0; c < R; c++) if (x.next[c] != null) return x; return null; }}
Trie树
声明:以上内容来自用户投稿及互联网公开渠道收集整理发布,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任,若内容有误或涉及侵权可进行投诉: 投诉/举报 工作人员会在5个工作日内联系你,一经查实,本站将立刻删除涉嫌侵权内容。